Overview
Our project aims at reconstructing 3D point clouds of Pokemon models given the 2D images taken from multiple viewpoints. This project is challenging because there is no literature targeting at reconstructing point clouds considering multiple views. PointSetNet [1] does consider the problem of reconstructing point clouds with only single view, which may work fine with certain dataset, such as ShapeNet, because the furniture objects usually possess piecewise smoothness and symmetry. However, when considering to reconstruct Pokemon models, which usually have detailed local surface structures and are deformable, including multiple views will become critical. For example, using single front view of a sofa object may be able to successfully reconstruct its 3D point cloud as its back side is a plain surface while using only single front view of a Pikachu object would be impossible to reconstruct its tail in 3D point cloud. Another recent work, 3D-R2N2 [2], considers to use multiple views by adopting LSTM. However, it targets at reconstructing the voxel occcupancy grid, rather than point clouds, which is much coarser and lossing detailed surface structures.
In this project, we aim at reconstructing 3D point clouds based on multiple 2D views, which is challenging because of high dimensionality of point clouds. In terms of our approach, we first adopt the pretrained models in [1][2] and fine tune on our Pokemon dataset, which shows restrcited performance due to the issues discussed above. Therefore, we propose three novel architechtures to tackle the challenging point cloud reconstruction with multiple views. The first framework we propose is combining PointSetNet with multi-view pooling layers (MVPNet). The second and third framework we propose is adopting LSTM between encoder and decoder layers (MuSullyNet) to handle multiple views via the selective updating advantage of LSTM. The resulted training and testing samples generated with each architecture are presented below, together with the discussions. The results using our proposed architecture with utilizing LSTM components significantly outperforms those by fine tuning with PointSetNet, especially on unseen testing samples, which demonstrates that our proposed models can truly leverage and aggregate the information in all the 2D views and reconstruct each 3D object in fairly good quality. We also discuss the meaning and impact of including the output and hidden states of LSTM in predictor based on the experimental results. Finally, we expect our proposed method to be able to achieve better performance on the conventional dataset, such as ShapeNet, compared to PointSetNet, since our method is designed and demonstrated working well on a even more challenging dataset including deformable, asymmetrical objects with detailed surface patterns.
Previous Work
3D-R2N2

Figure 1: Architecture with 3D convolutional LSTM layer proposed in 3D-R2N2[1].
Architecture: CNN with an encoder, a decoder, and a 3D LSTM layer in between
Loss function: Voxel-wise cross entropy
Input/output: Multiview images/Voxelized 3D object
Limitations: voxelized objects have lower resolutions, so some fine details may be missing.
PointSetGeneration (PointSetNet)

Figure 2: Architecture proposed in PointSetGeneration[2].
Architecture: CNN with an encoder, a decoder, and some fully connected layers at the final stage
Loss function: The Chamfer Distance (CD) between two point sets and of the metric space is defined as
In the loss layer, we compute between our prediction and ground truth .
Input/output: Single view image/Point cloud
Limitations: 1) can only handle single view. 2) the resulting point cloud does not look nice from a side view
Goal
Rendering is a process to generate 2D image from 3D model format (e.g. .fbx, .obj, and .dae) containing vertices and faces. It builds the 3D representation, add color, shading and texture on to it, and trasforms it into image which can be easily visualized by human. Our neural net is trained to learn partial of the inverse transformation of the rendering process. Specifically, our goal is to produce a set of vertices (point cloud) of the Pokemon from multiview images.
Data Preprocessing
We download all the available 1st generation Pokemon 3D models from a public website, preprocess and export .obj files with blender. Then we batch-render the multiview images with 30 equally phase-shifted cameras around Pokemon. (We show those view images of one pokemon below as an example). The ground truth point clouds of Pokemon generated from .obj file are calibrated with rotational matrix in order to match the viewpoint of Pokemon images. The entire training set contains 120 pokemons, each has 30 view images.
In the following sections, we evaluate the results on both training and testing samples. The training samples are selected from the training set. The testing samples are pokemon view images that are not in the training set. Most of the Pokemons are present in both training and testing sets, but with different scaling and rendered with different lighting and camera angle. Few of them only exist in the testing set (e.g. extremely rare Pokemon: Mew) meaning that the neural net won’t see it during training.
Multiview Images
Here are two examples of the rendered images, one in the training set and the other in the testing set.


Ground Truth for Training Samples






Figure 3: Ground truth point cloud of training samples. Left to right, top to bottom: Charmander, Blastoise, Pidgeot, Raticate, Arbok, and Pikachu.
Ground Truth for Testing Samples





Figure 4: Ground truth point cloud of testing samples. Left to right, top to bottom: Pikachu, Farfetch’d, Dewgong, Gengar, Snorlax, and Mew.
Methods
Here, we show our progress step by step, from the simplest (pre-trained networks) to the most refined and complex (PointSetNet with LSTM) approach.
Applying Pre-trained Models
3D-R2N2


Figure 5: Voxel occupancy generated by pre-trained 3D-R2N2. The result is presented by space-occupying cubes which is bad at representing hollow, and thin parts of the object.
We have tested Pokemon images with the 3D-R2N2 model, which takes multiview images as input data and generate a voxelized 3D object. One example result is shown above, where the first five images are input multiview images and the last one is the output object. From this figure we see that the upper part of the object is roughly the same as expected, but there is an unexpected flat plane at the bottom of the object, which does not match what we see in the multiview images.
PointSetGeneration
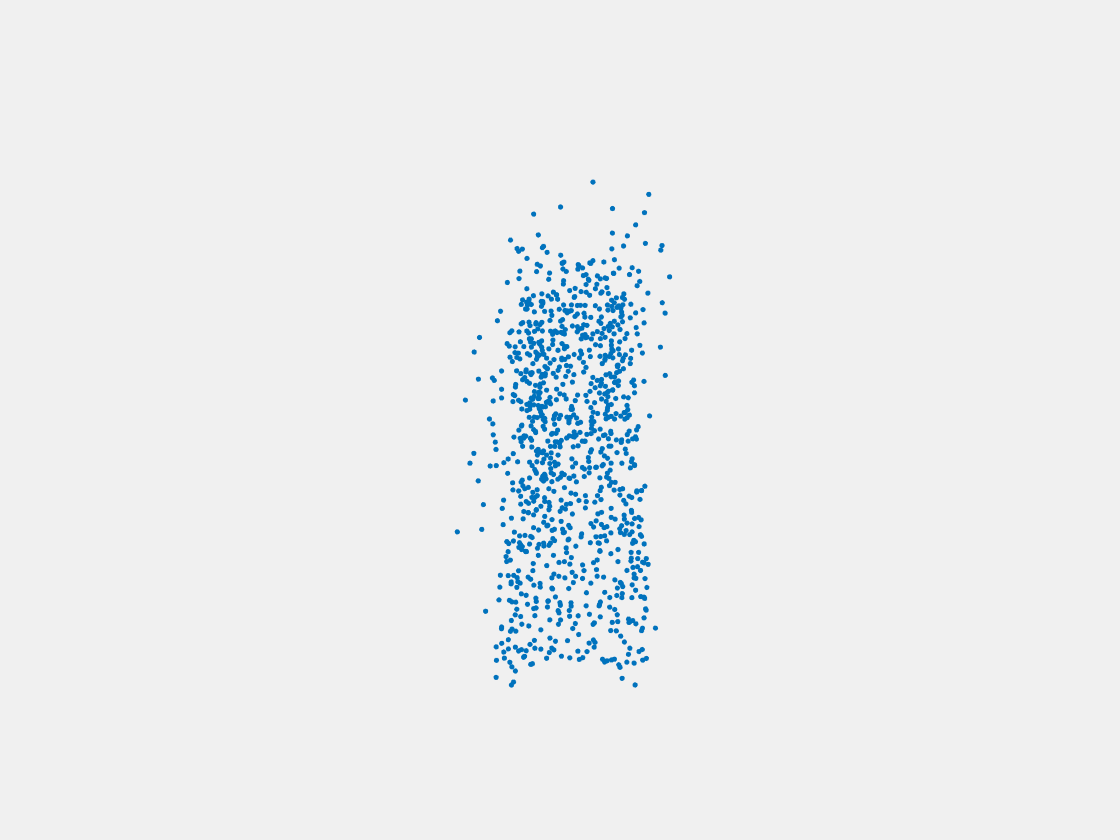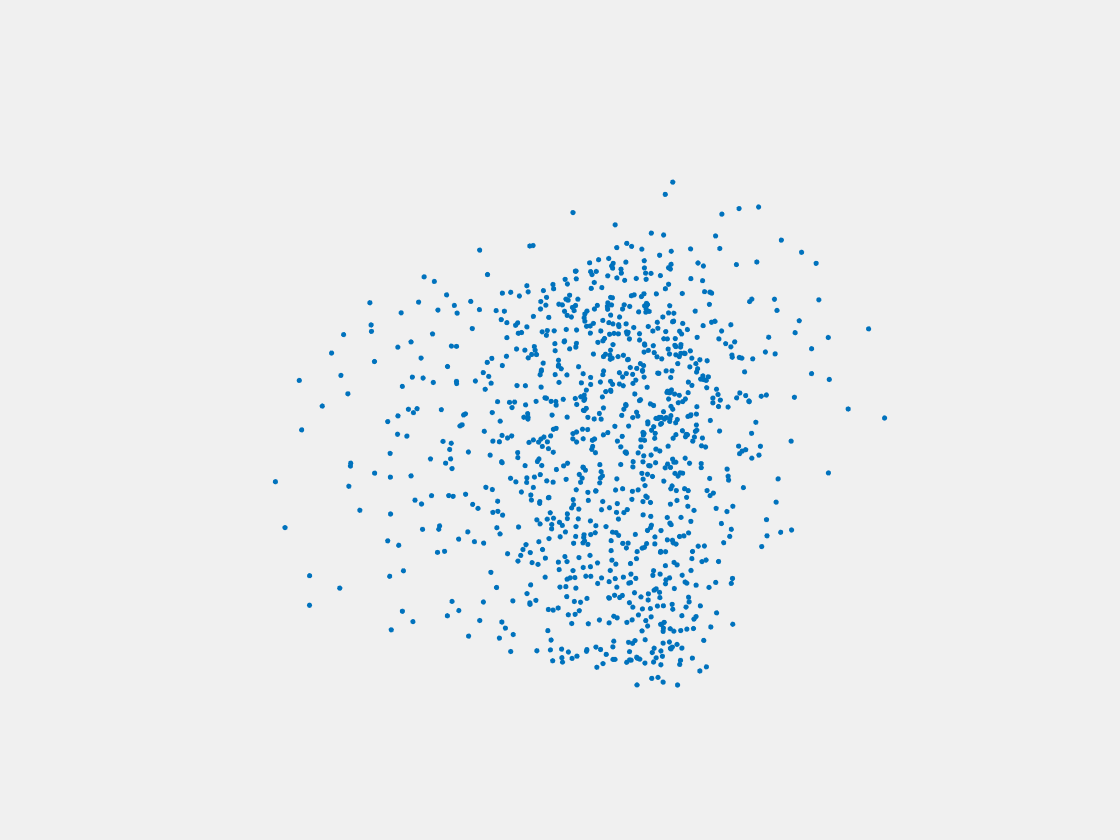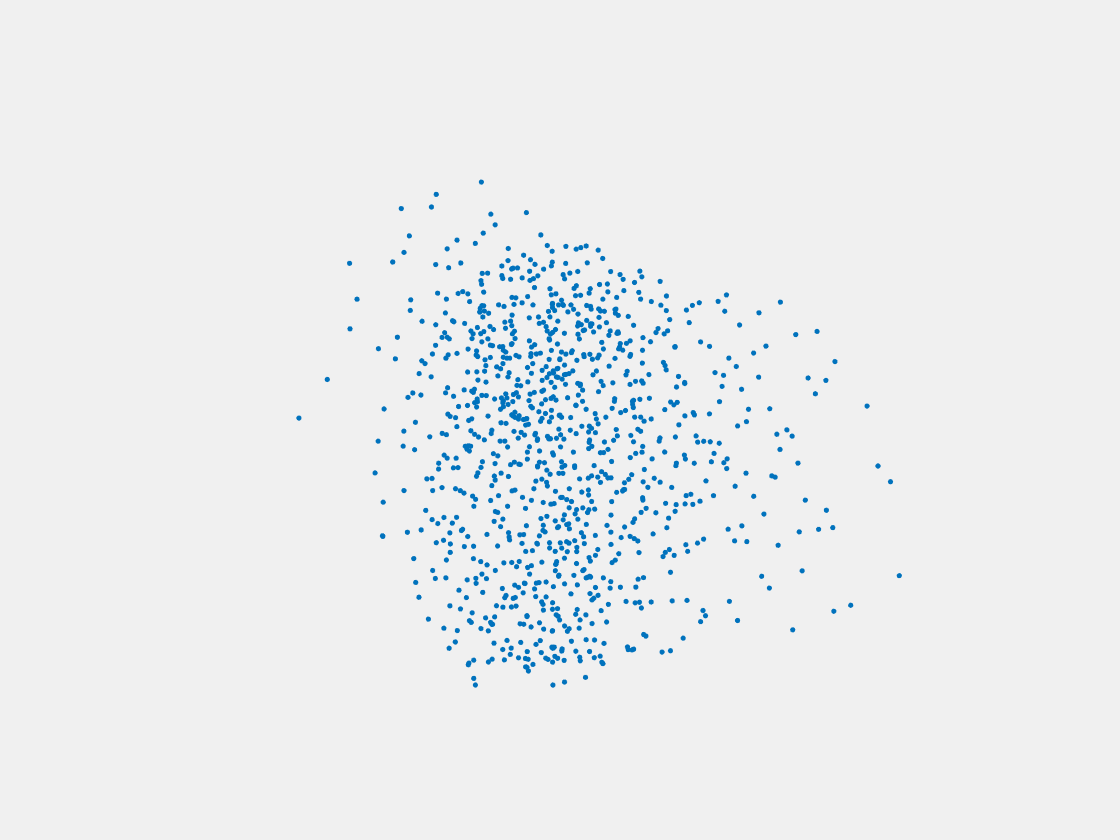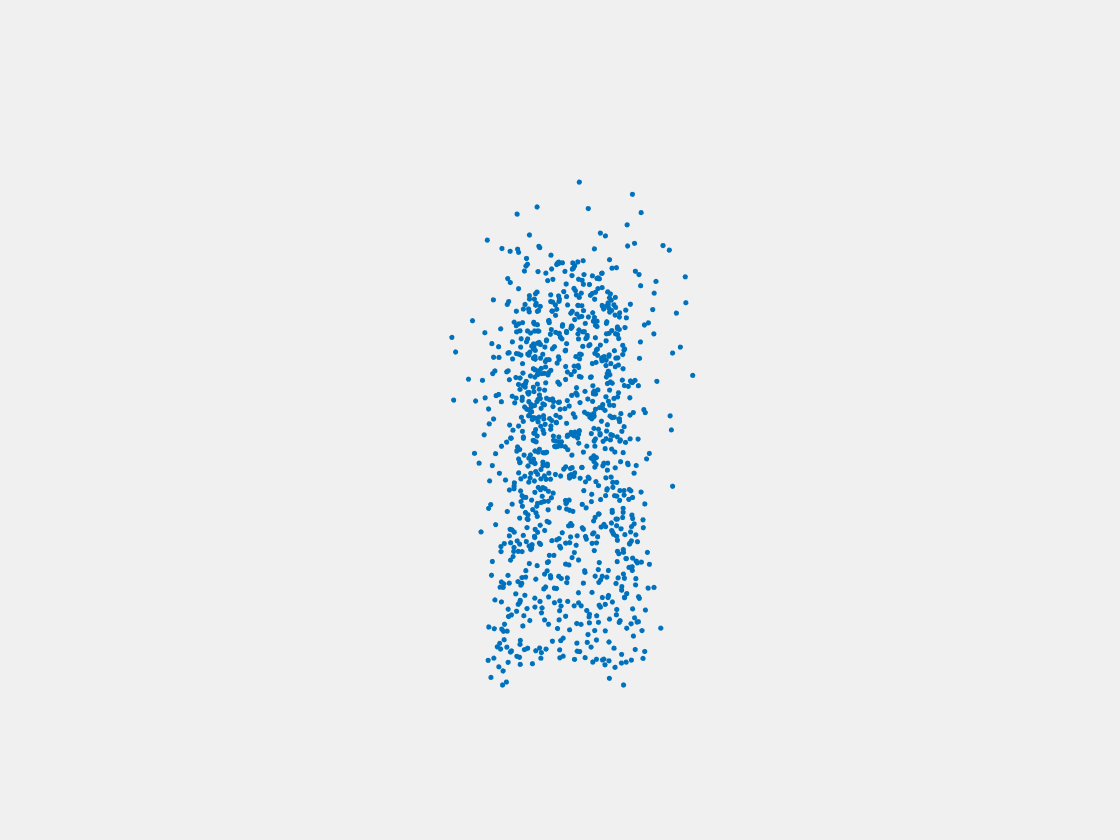
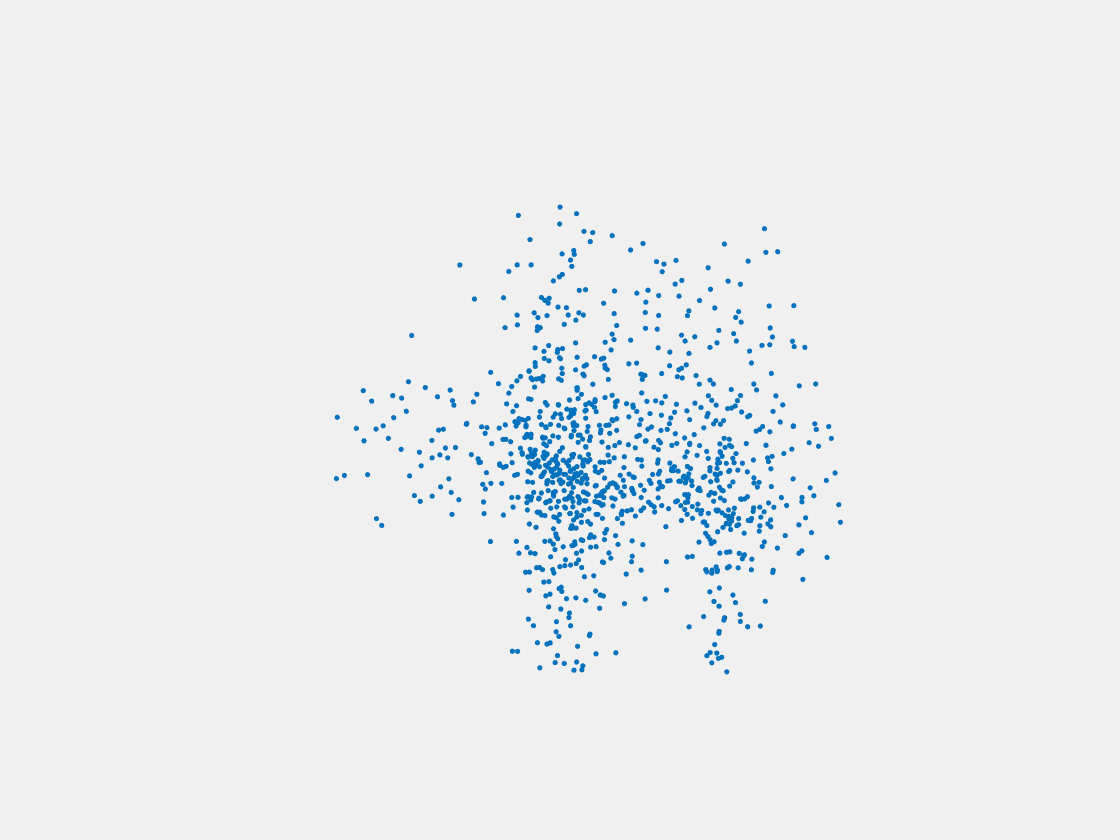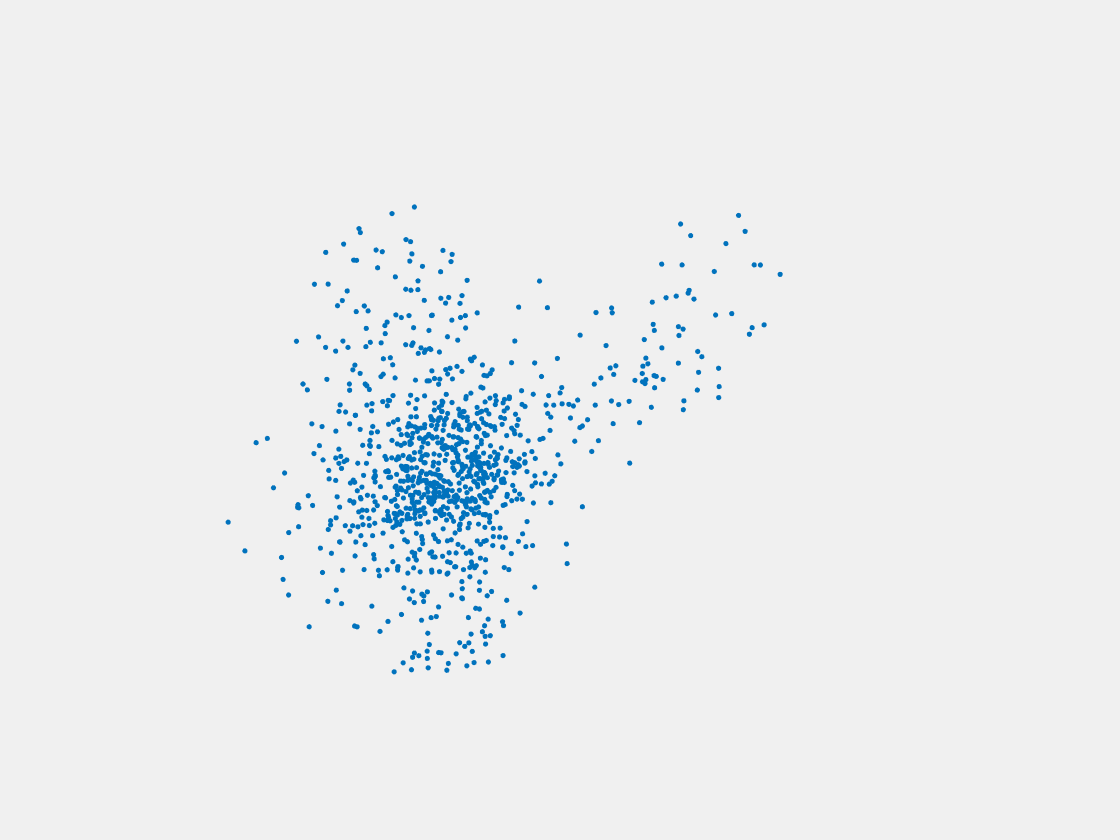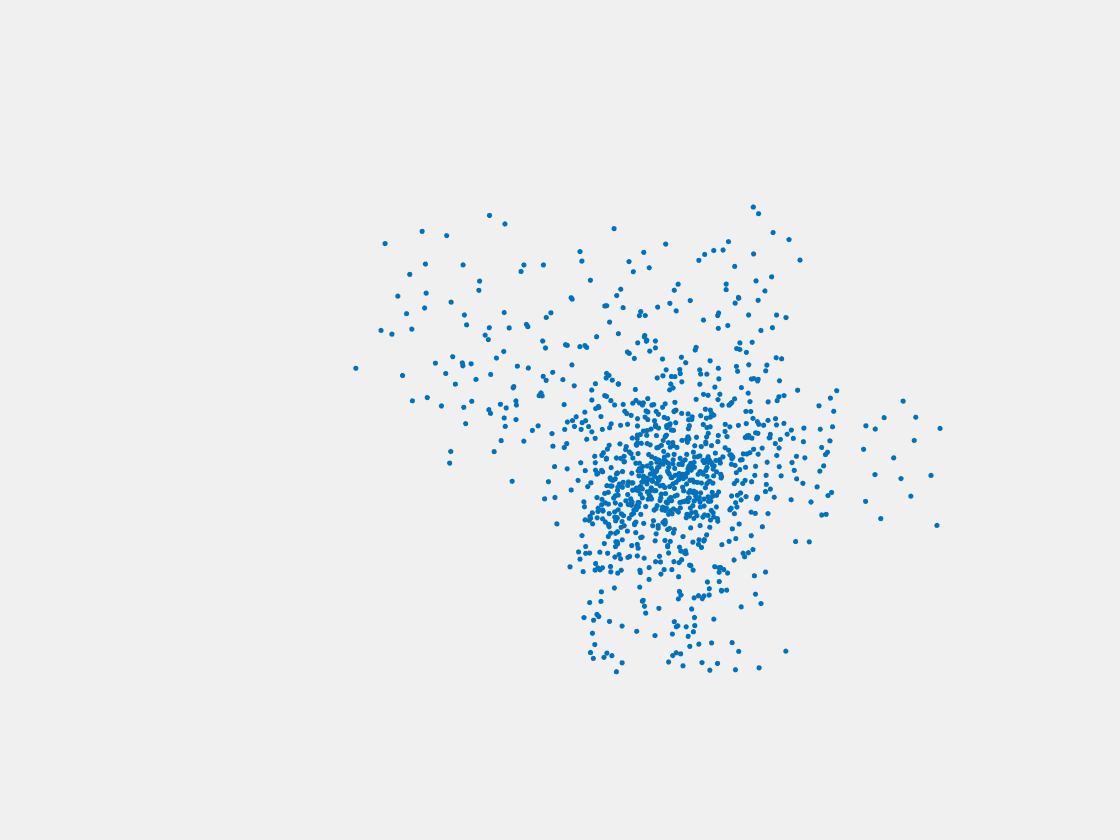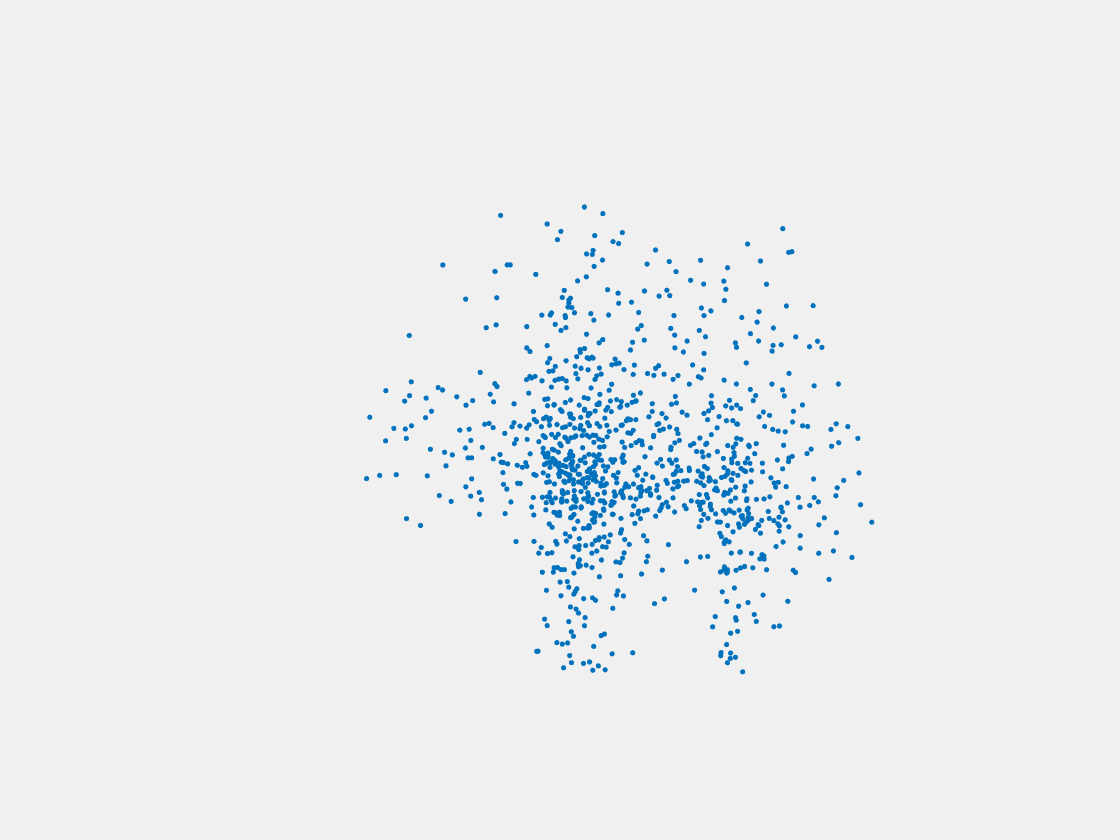
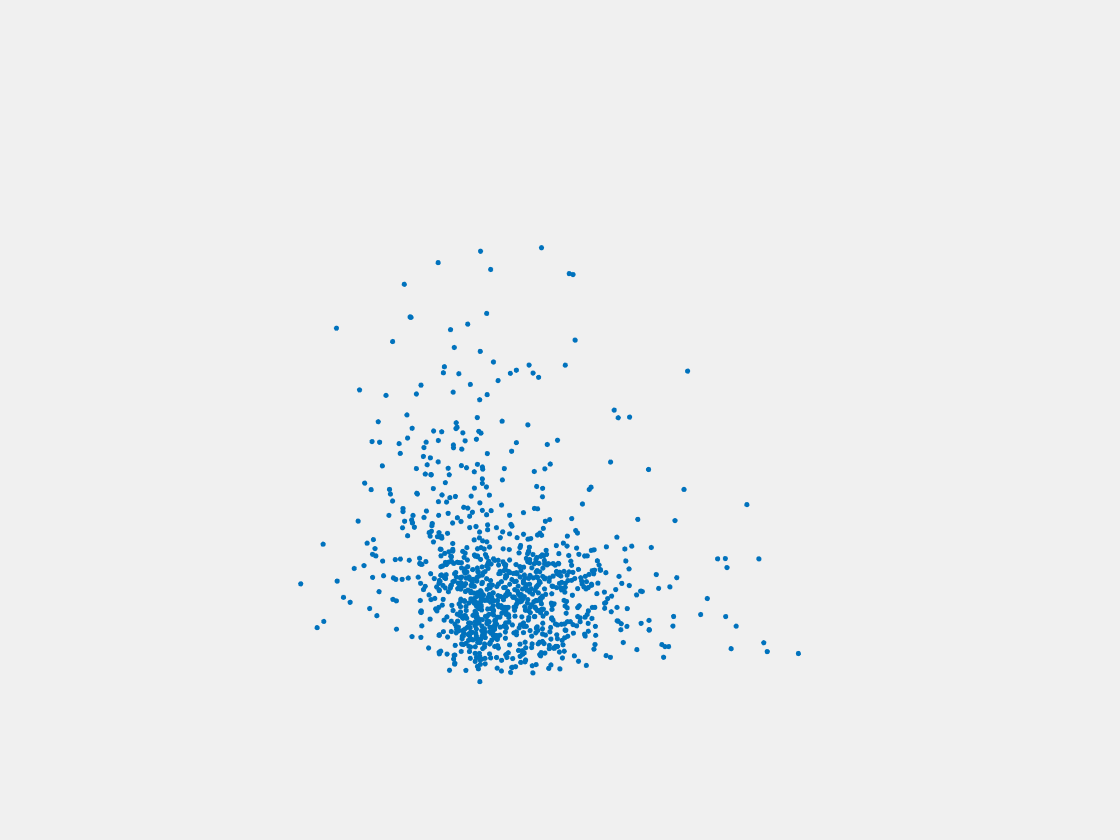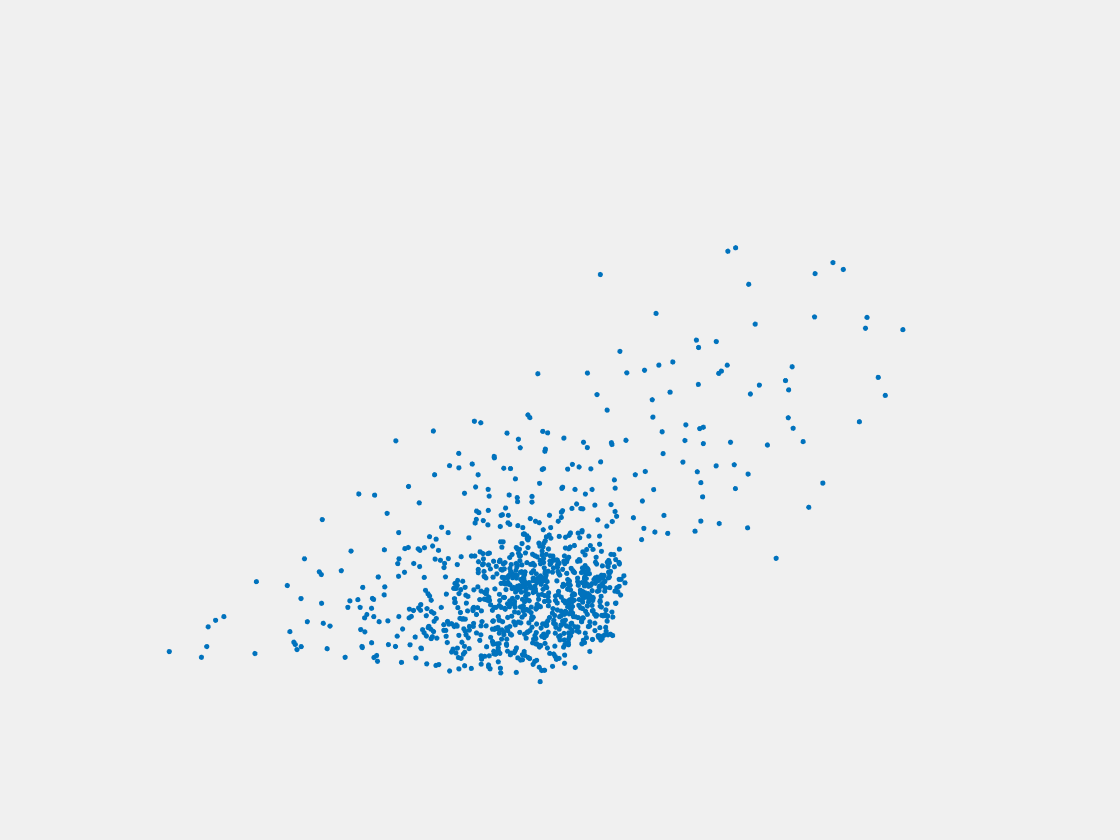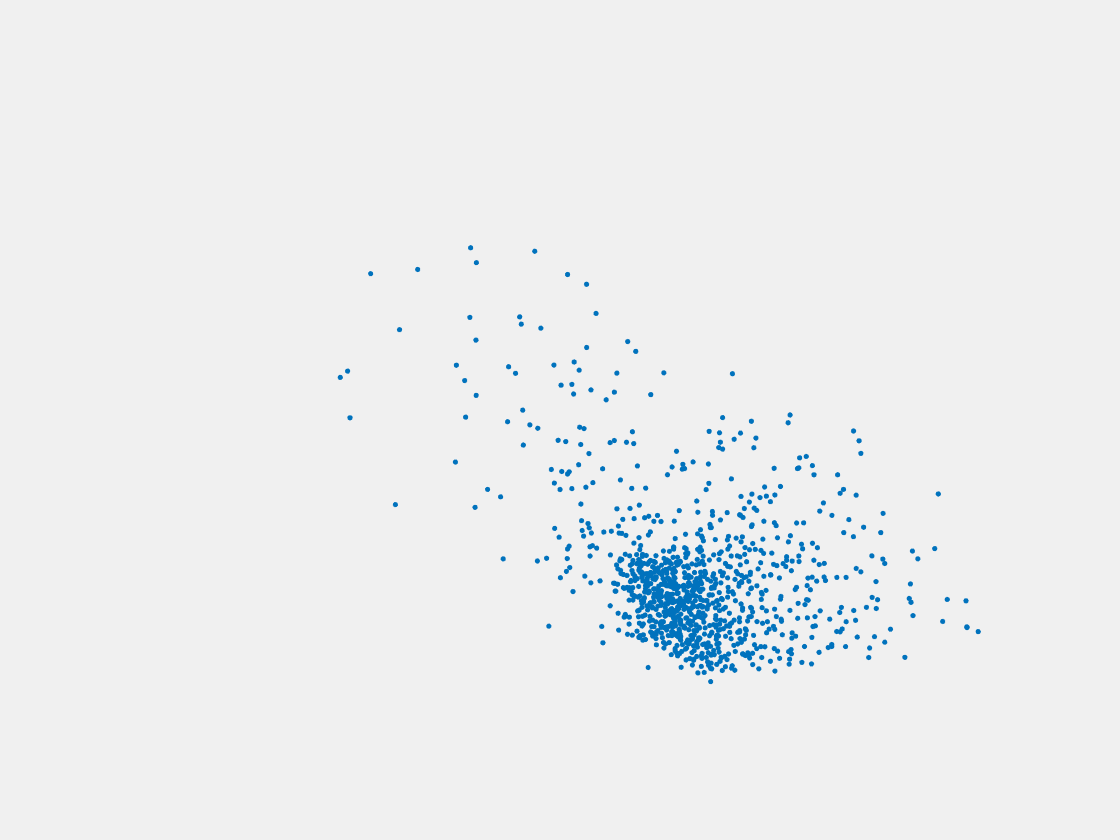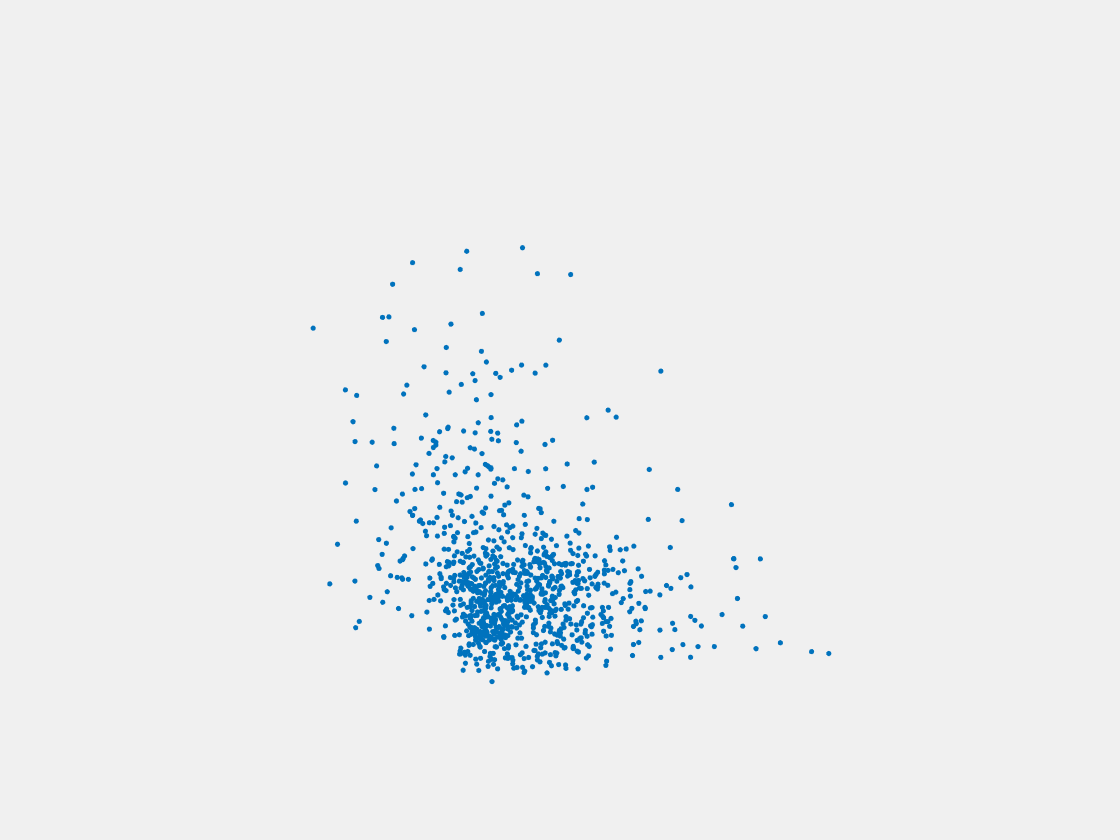


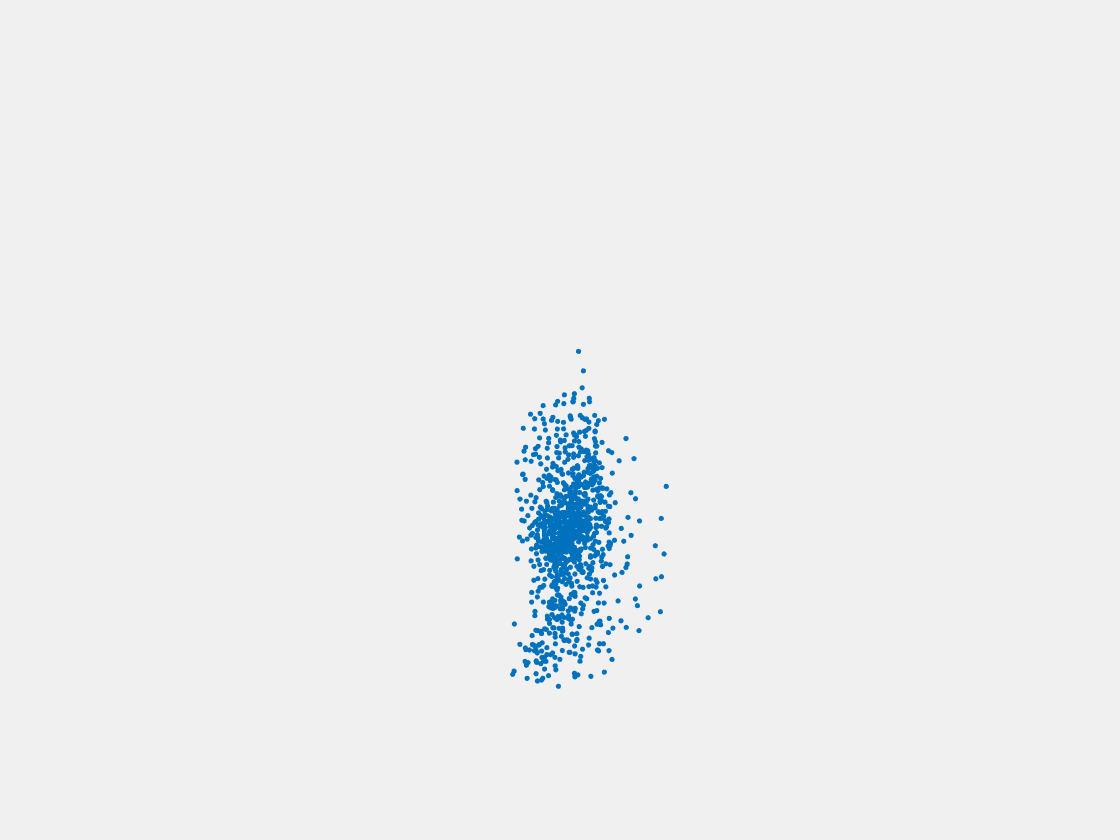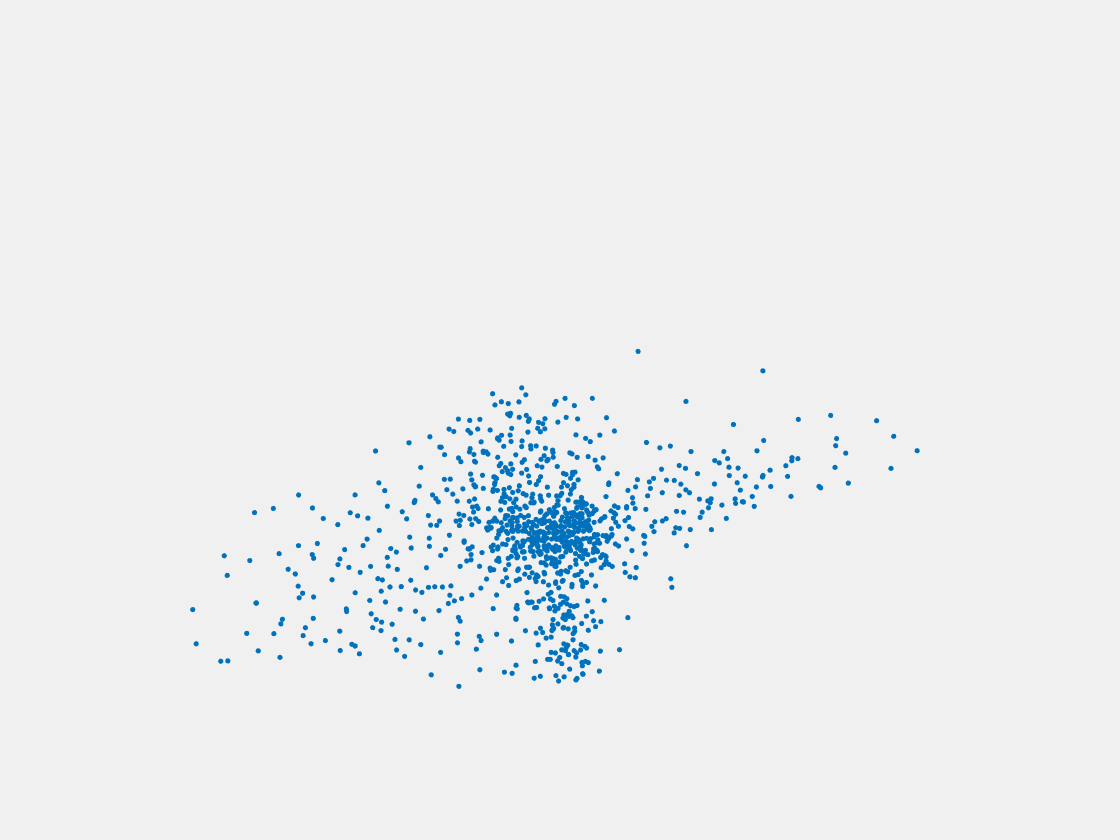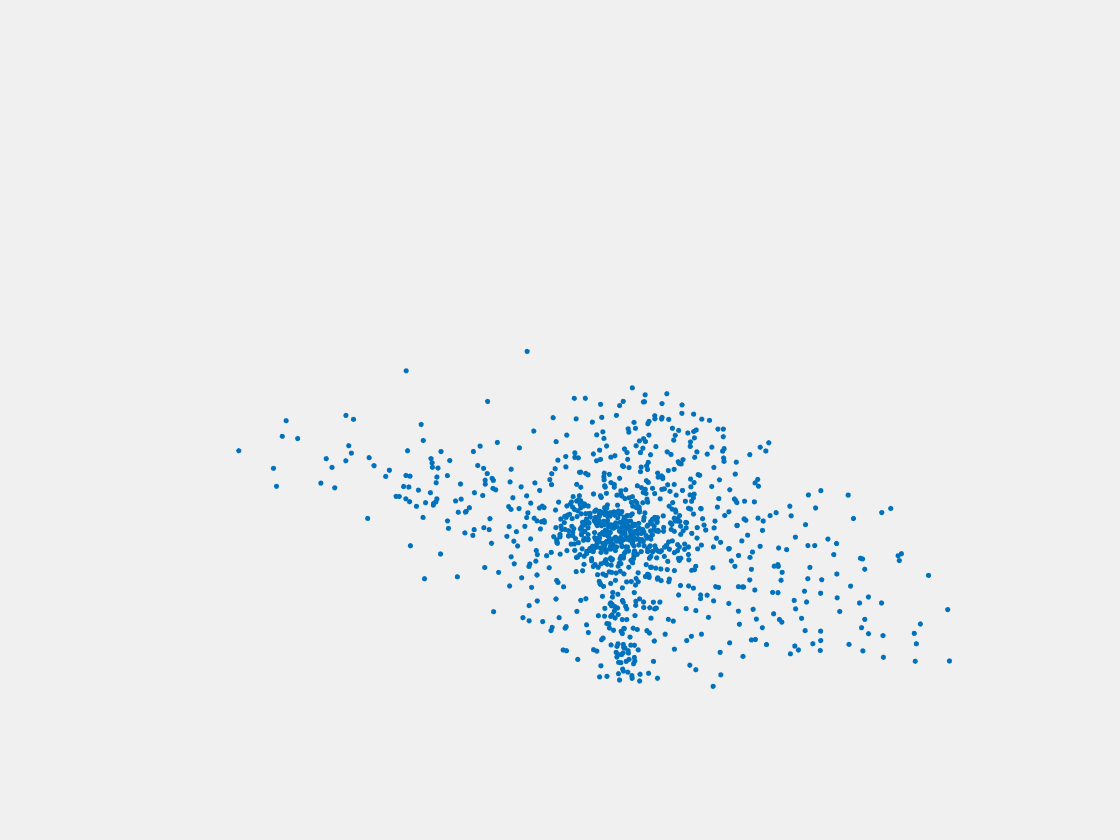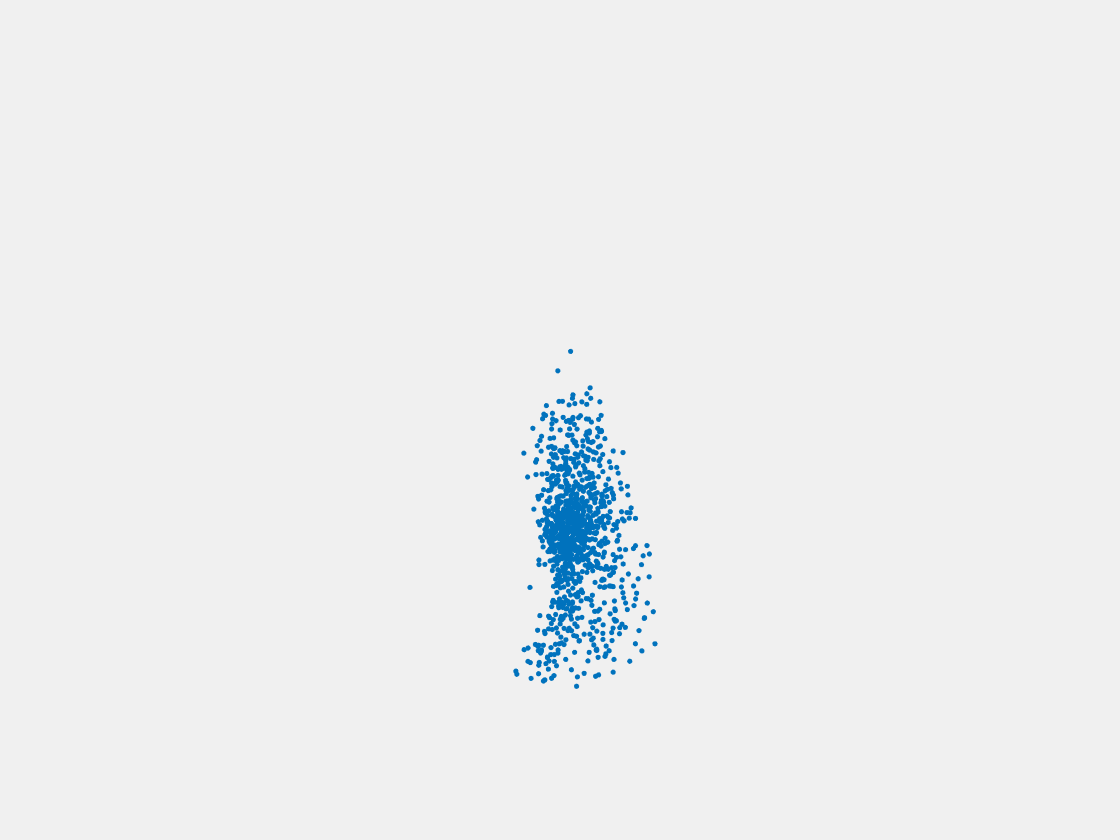
Figure 6: Point clouds generated by pre-trained PointSetNet with testing data. Left to right, top to bottom: Pikachu, Farfetch’d, Dewgong, Gengar, Snorlax, and Mew. Since the PointSetNet is trained on ShapeNet rather than Pokemon data, it is not surprising that the results resemble objects of ShapeNet, e.g. Gengar like a doll and Snorlax like a sofa.
We have also obtained point clouds for some input images using the test code of PointSetGeneration with its pre-trained model. We only show testing samples here because the network was not trained with any pokemon image. We observe some artifacts in the generated point clouds. First, the point clouds look nice in some views, but poor in other view. For example, in the bottom-left of Figure 6, the front view is somewhat similar to that of the ground truth, but the object looks too thin from the side. A probable reason for this is that PointSetNet can only handle a single image as input, but not multiview images. Second, we observe a flat plane in most of the resulting point clouds. For example, in the bottom-middle of Figure 6, the object has a flat bottom plane and looks like a couch. One possible reason for this is that the neural network was trained using rigid objects such as tables, chairs, and cars. Those objects typically have flat planes, so the model trained from those objects does not generalize well to Pokemon images.
From the observations above, we see that 3D-R2N2 and PointSetNet have a common problem that the resulting object typically has a flat part, and a probable reason is that the training samples are too different from the subjects (pokemons) of our interest. Thus, we next try to fine tune the PointSetNet using pokemon images.
Fine-Tuning
PointSetNet Fine-Tuned with Single (Image, Point Cloud) Pair for Each Pokemon
First, we train PointSetNet with single view Pokemon images and their ground truth point clouds. For each pokemon, the information fed into the network for training only includes one view image (mostly side view) and the ground truth point cloud. The pre-trained weights from PointSetNet are used for initialization. We expect the issue with the flat plane to be resolved, since our training samples include pokemon point clouds that do not have flat planes. The results for training and testing samples are shown below. We observe that the model works well in training samples, but poorly for many testing samples. In particular, serious artifacts can be seen when we view the point cloud with a different view angle from that of the only input image.
Training Samples
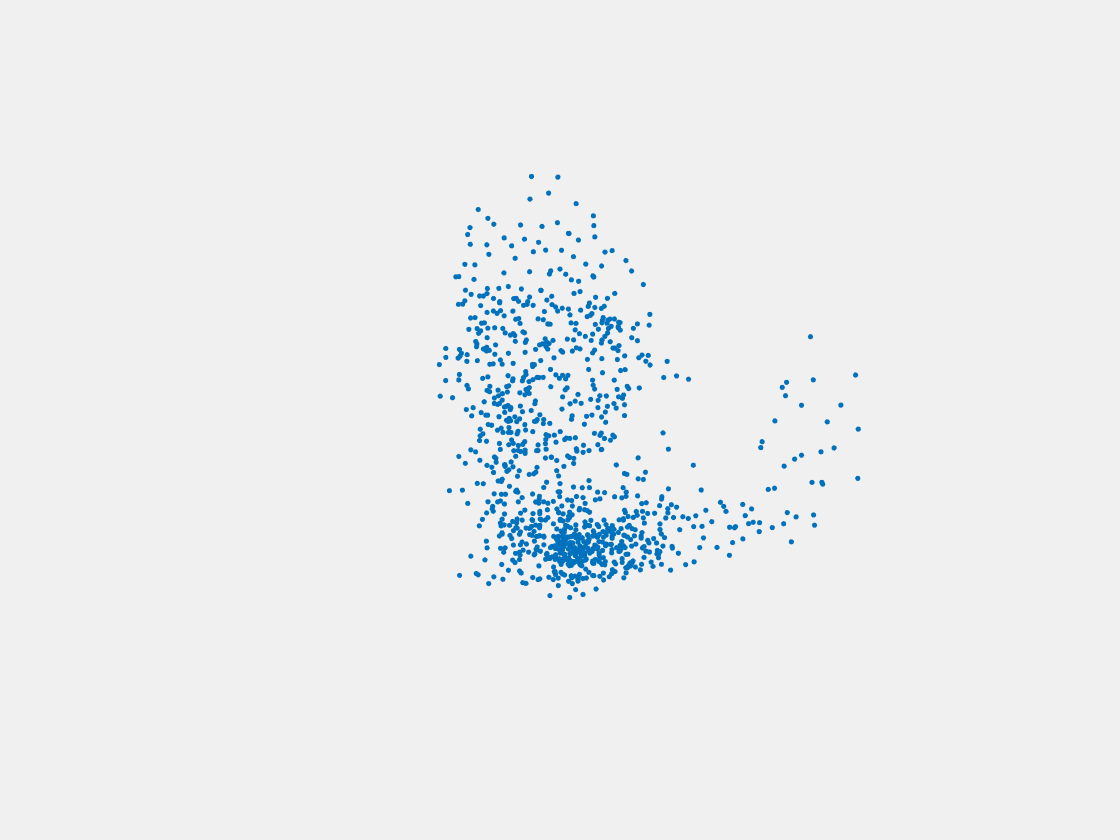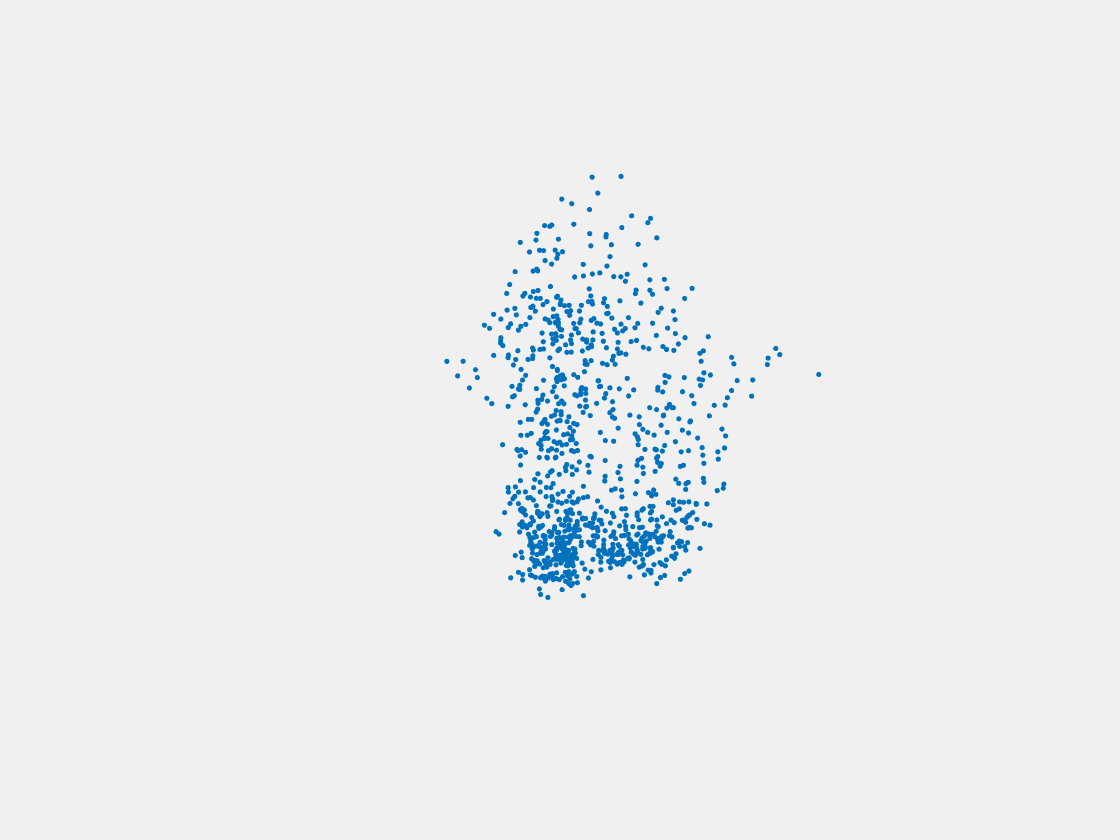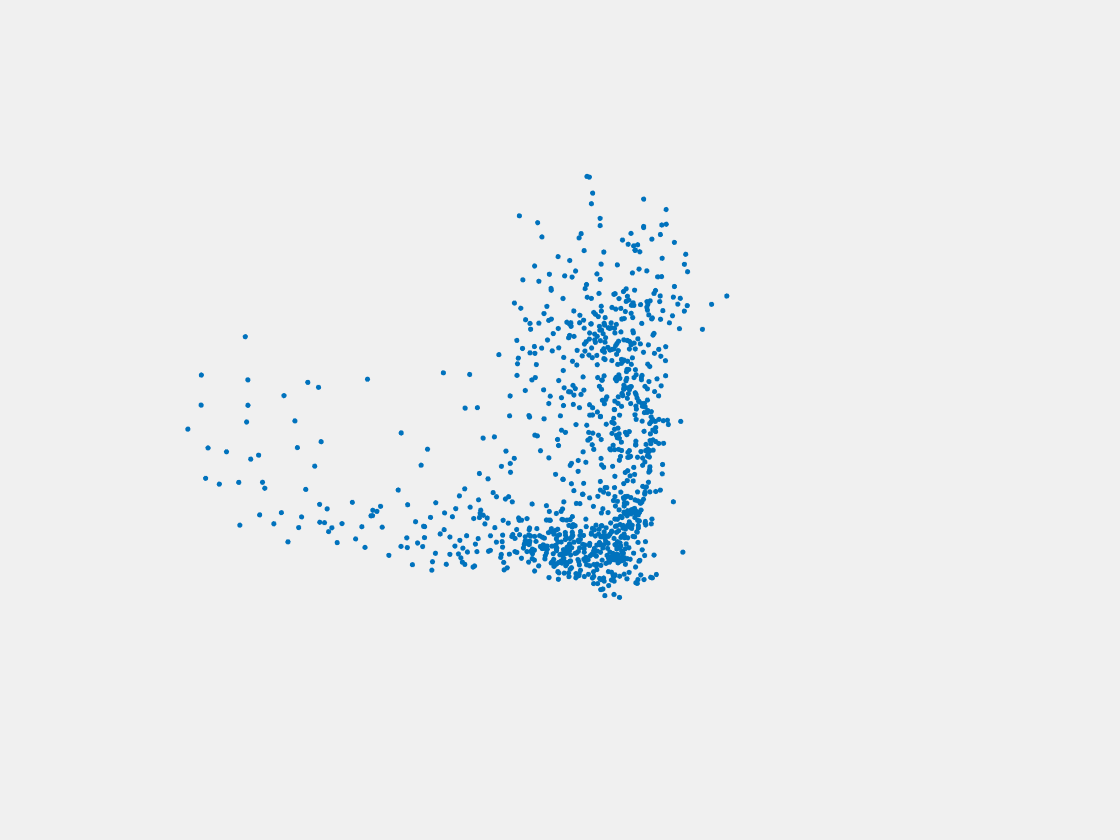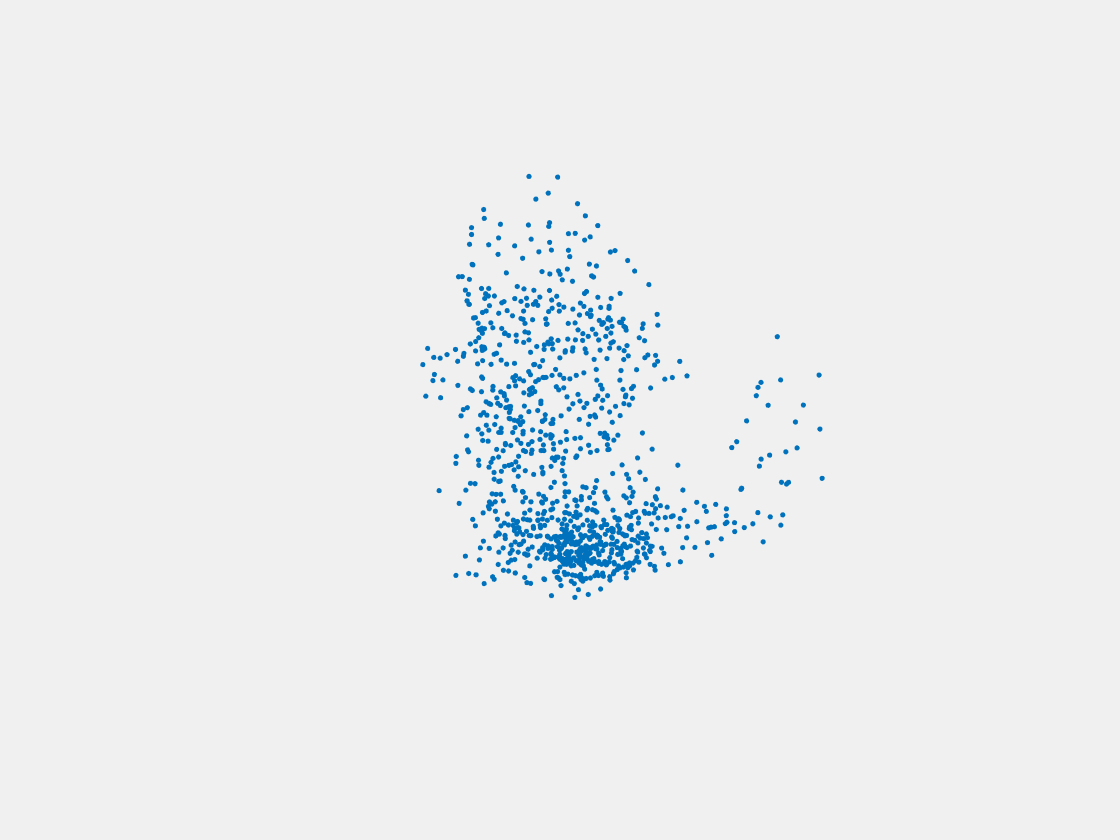
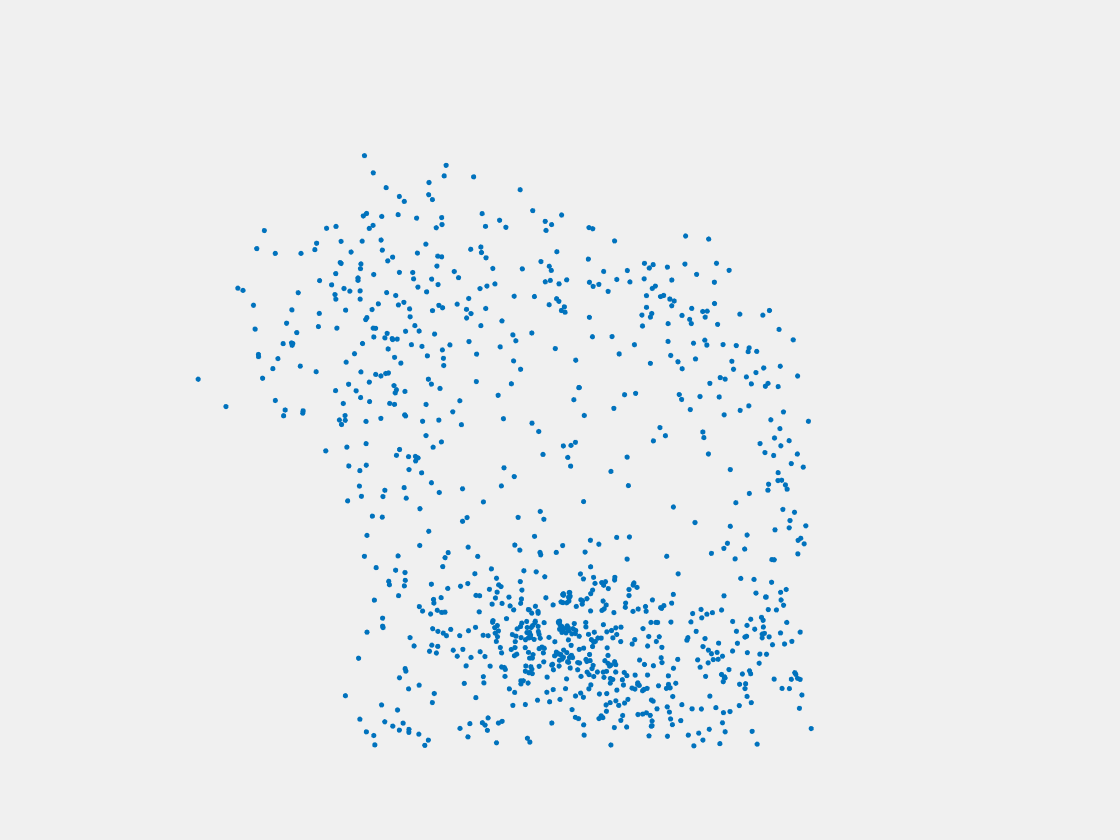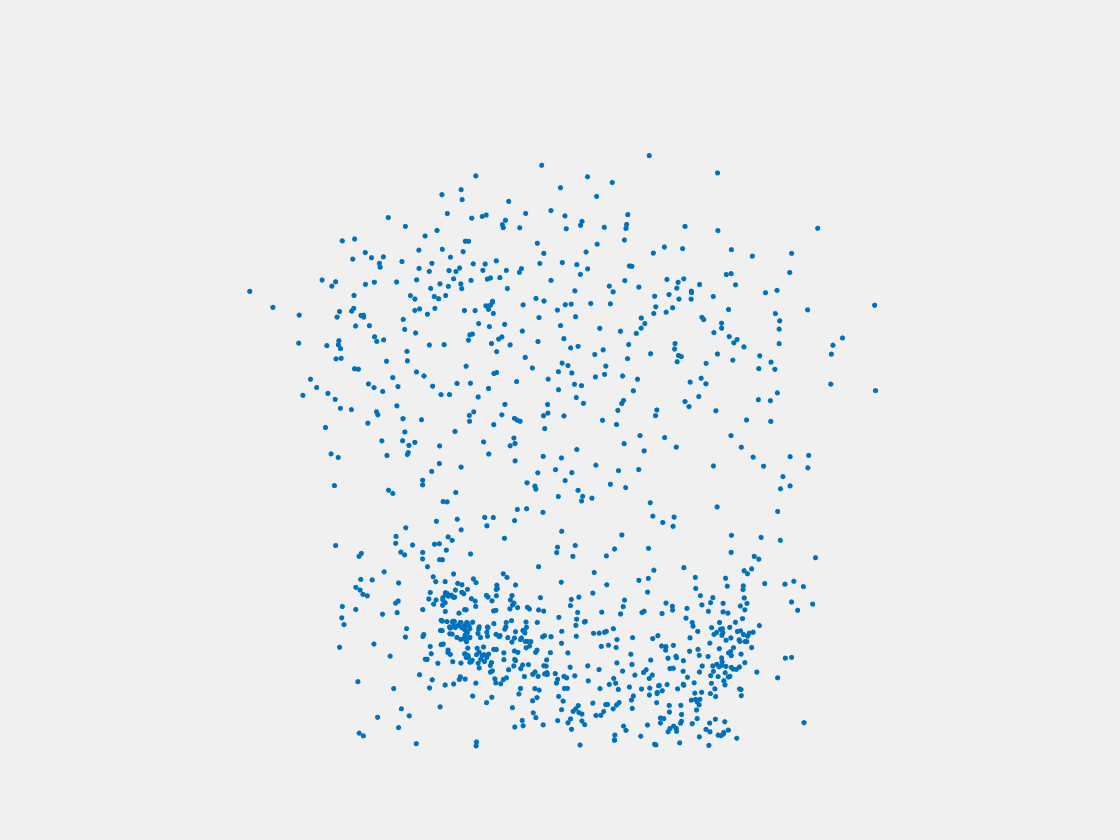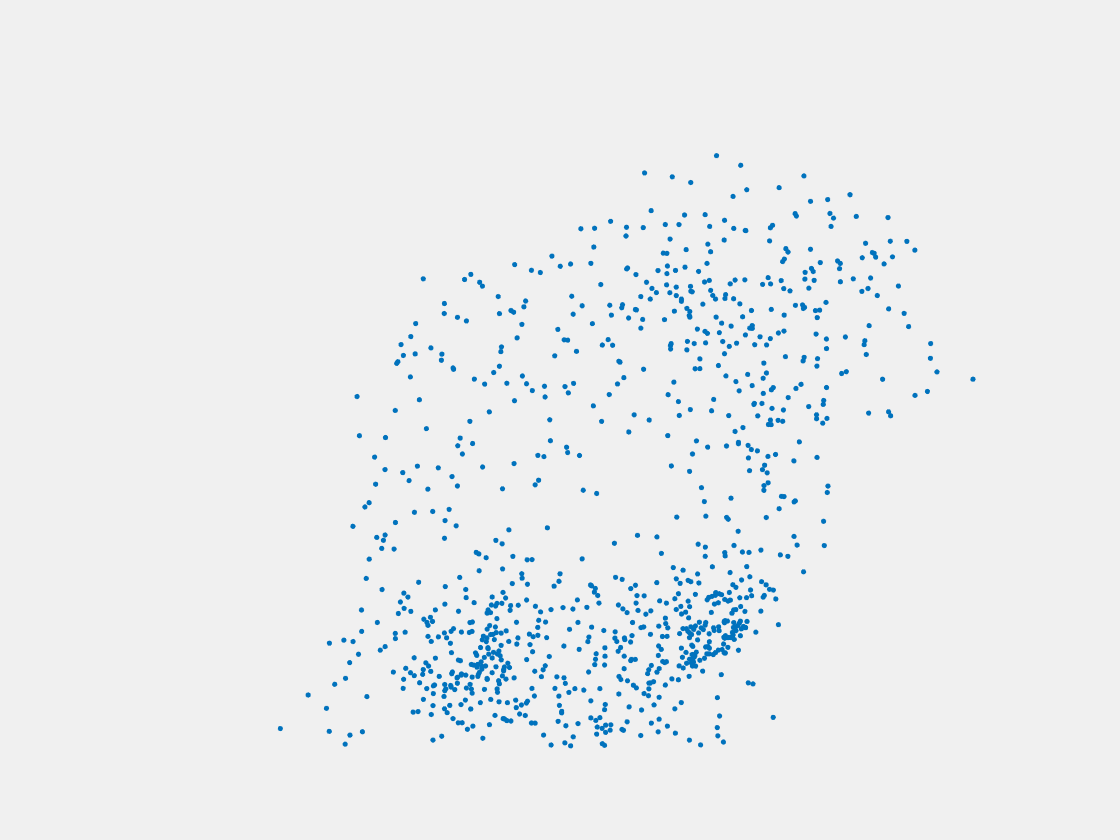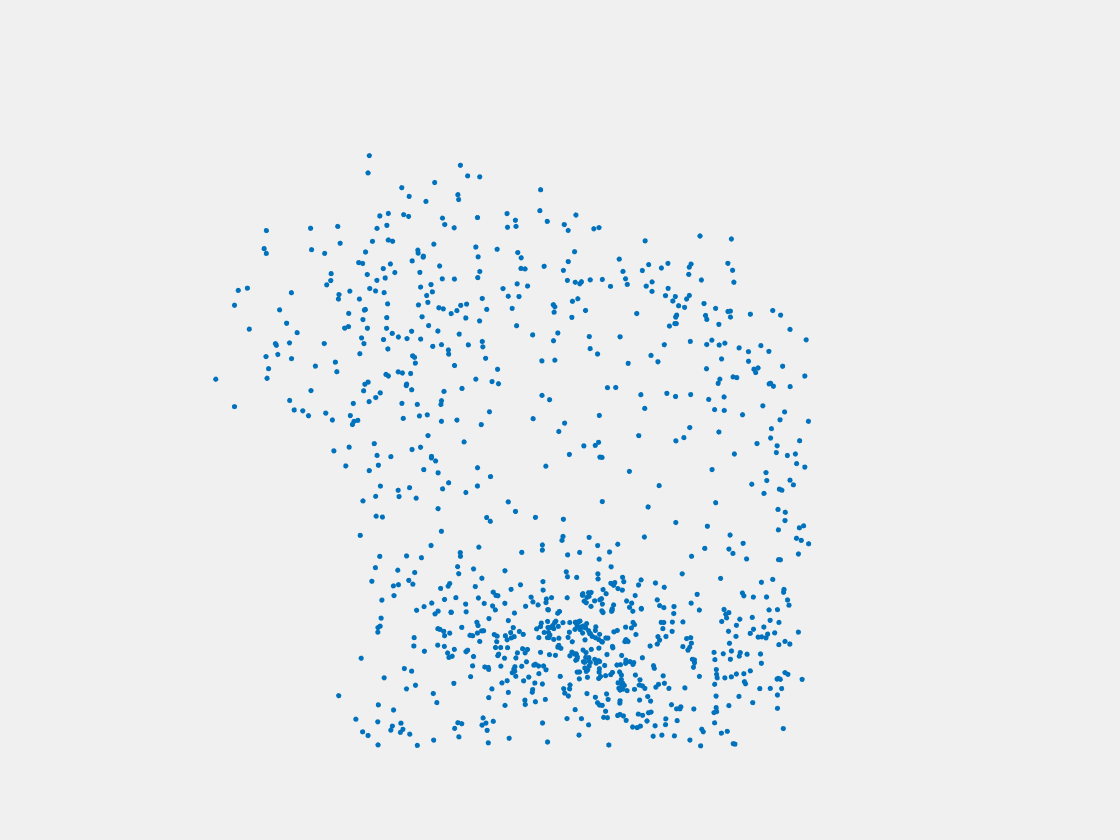


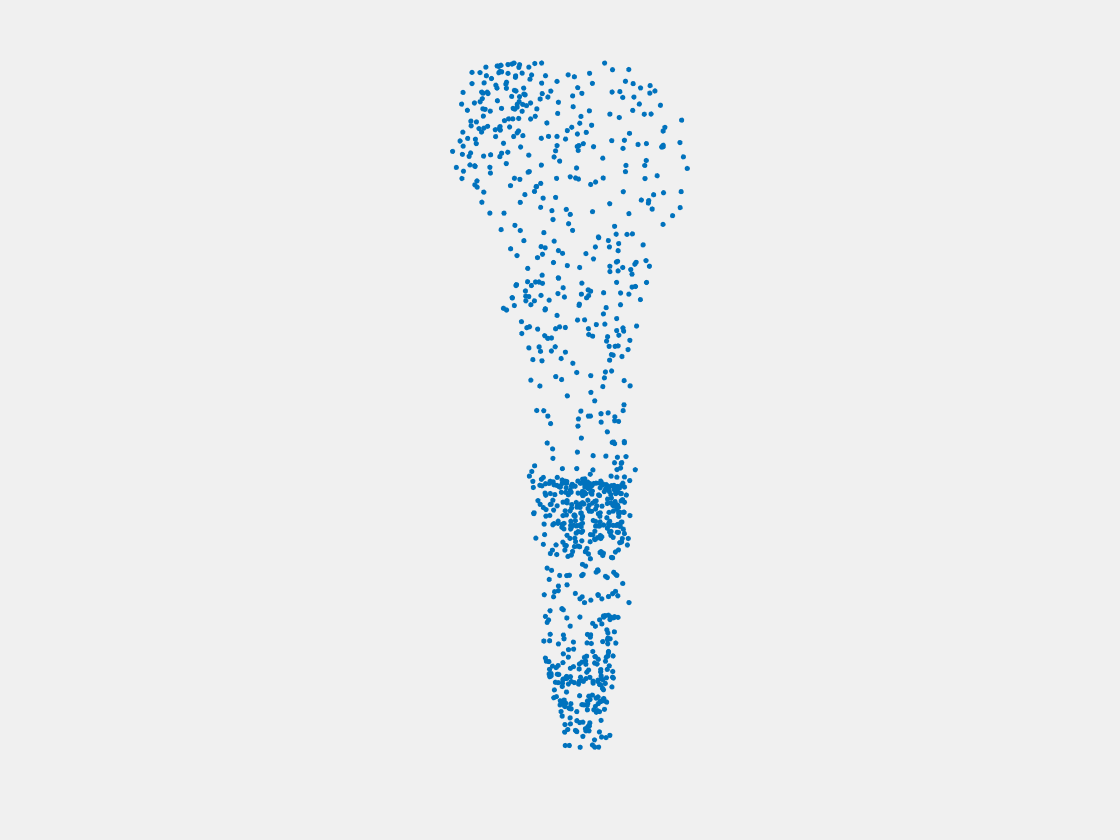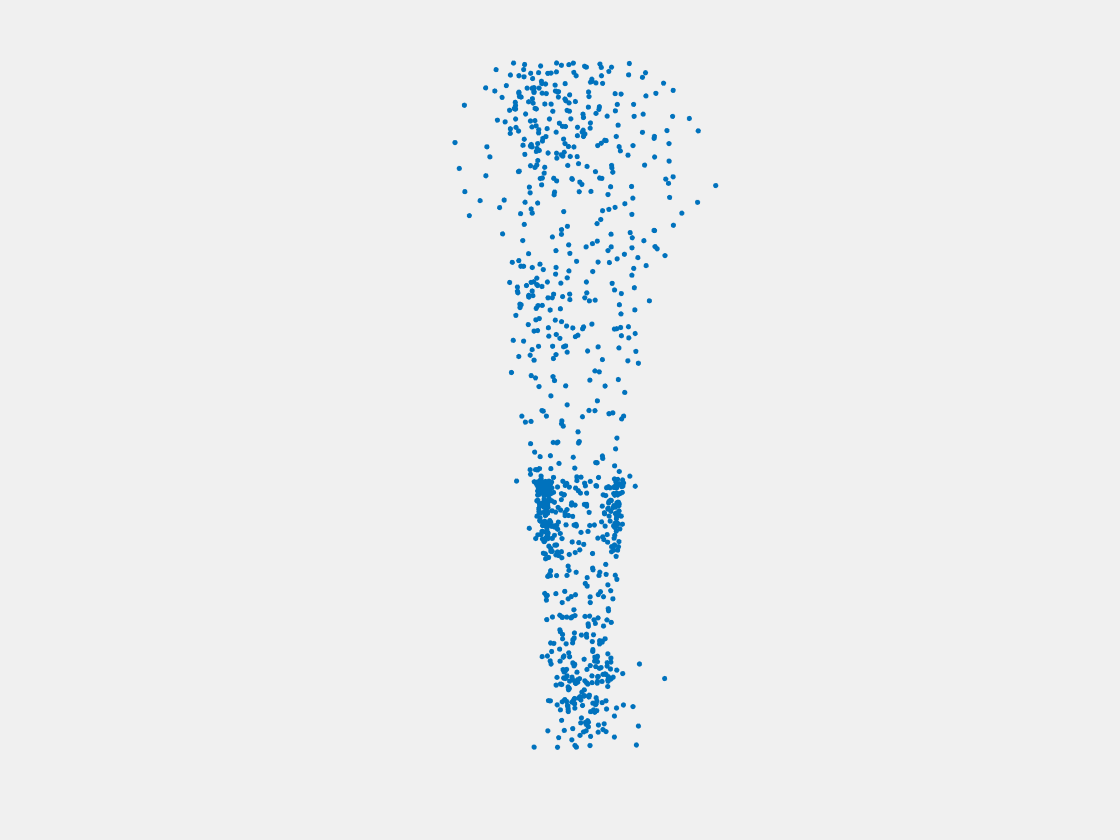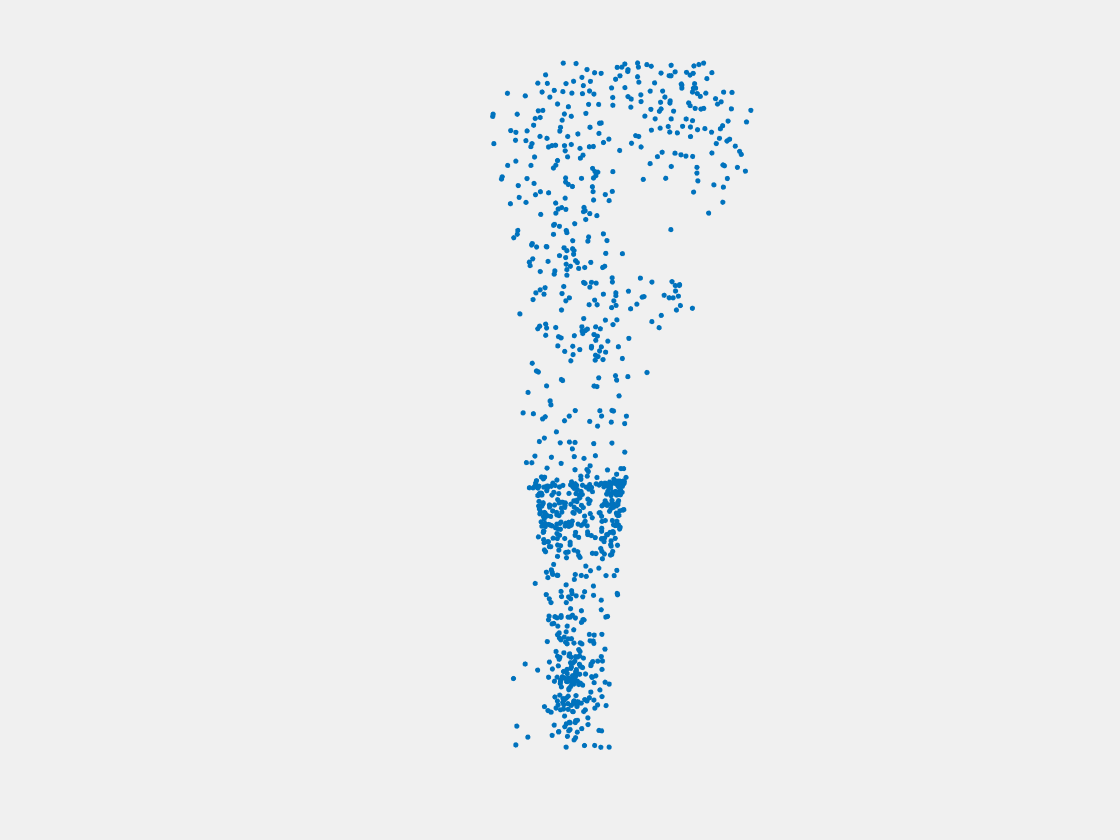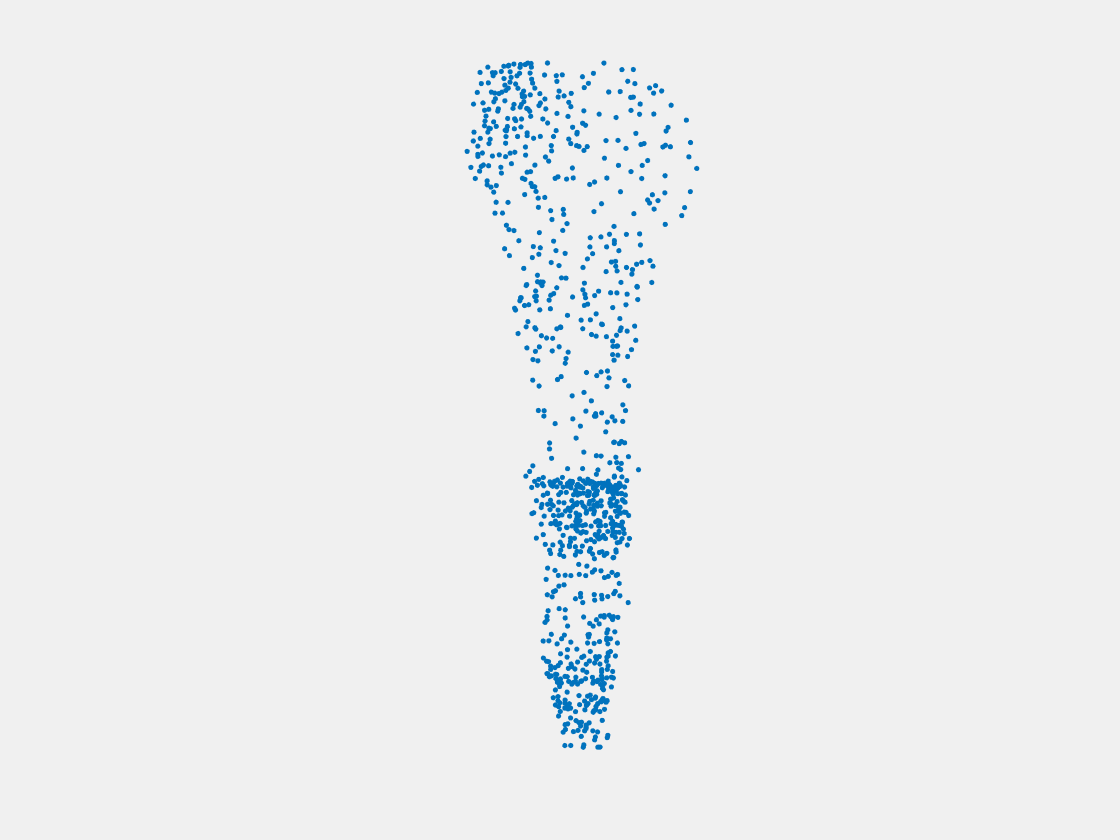
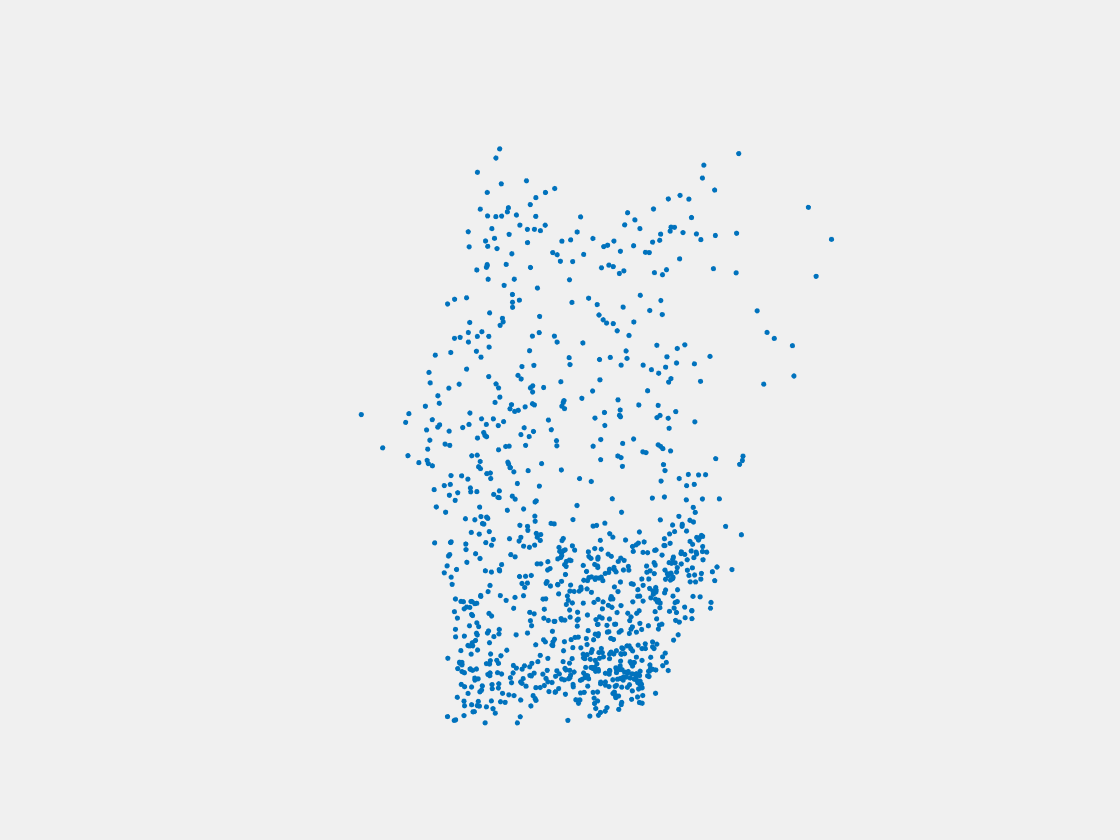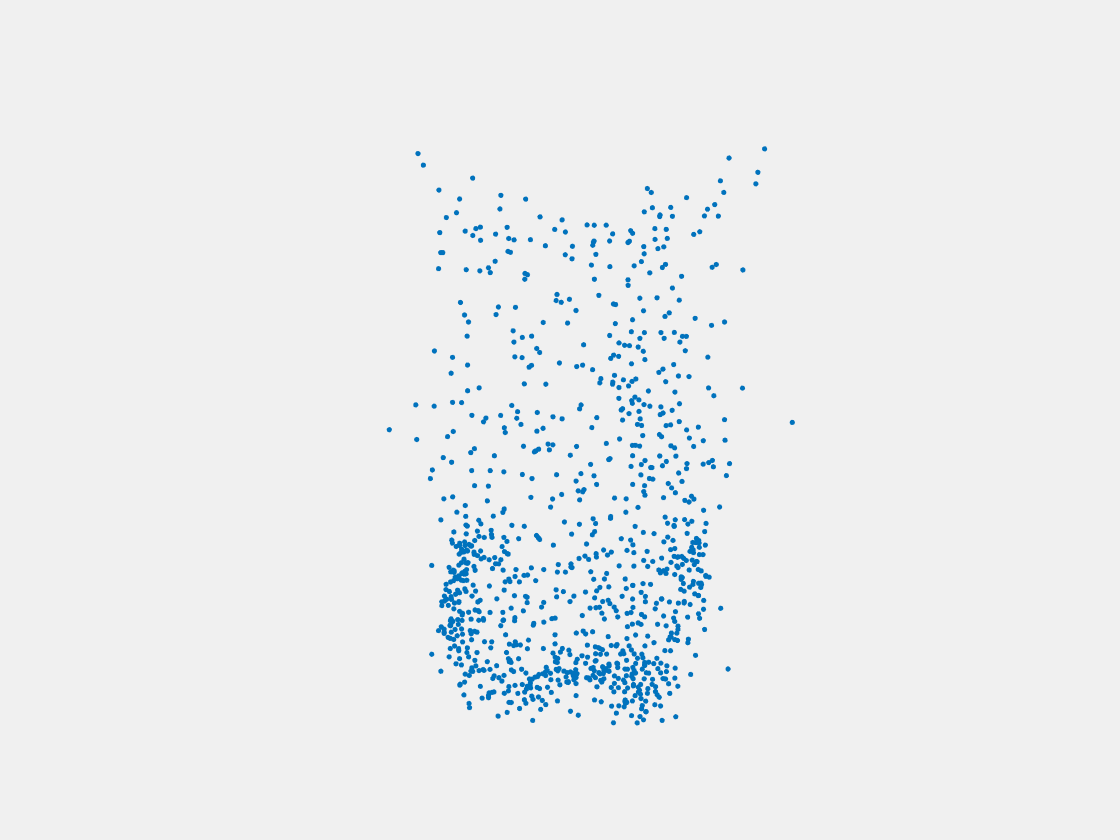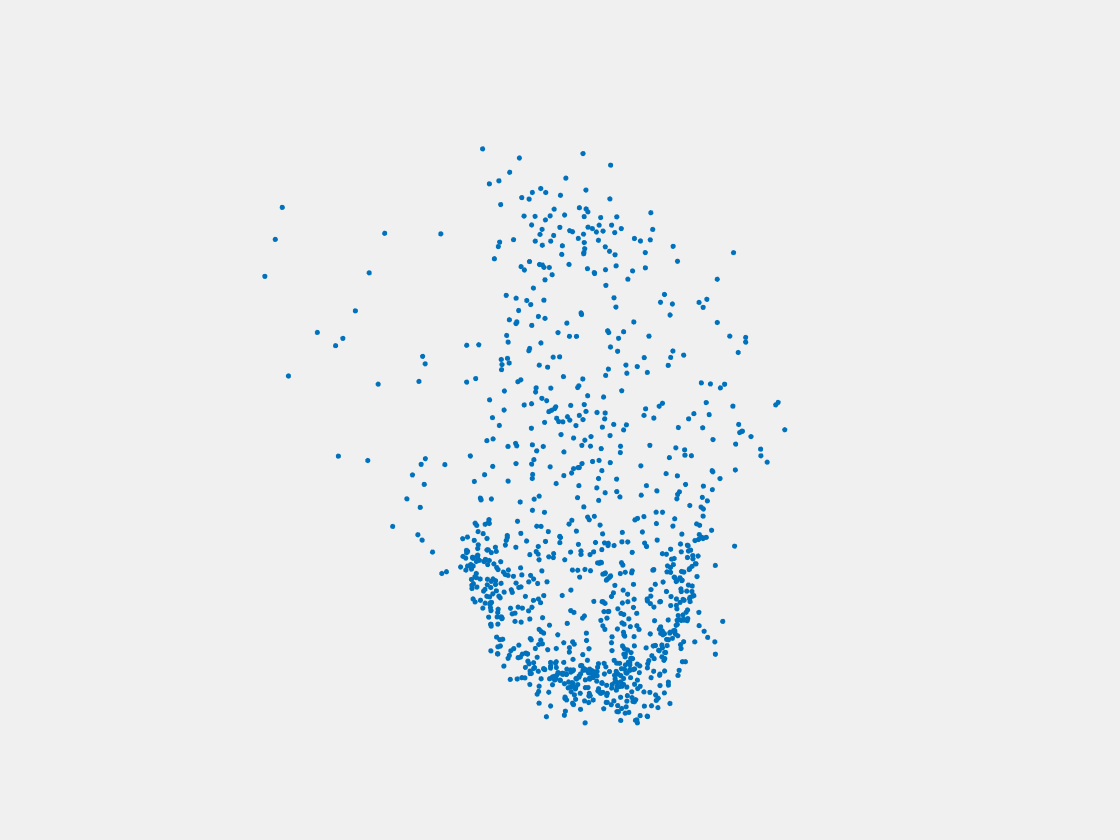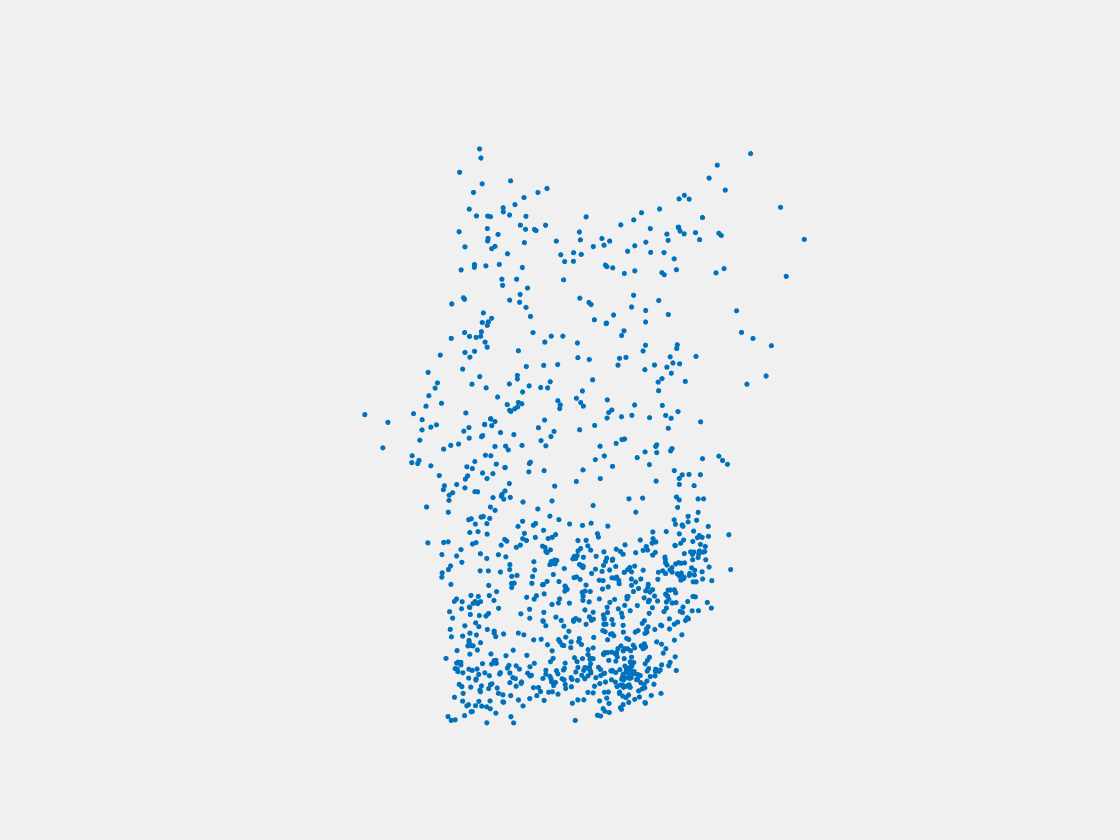
Figure 7: Point clouds of training image generated by PointSetNet fine-tuned with single (image, point cloud) pair for each Pokemon. Left to right, top to bottom: Charmander, Blastoise, Pidgeot, Raticate, Arbok, and Pikachu.
Testing Samples
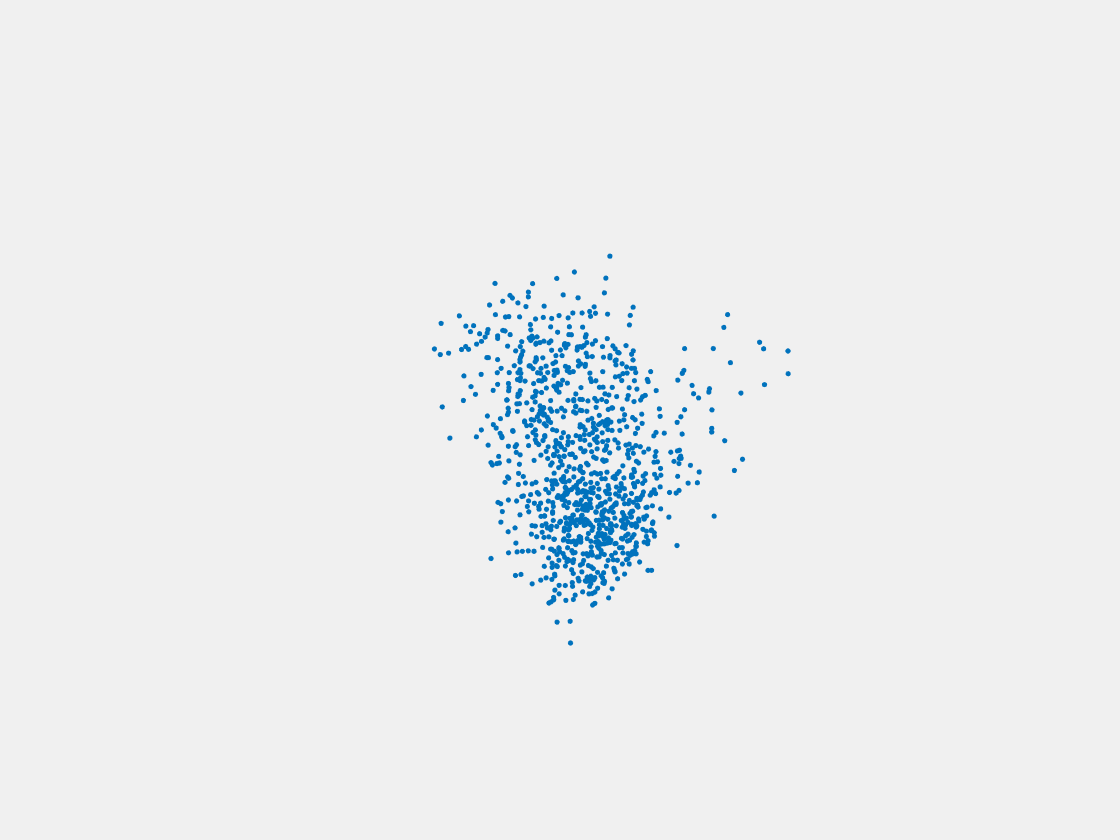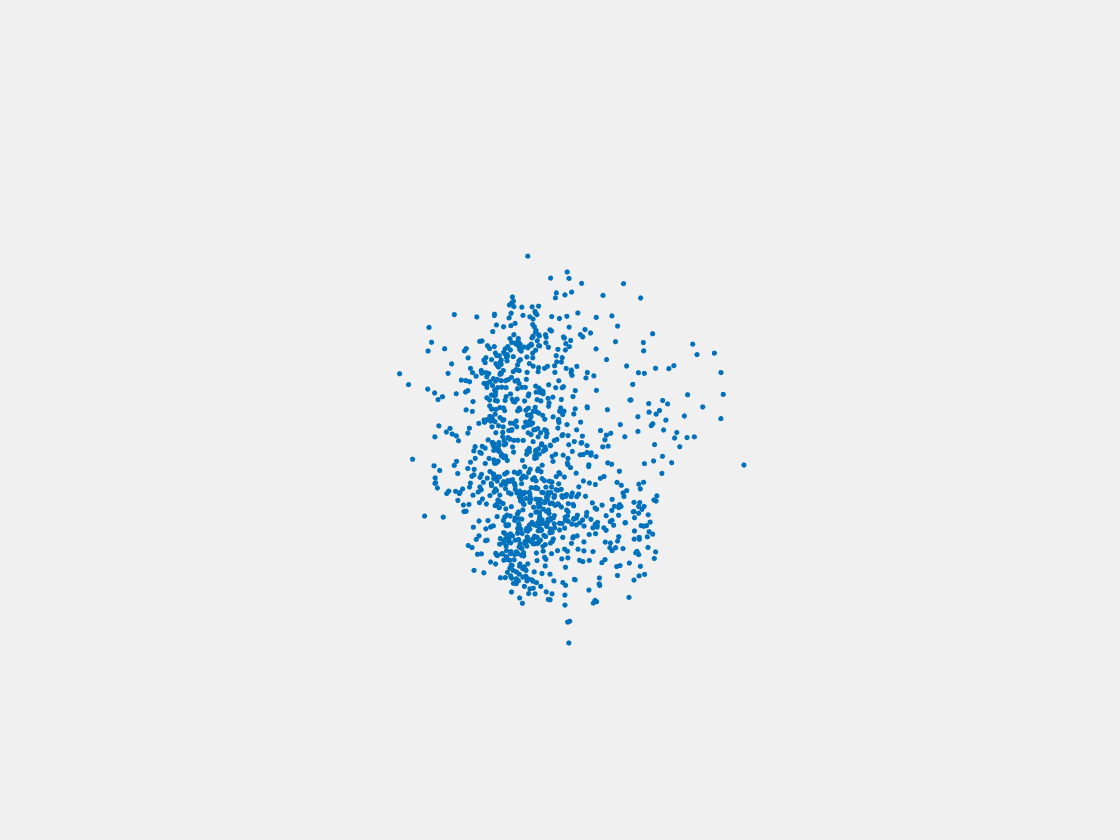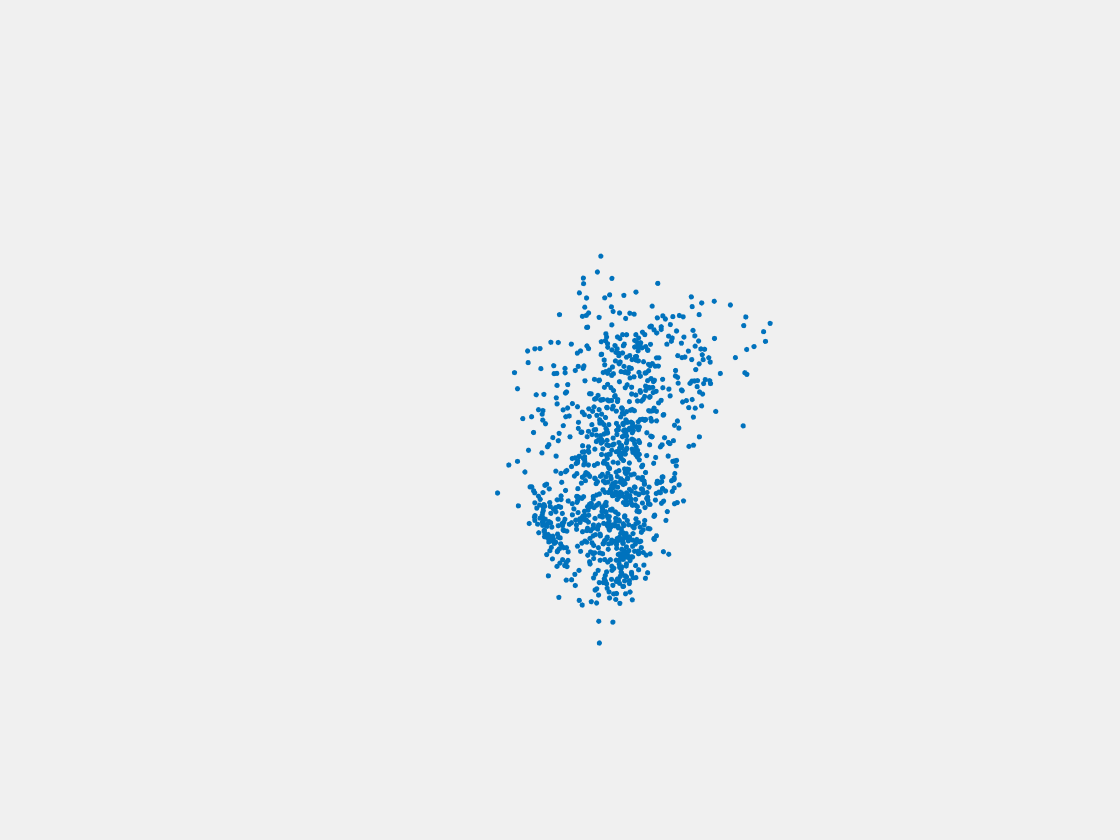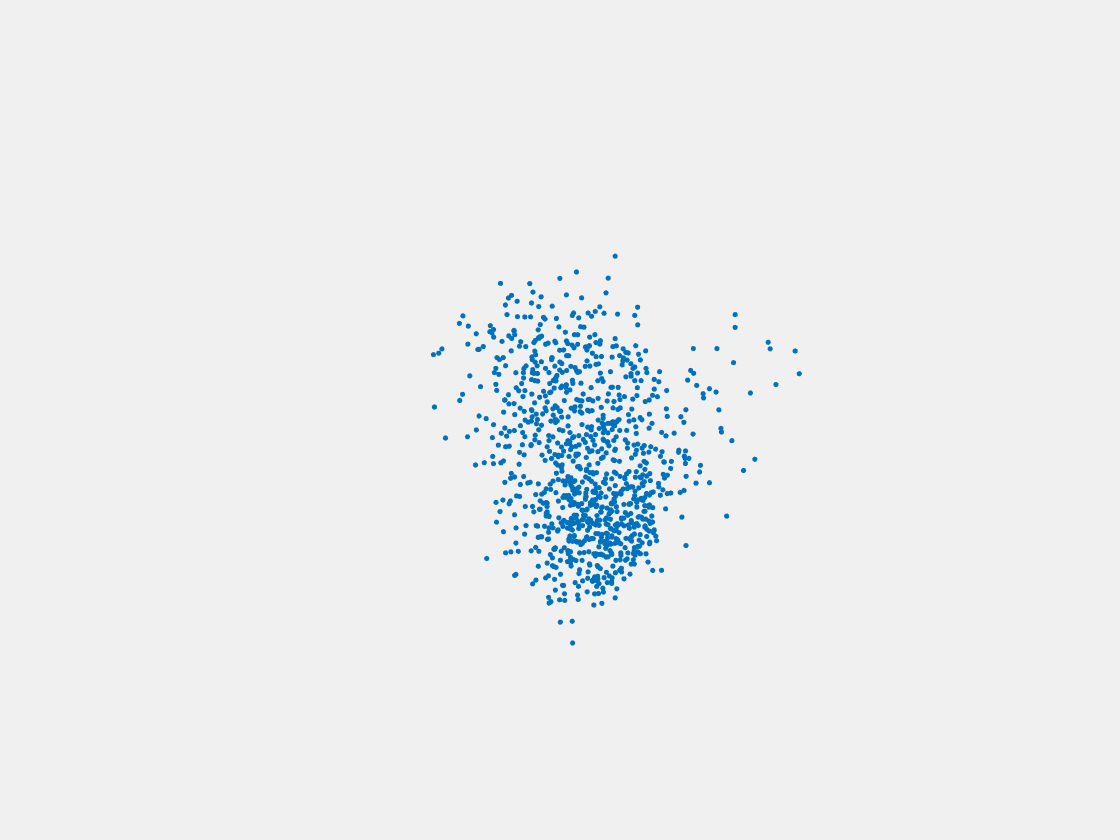
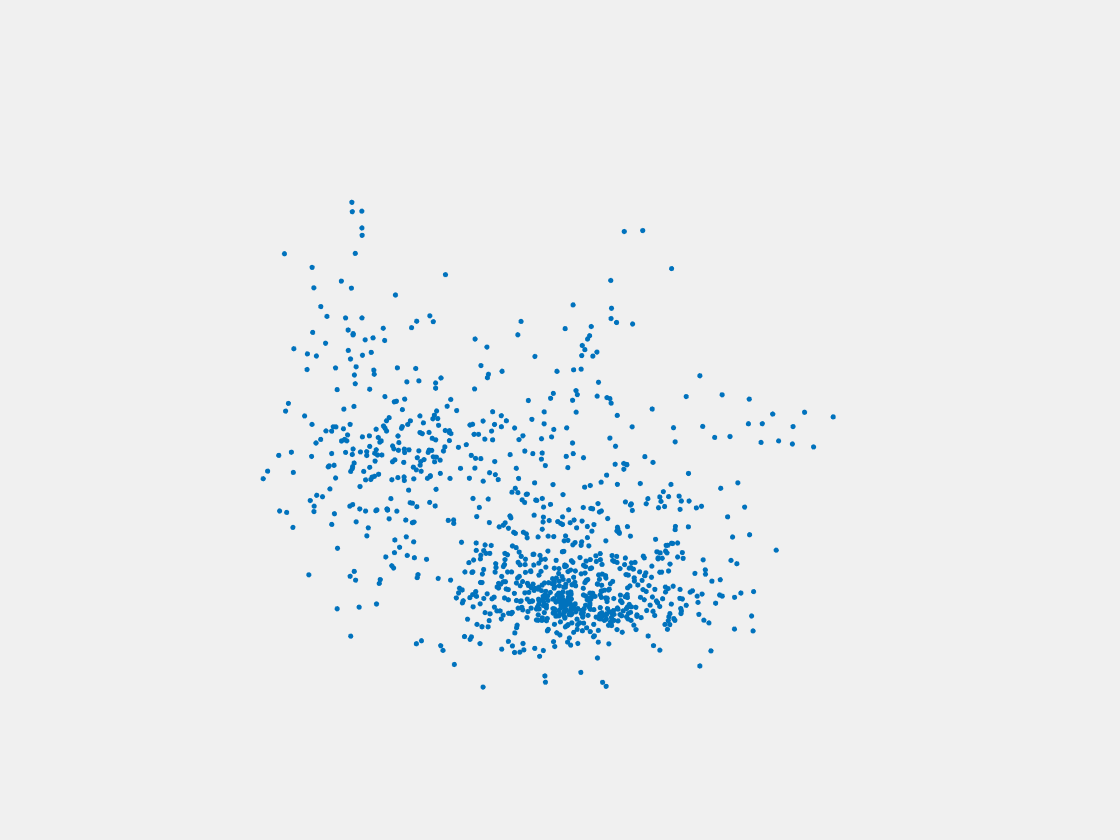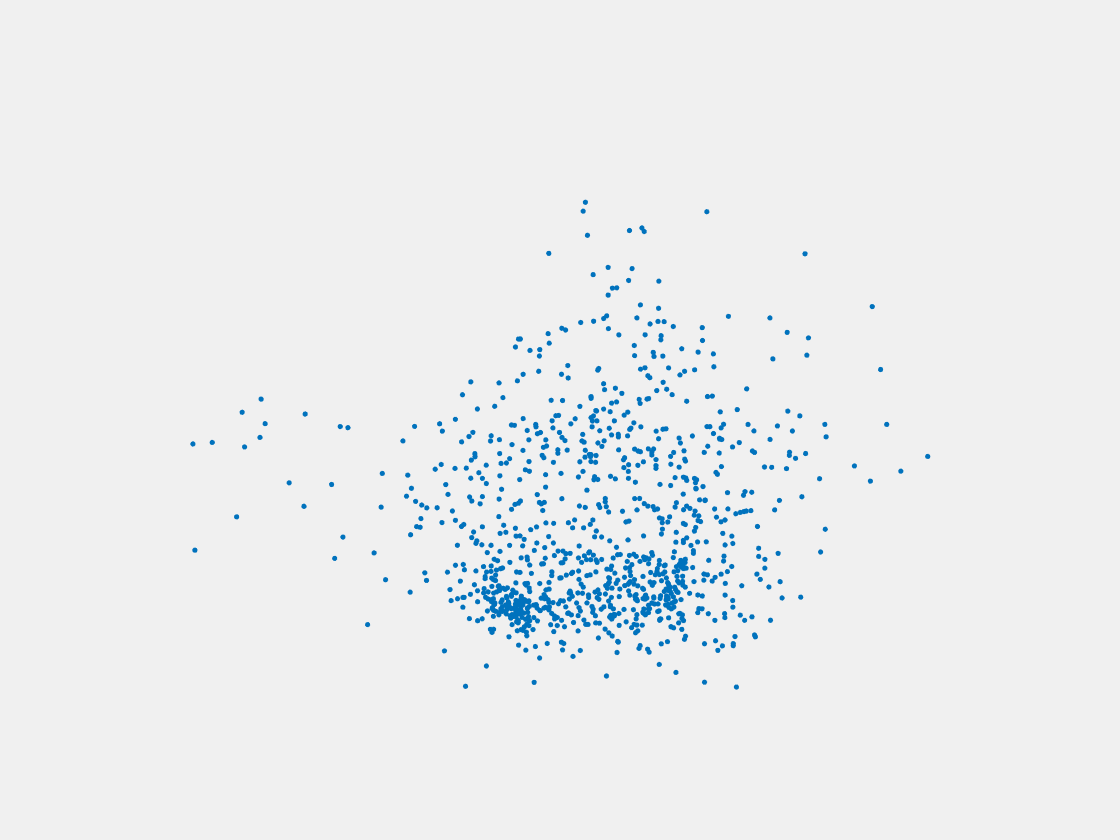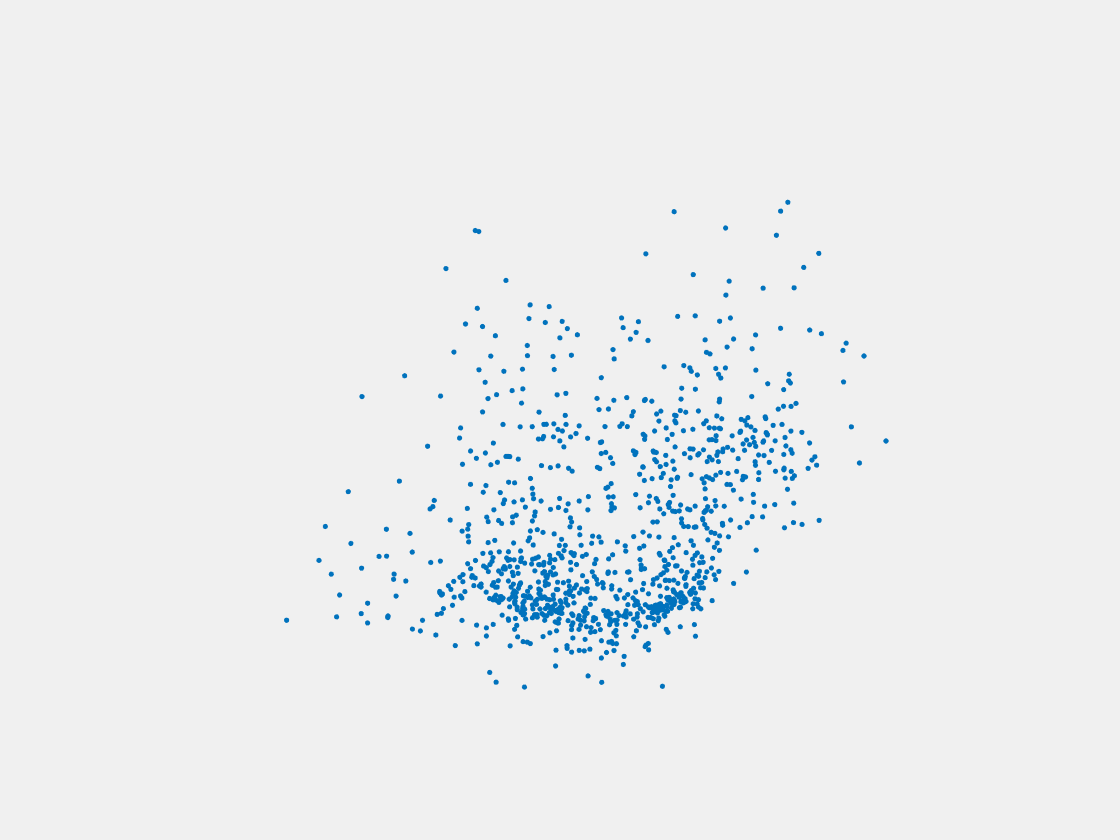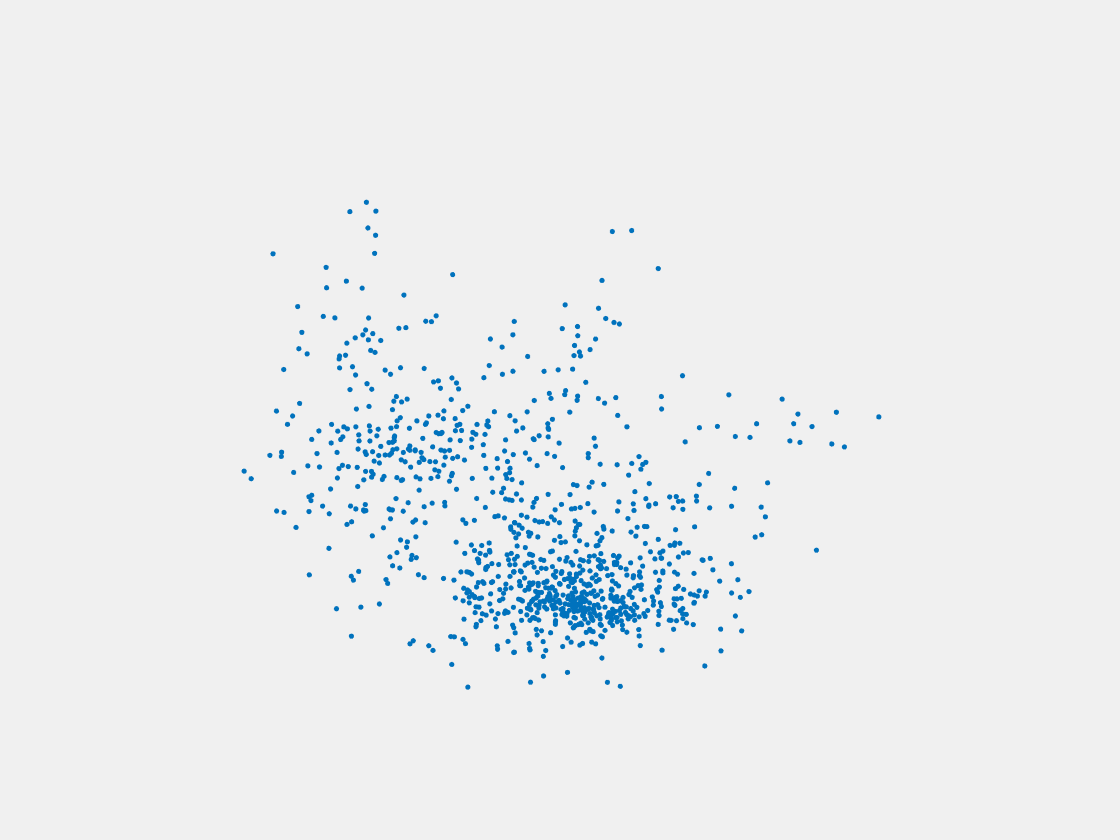
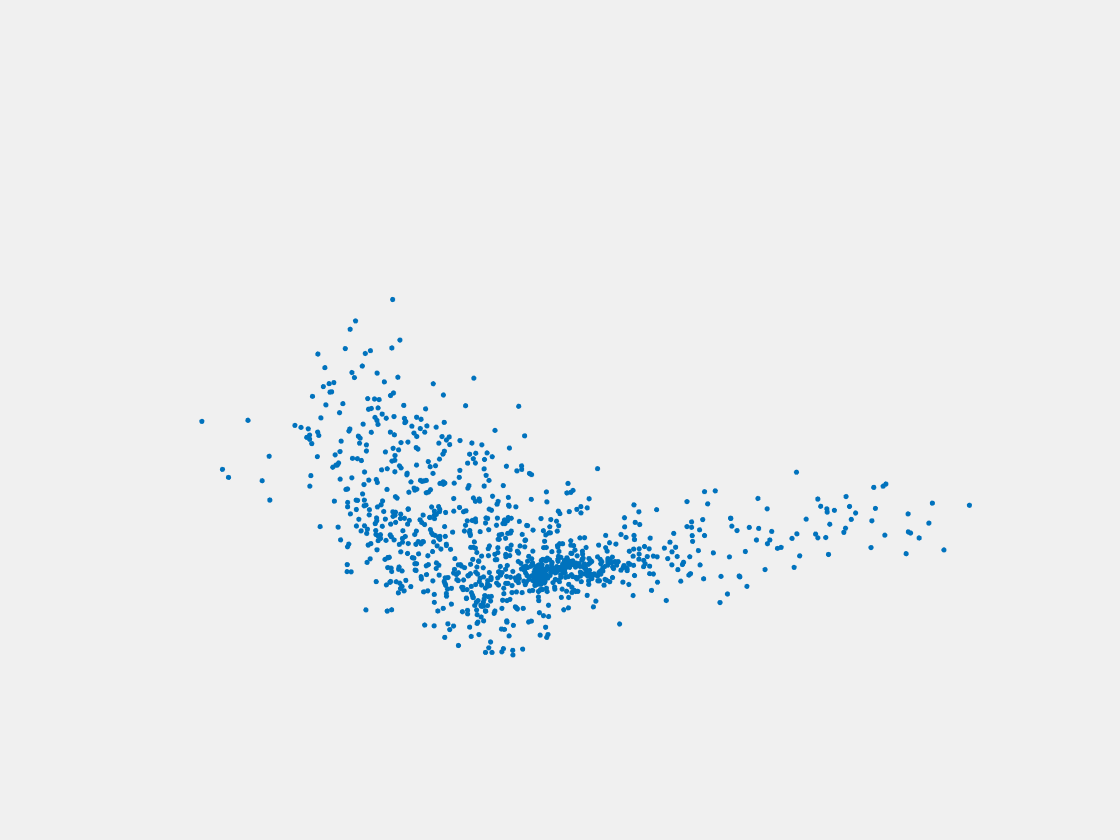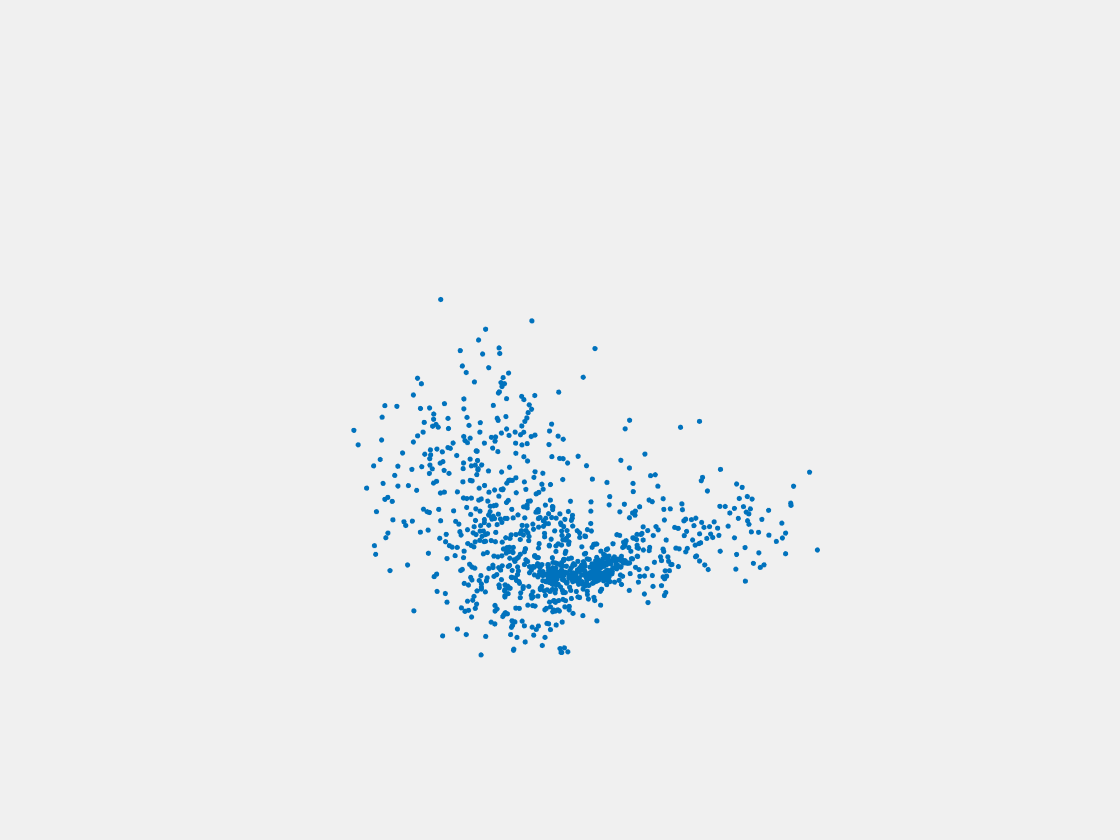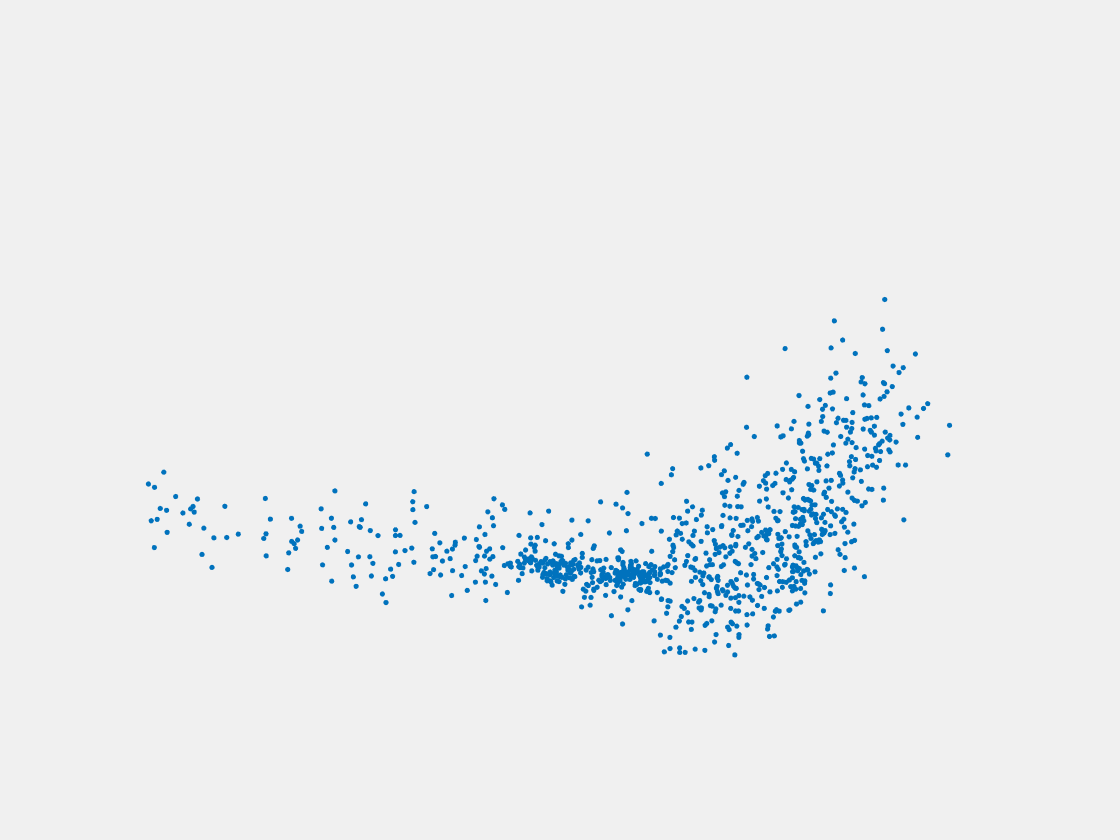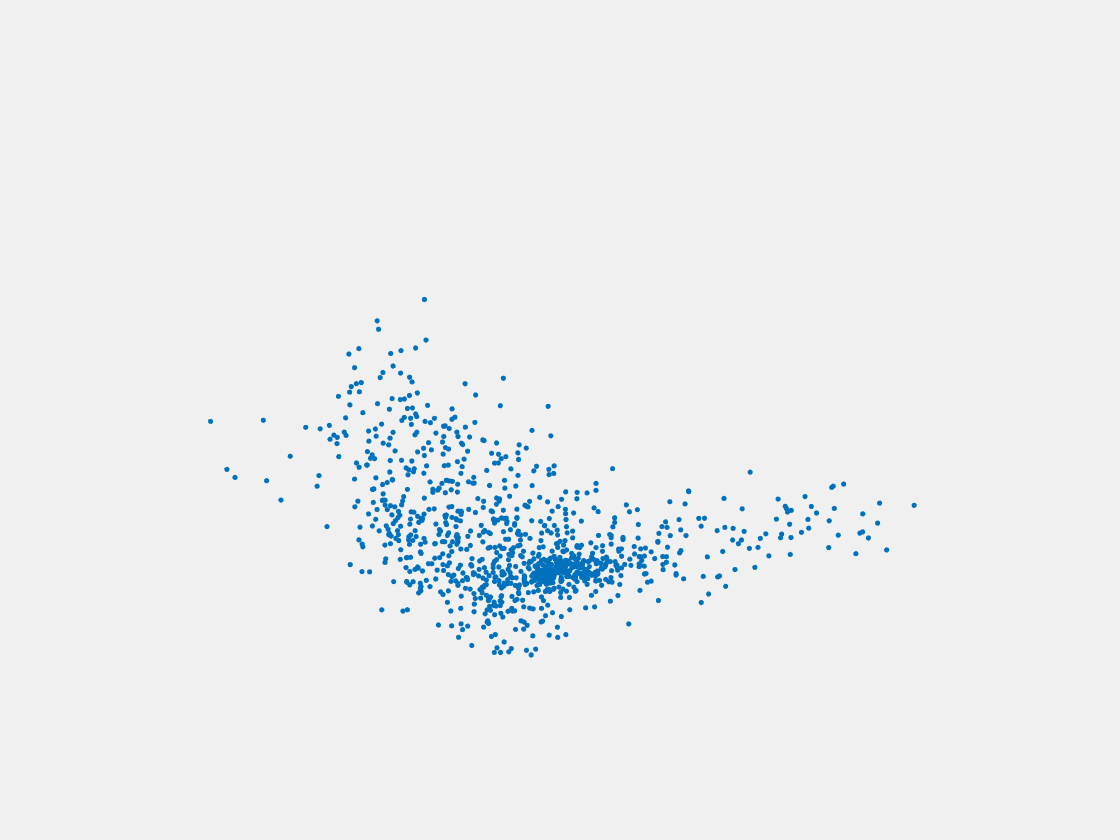
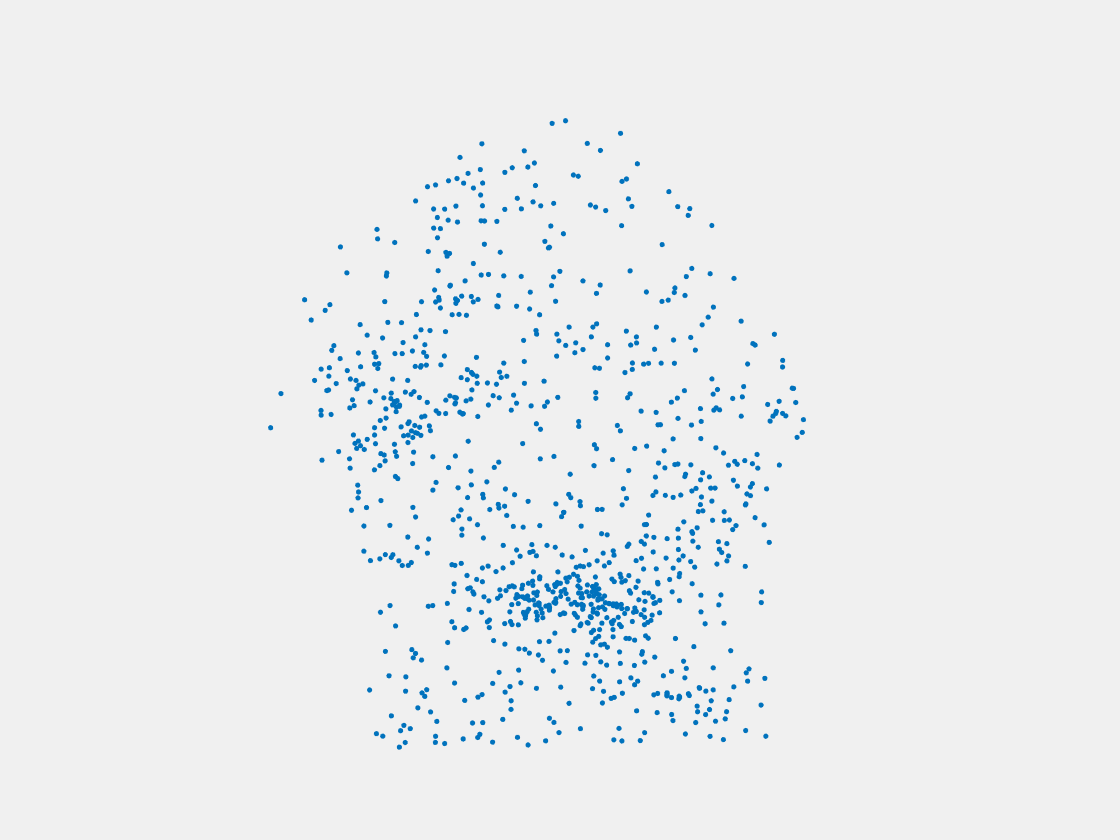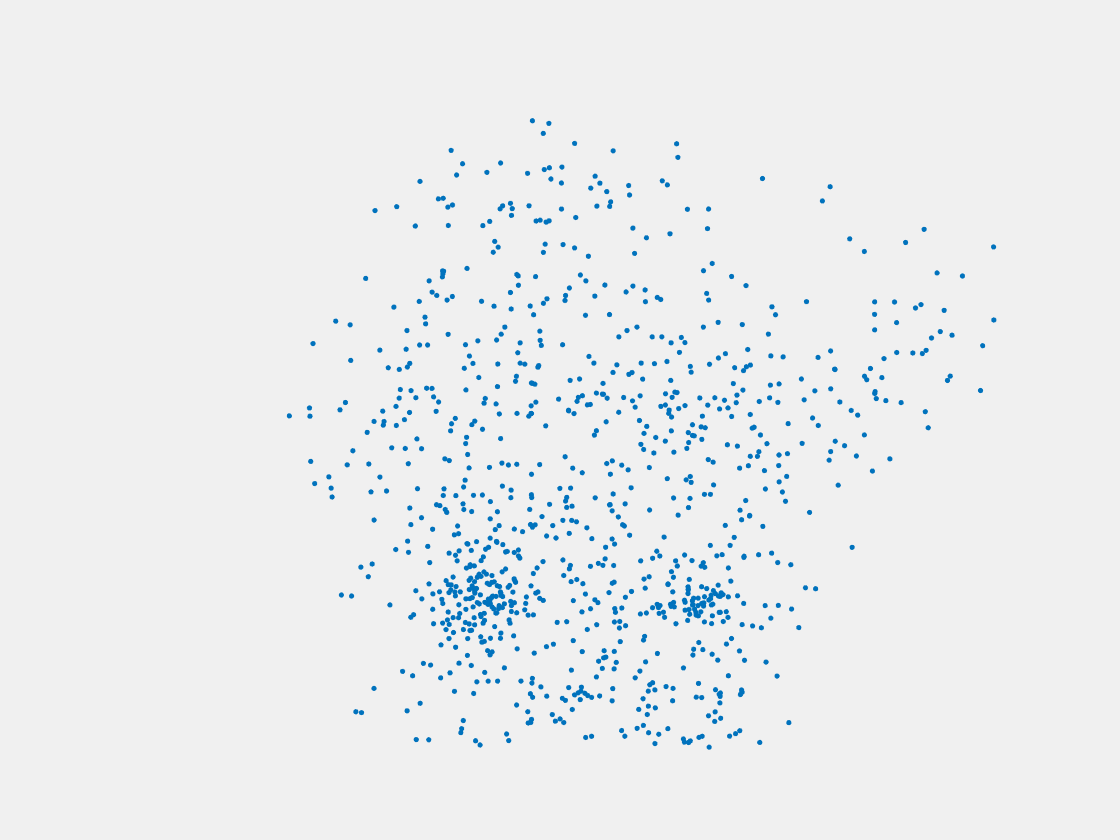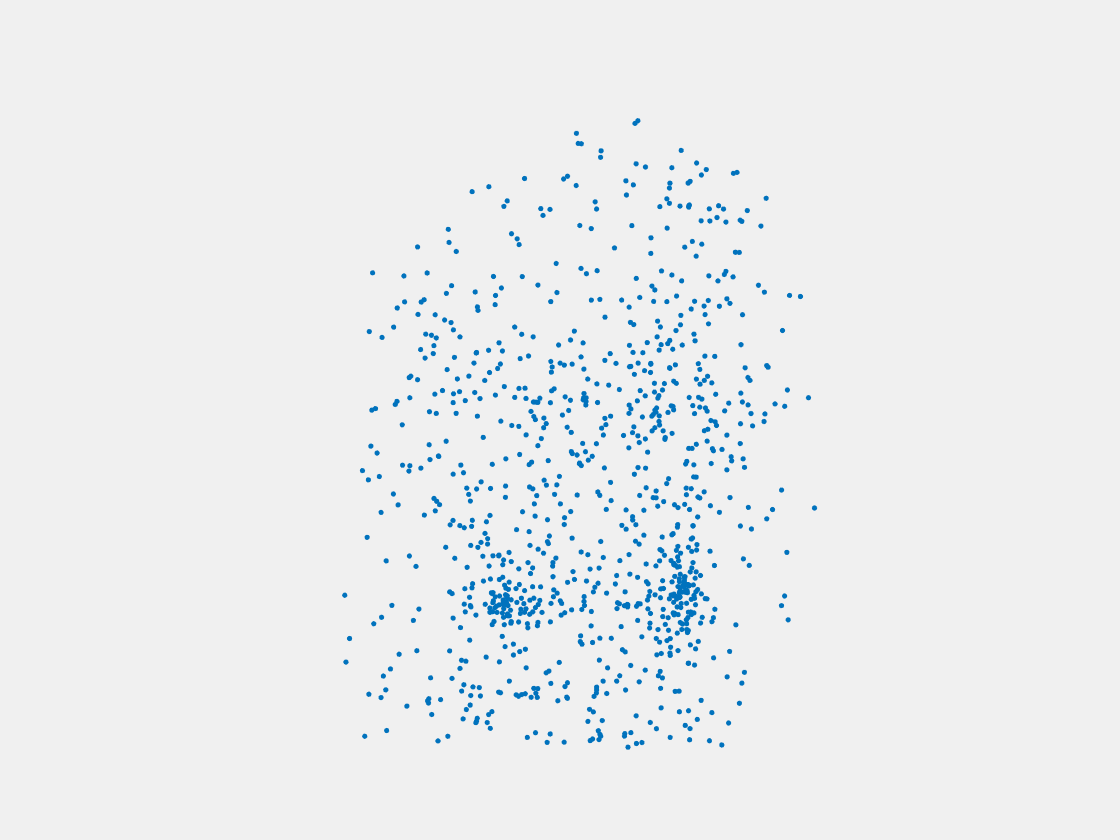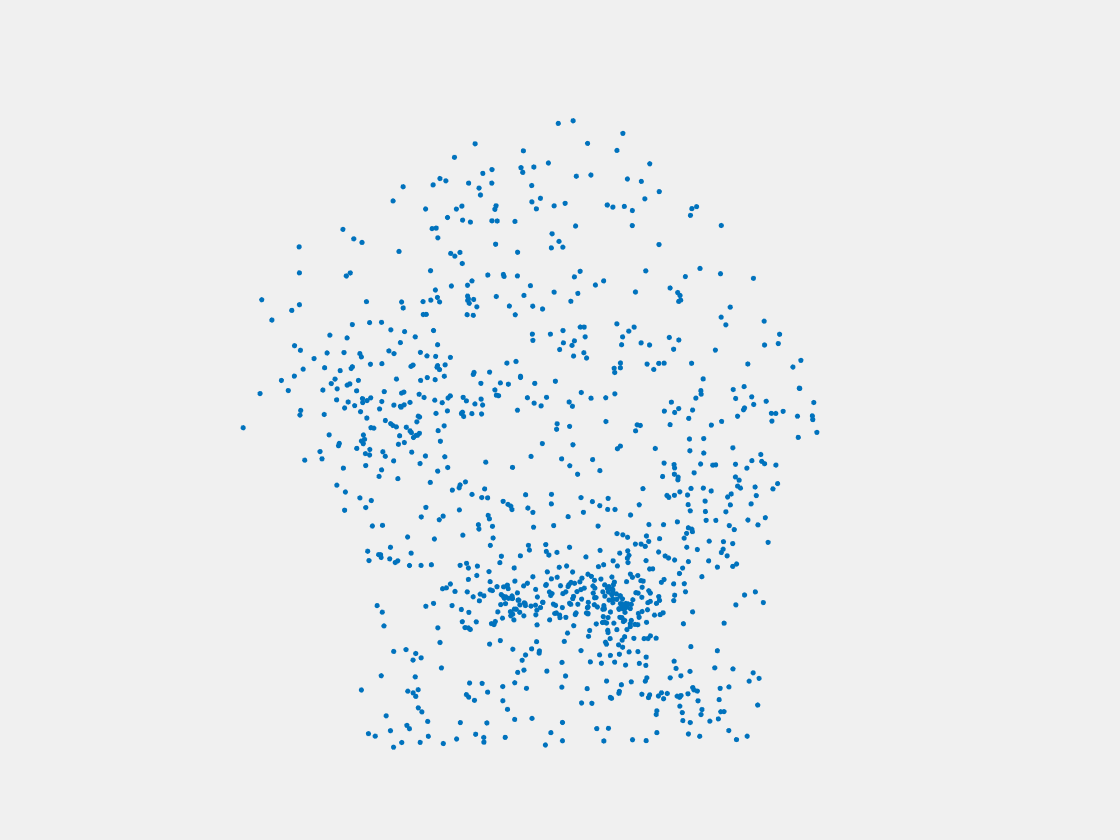
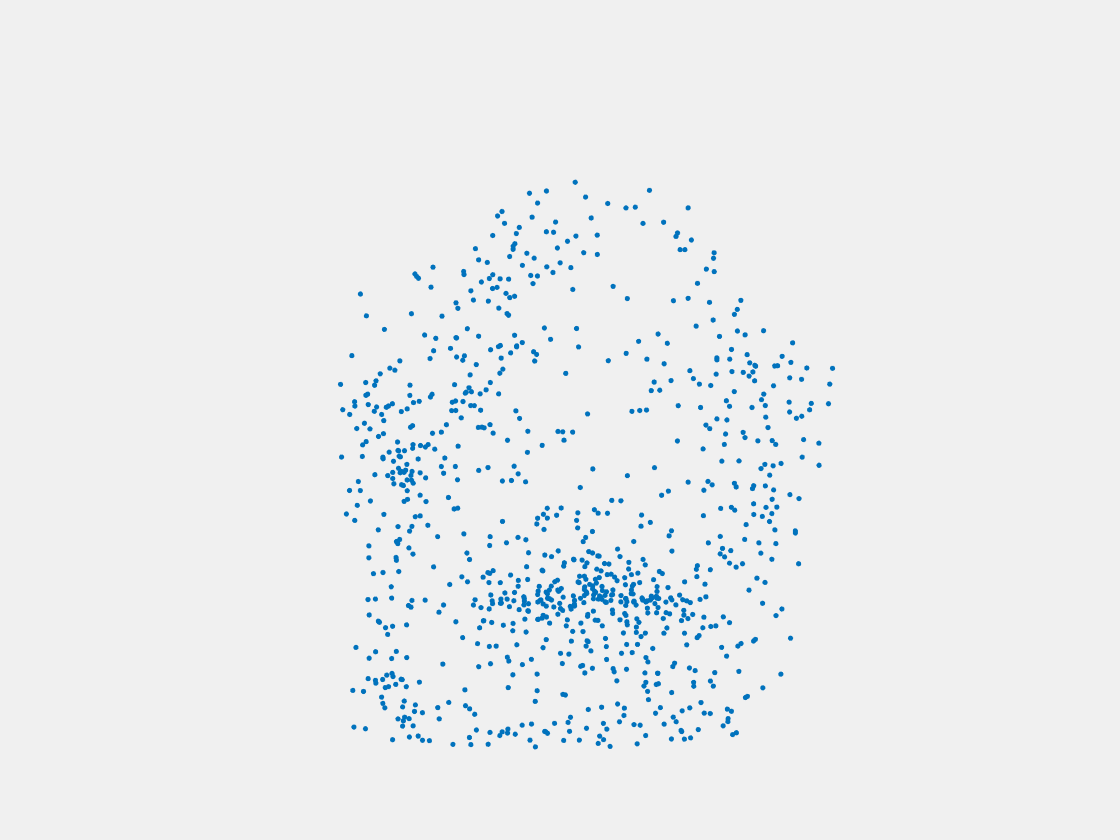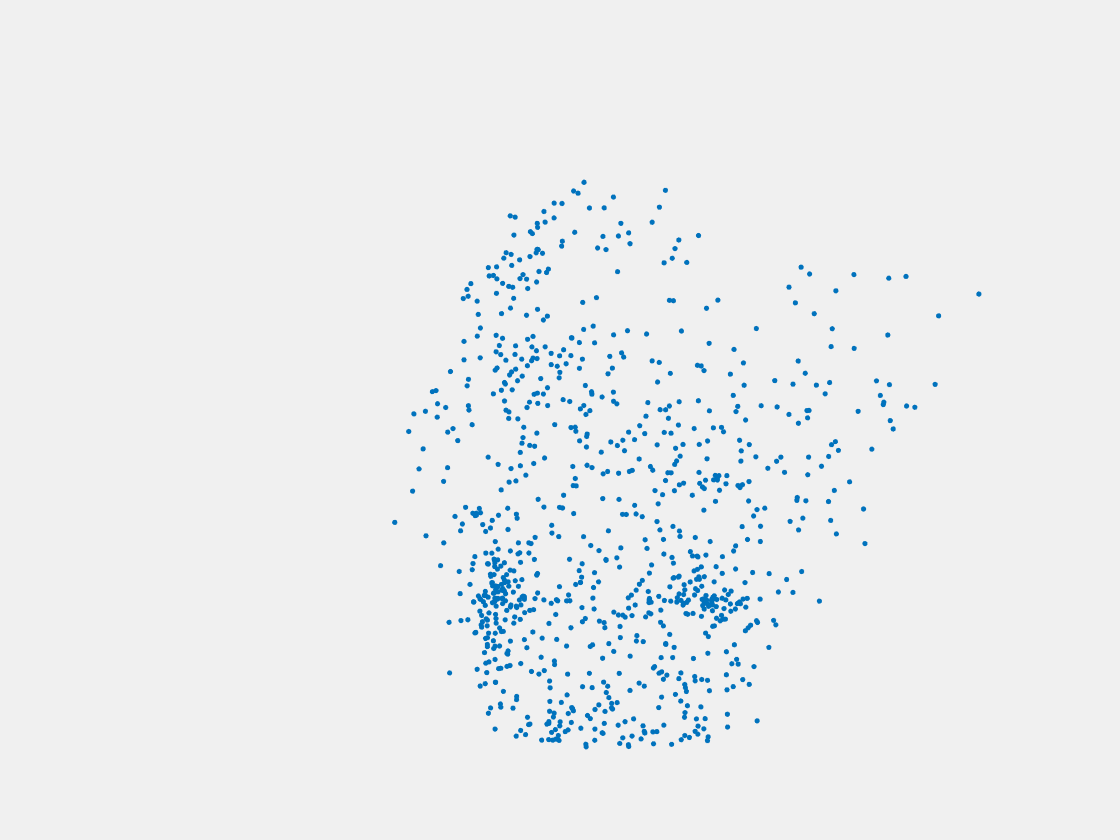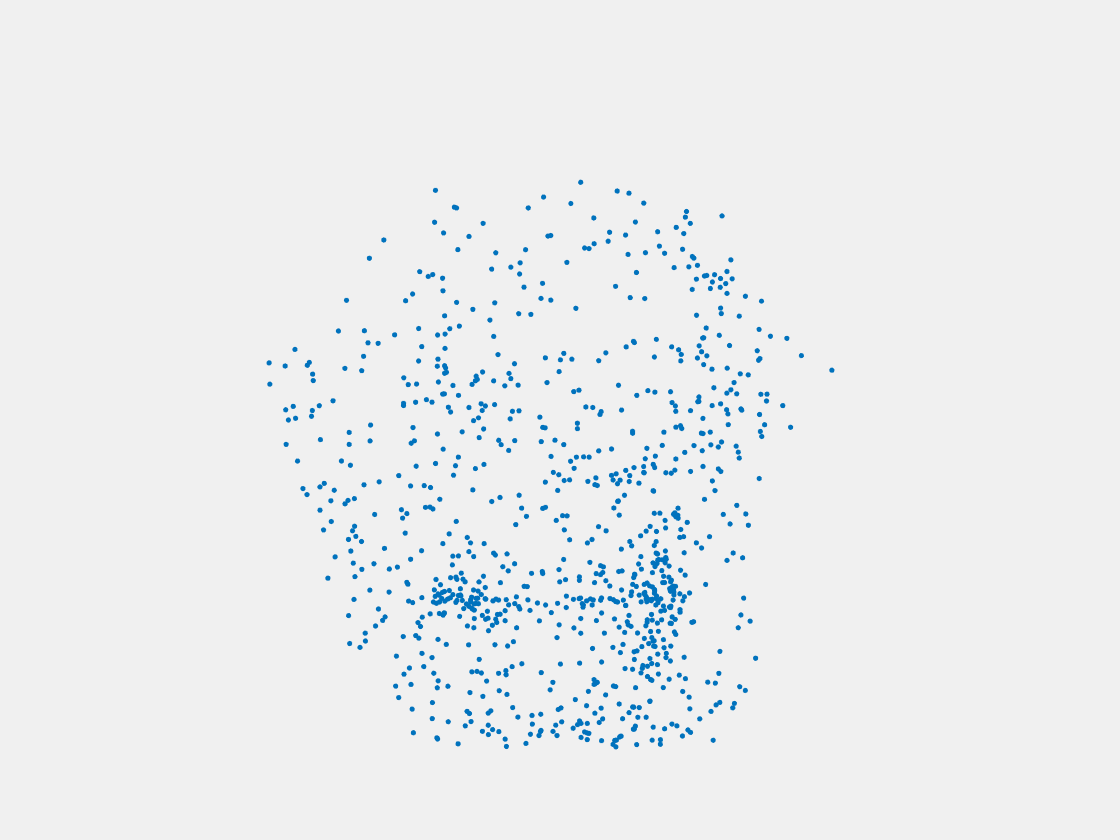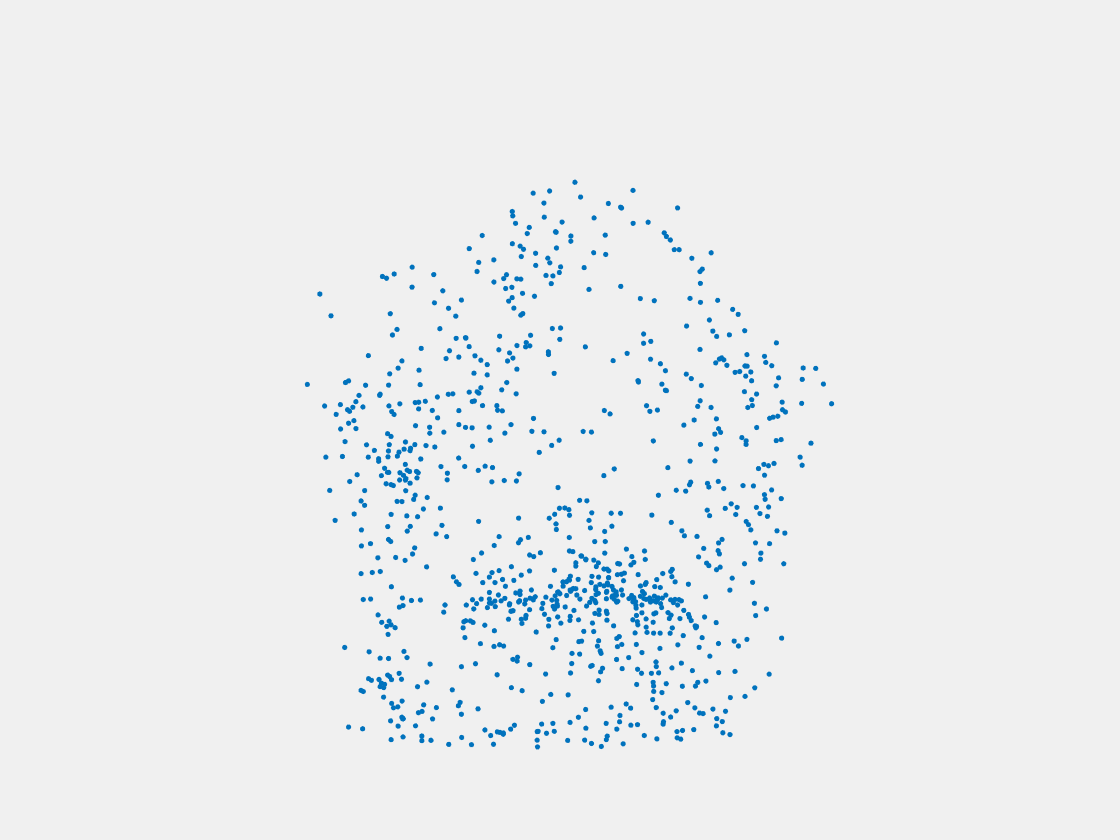
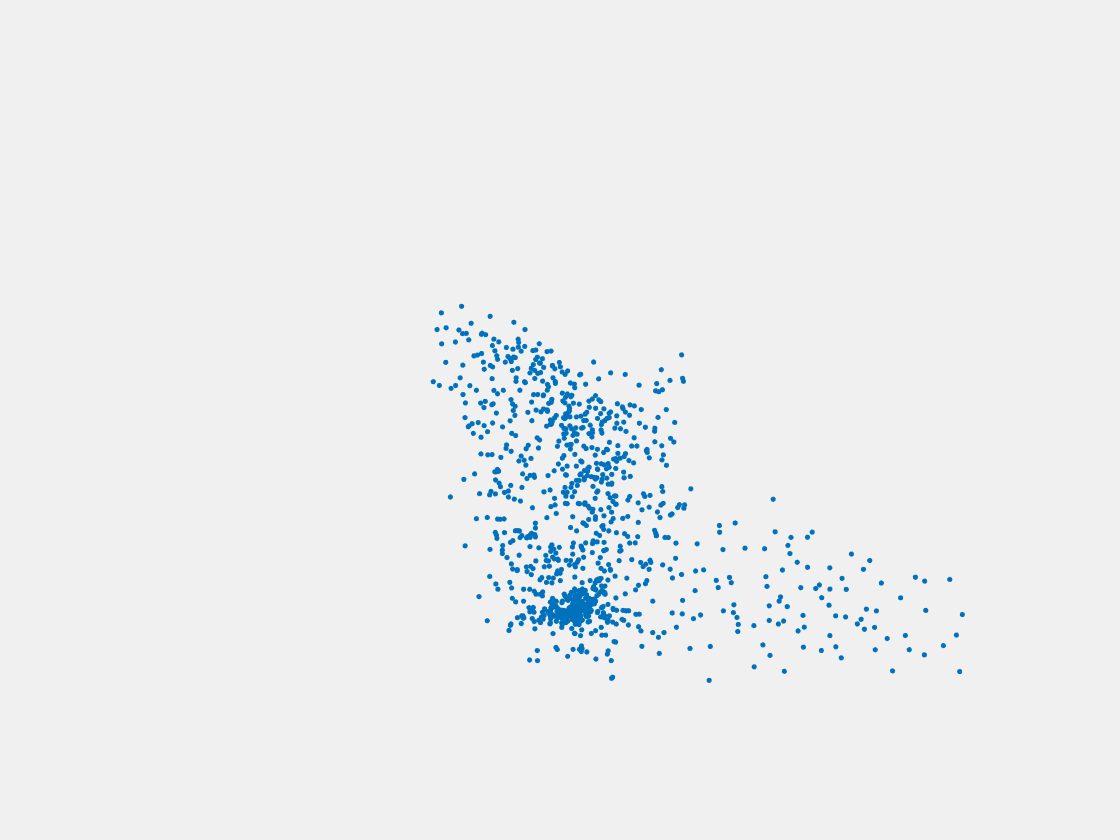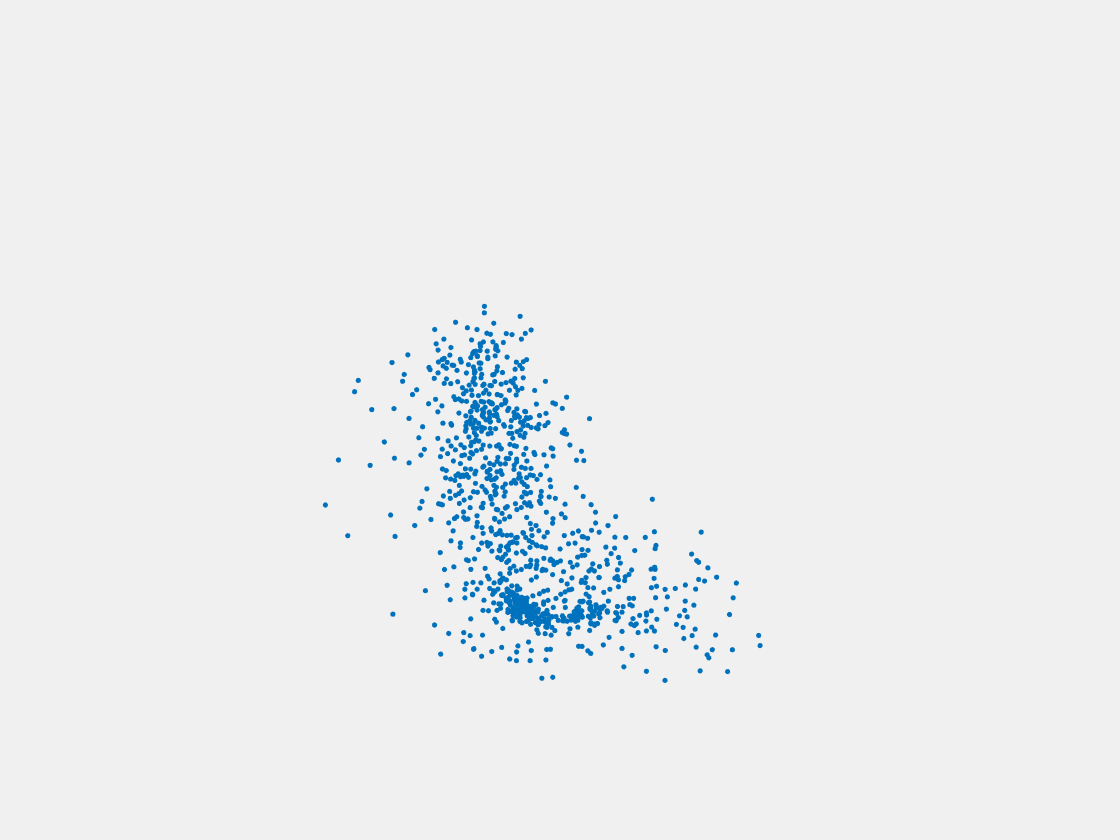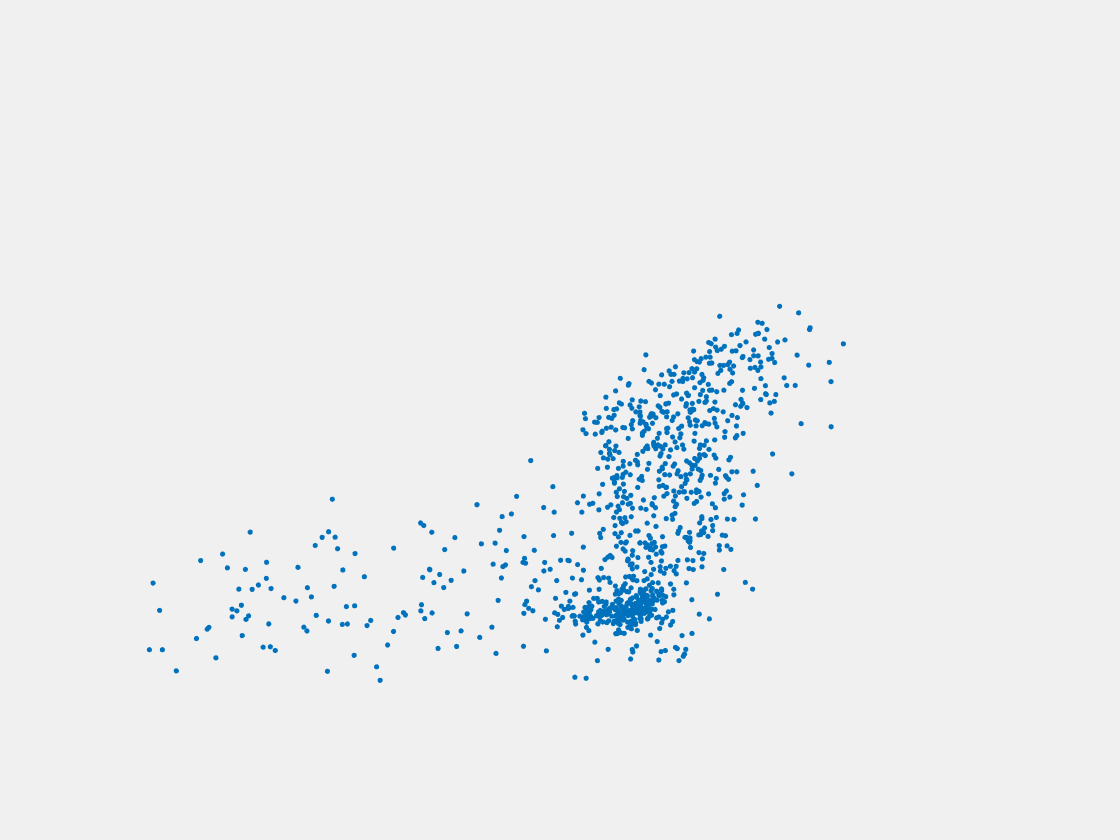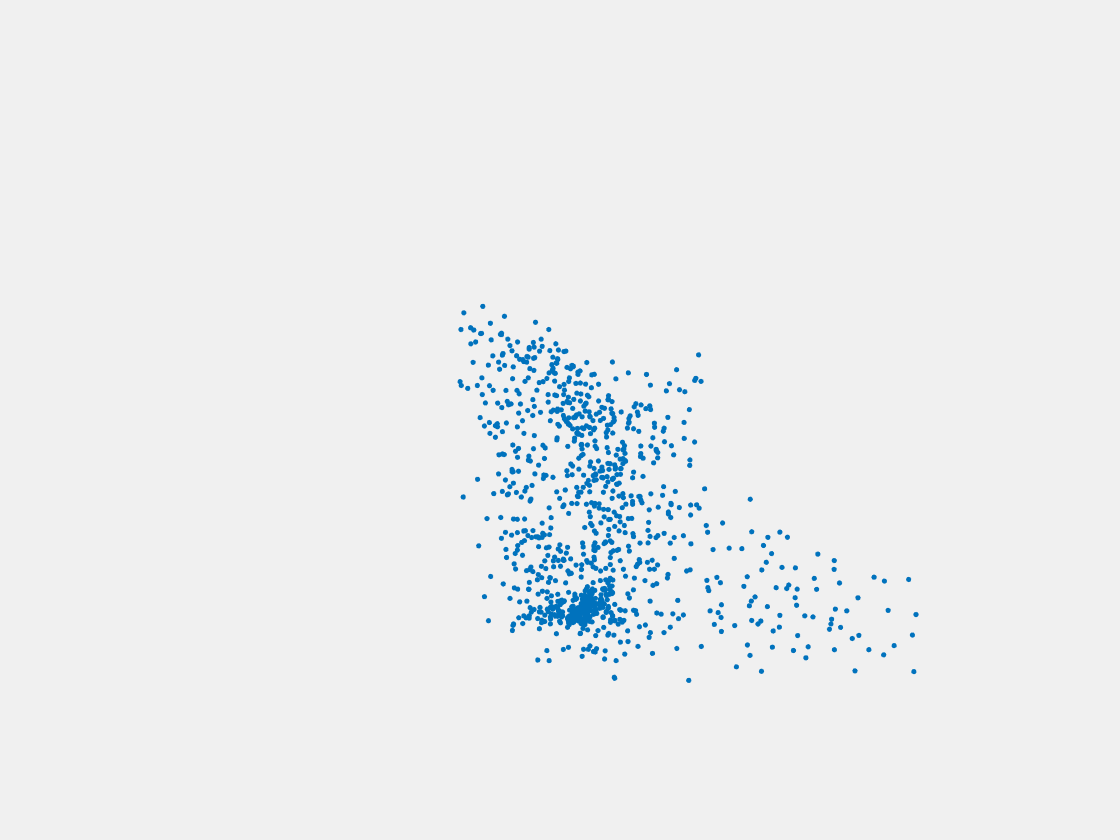
Figure 8: Point clouds of testing image generated by PointSetNet fine-tuned with single (image, point cloud) pair for each Pokemon. Left to right, top to bottom: Pikachu, Farfetch’d, Dewgong, Gengar, Snorlax, and Mew. Though the point cloud predictions of training images are good, we can hardly recognize the Pokemon from the point cloud predictions of testing images.
PointSetNet Fine-Tuned with Multiple (Image, Point Cloud) Pairs for Each Pokemon
Next, we try to feed more than one view images per pokemon into PointSetNet. We take 30 rendered view images of each pokemon, and rotate the ground truth point cloud differently for each image, according to its view points. In this way, we can re-train PointSetNet with multiview images and the network will be able to learn front, side, and back views from the training samples.
The results are shown below. Now, the outline of point clouds from both training and testing samples become much clearer, as compared to the previous network trained with a single view for each pokemon. This is reasonable because we use more training data that involve information of all front, side, and back views. However, we observe that the performance for testing samples is still not very robust when we look at the point cloud from some particular angles. (For example, the side view of the top-left point cloud in Figure 10.)
Indeed, the limitation of this architecture is that the network treats different view images of the same pokemon independently. Although the network now learns more view information from more data, when more than one view images of a pokemon are available, it is not able to aggregate all view images. It may also suffer from overfitting. We observe that point clouds from testing samples are much worse than those from training samples. Moreover, some different testing samples end up having similar point clouds, which are possibly close to a ground truth point cloud the network learned during training. (For instance, we can see that the results of Gengar and Snorlax in Figure 10 are very similar and both have an incorrect large rounded tail, which may come from those other Pokemon models in the training set.)
To mitigate the above problems, we then try to propose our own network architecture such that it can handle multiple view images in one input sample and can truly leverage and aggregate the information come from all the 2D views.
Training Samples
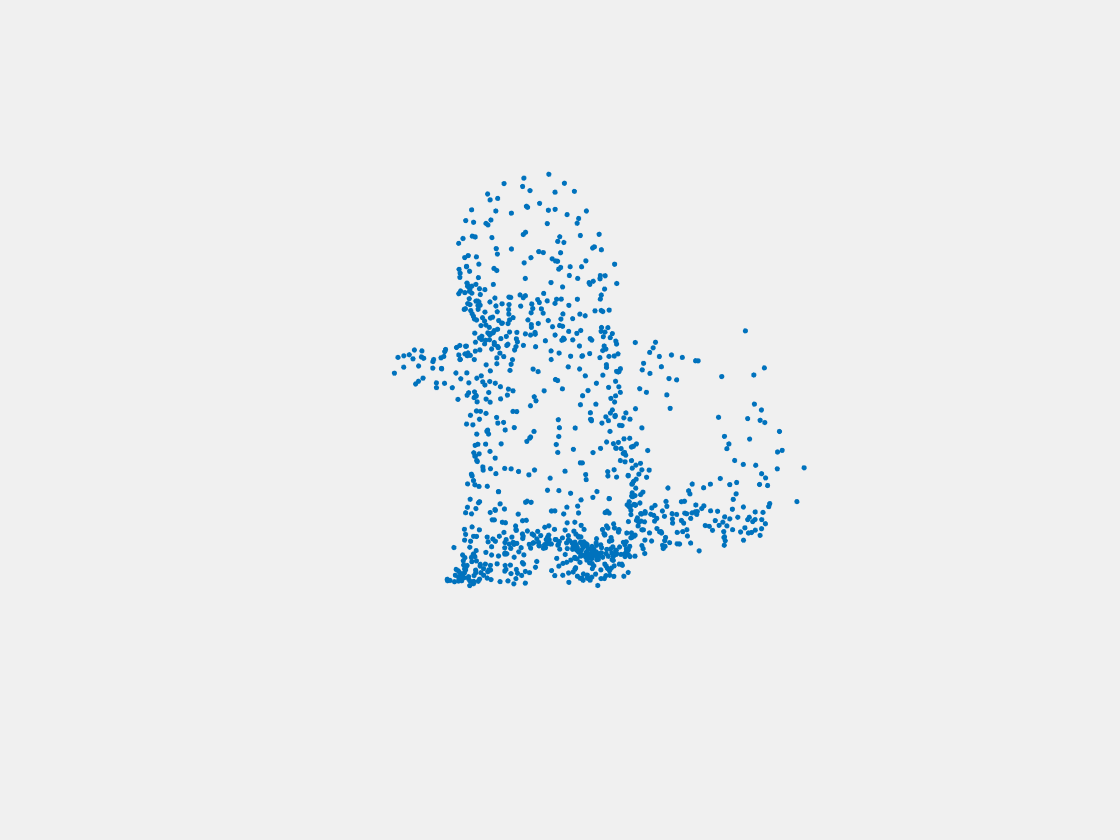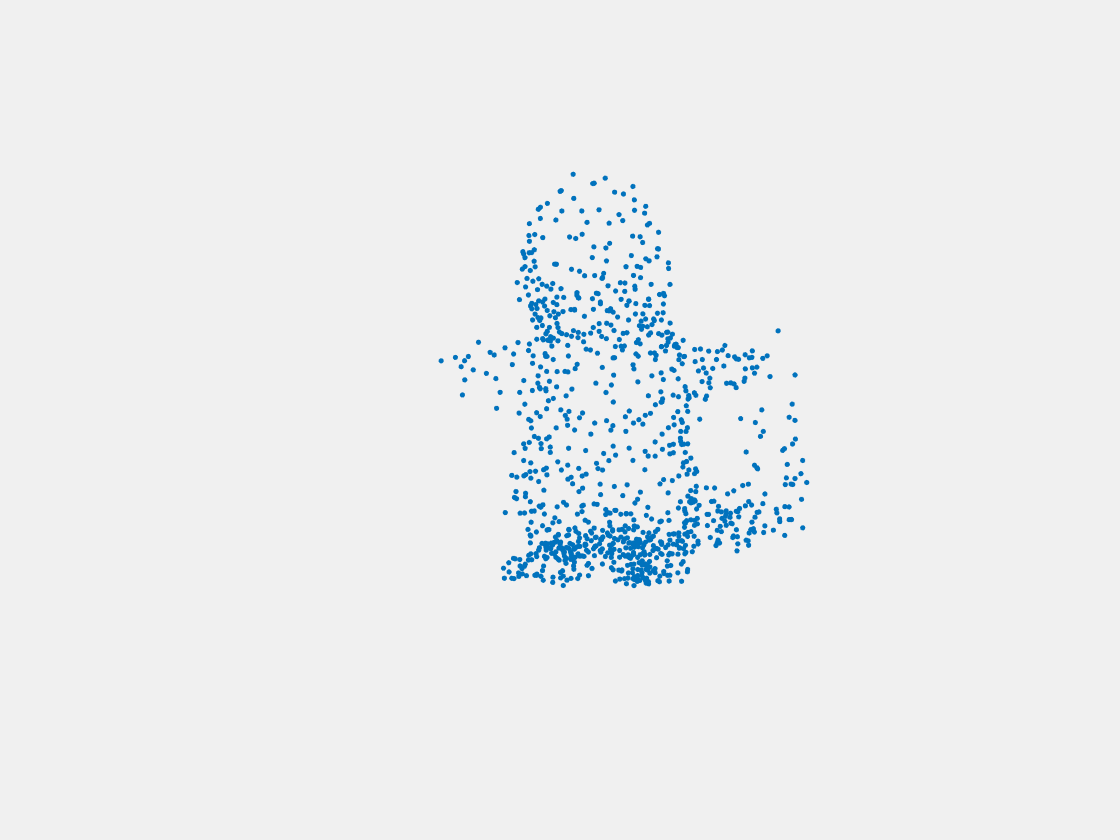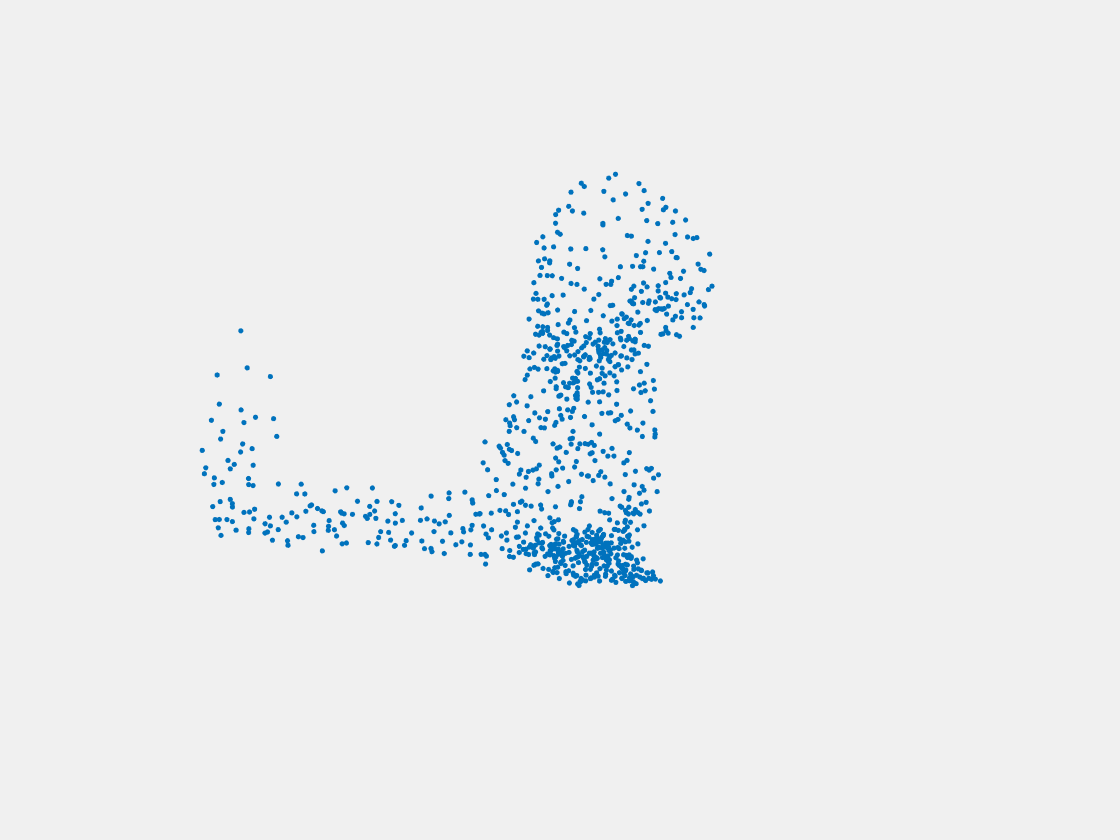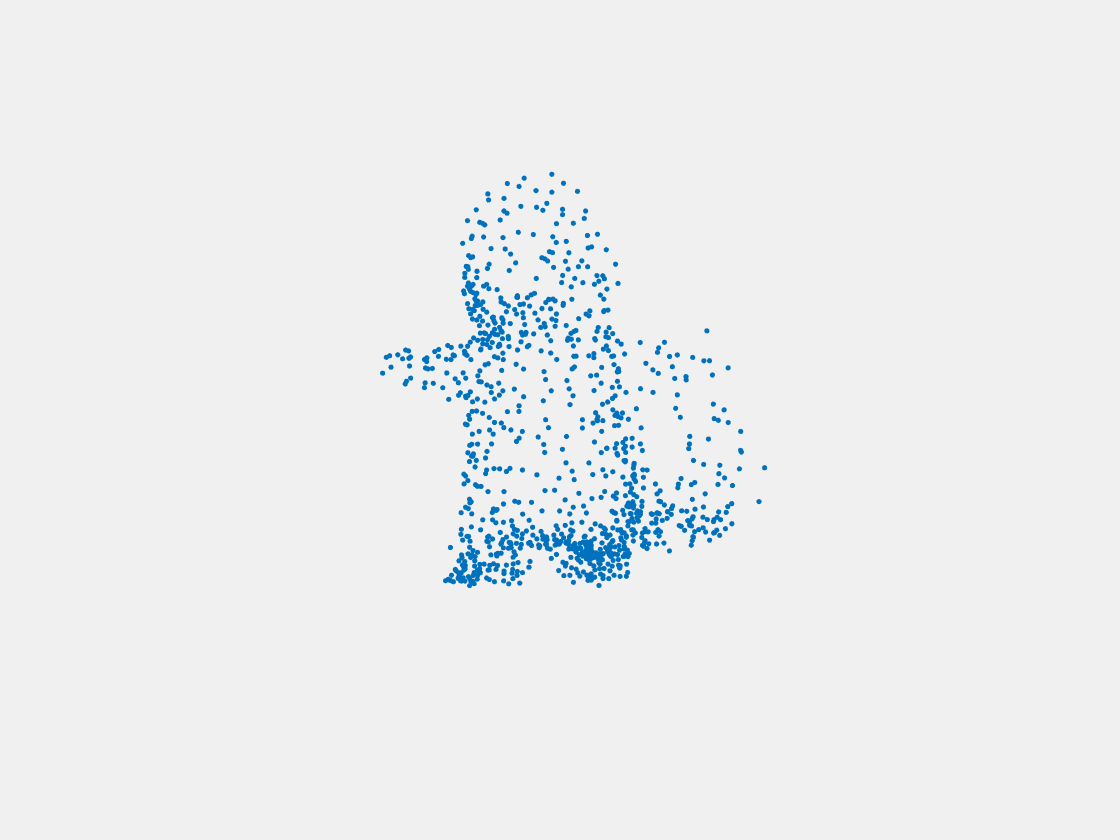

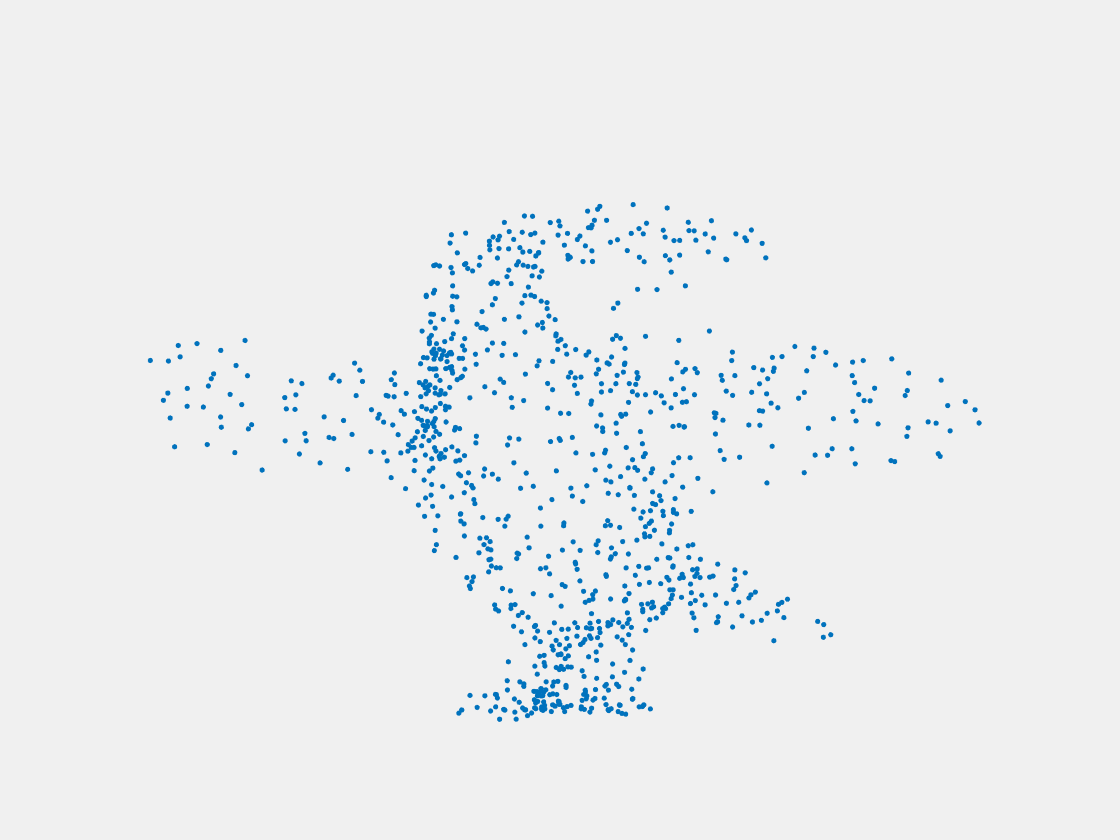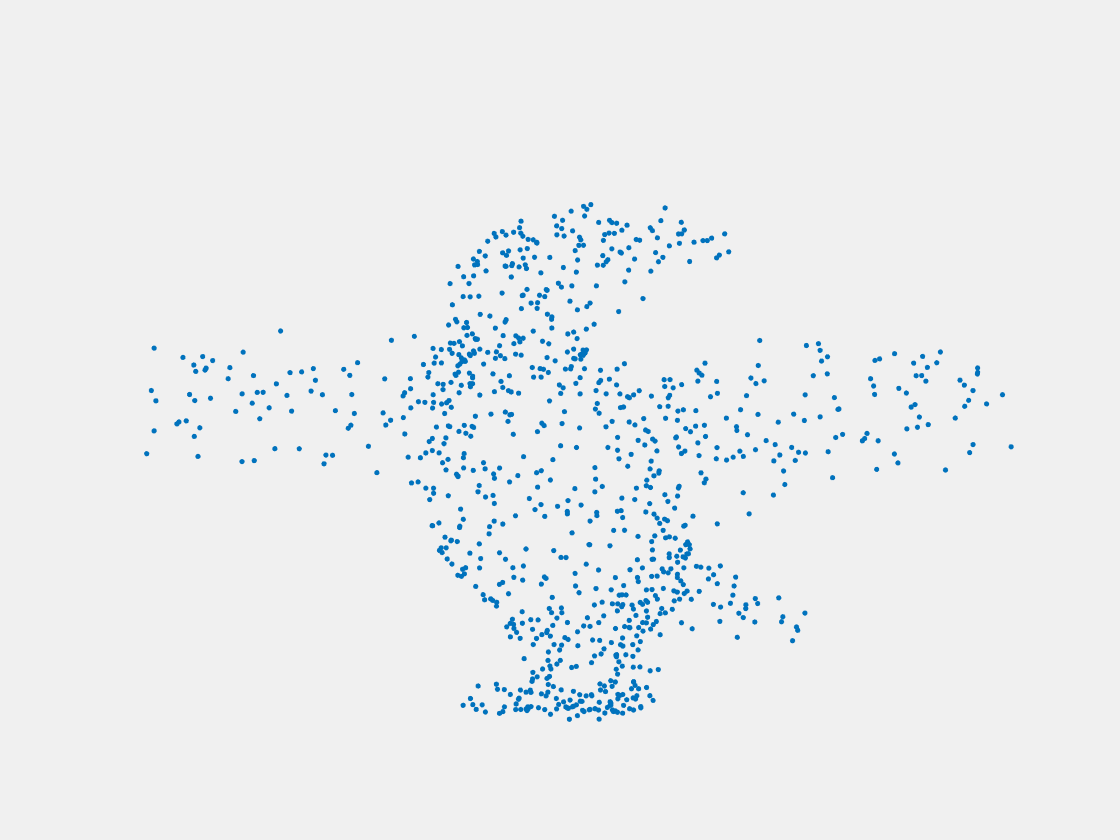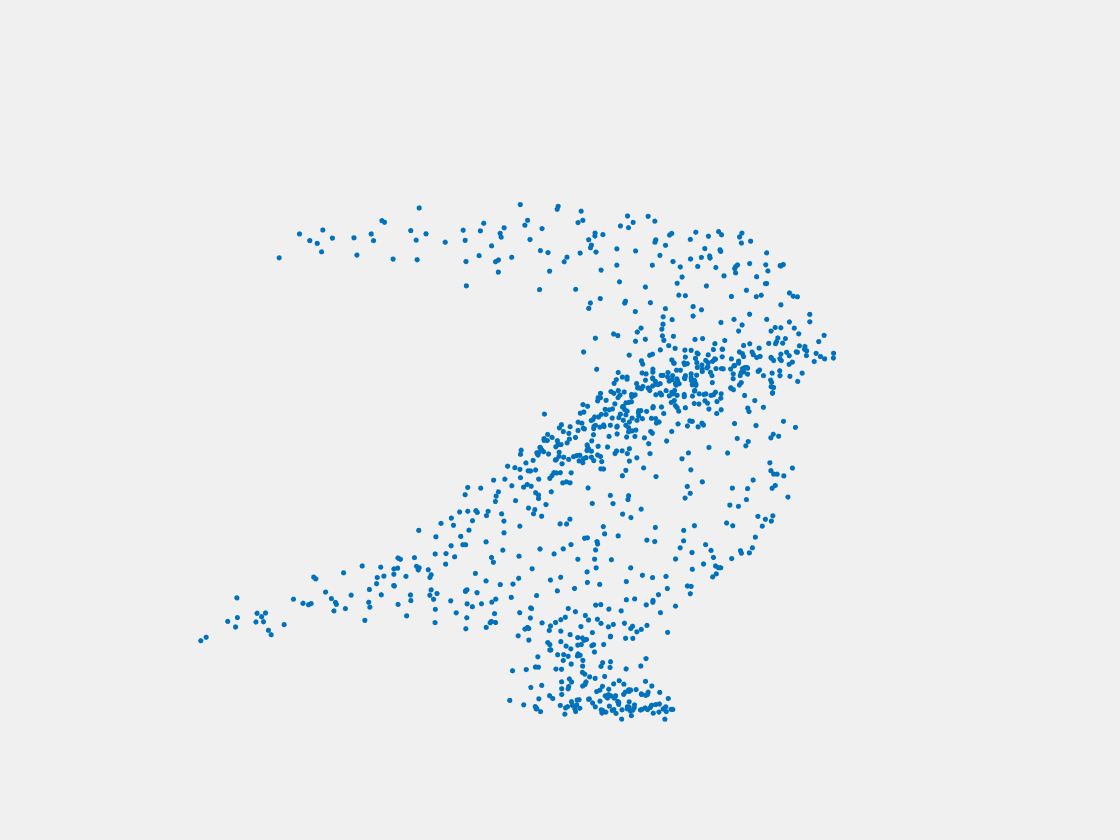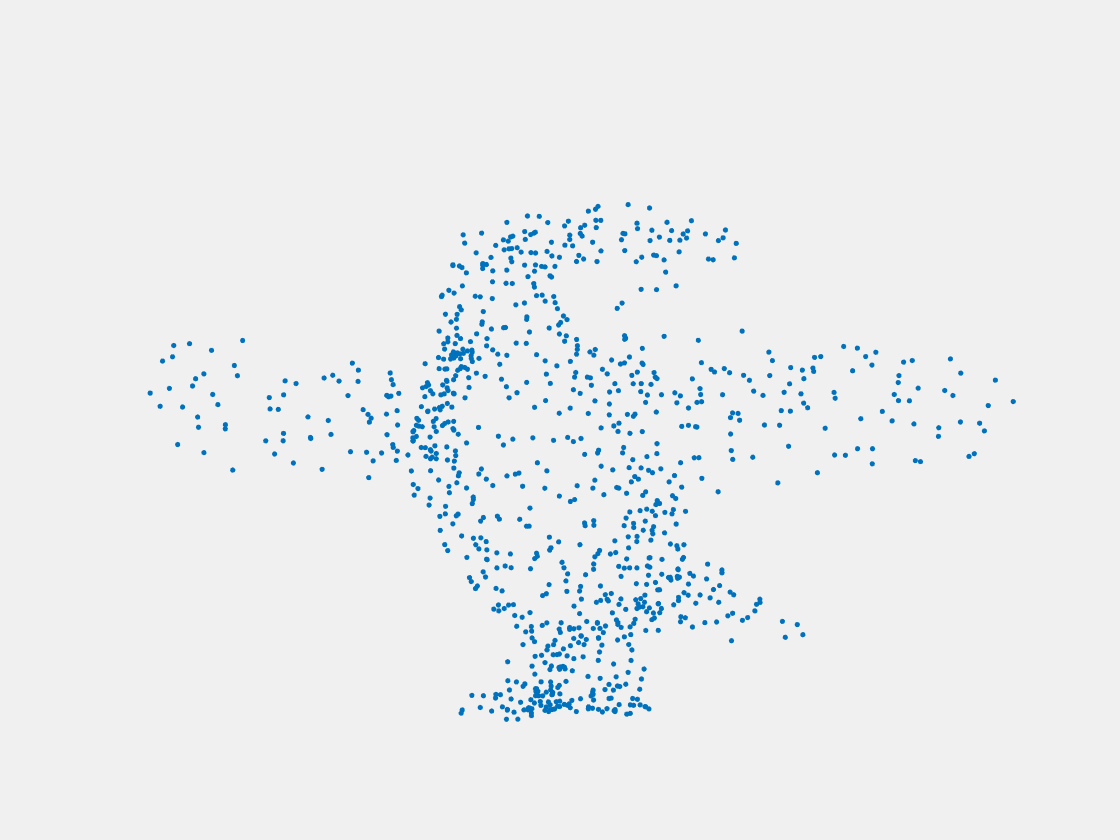

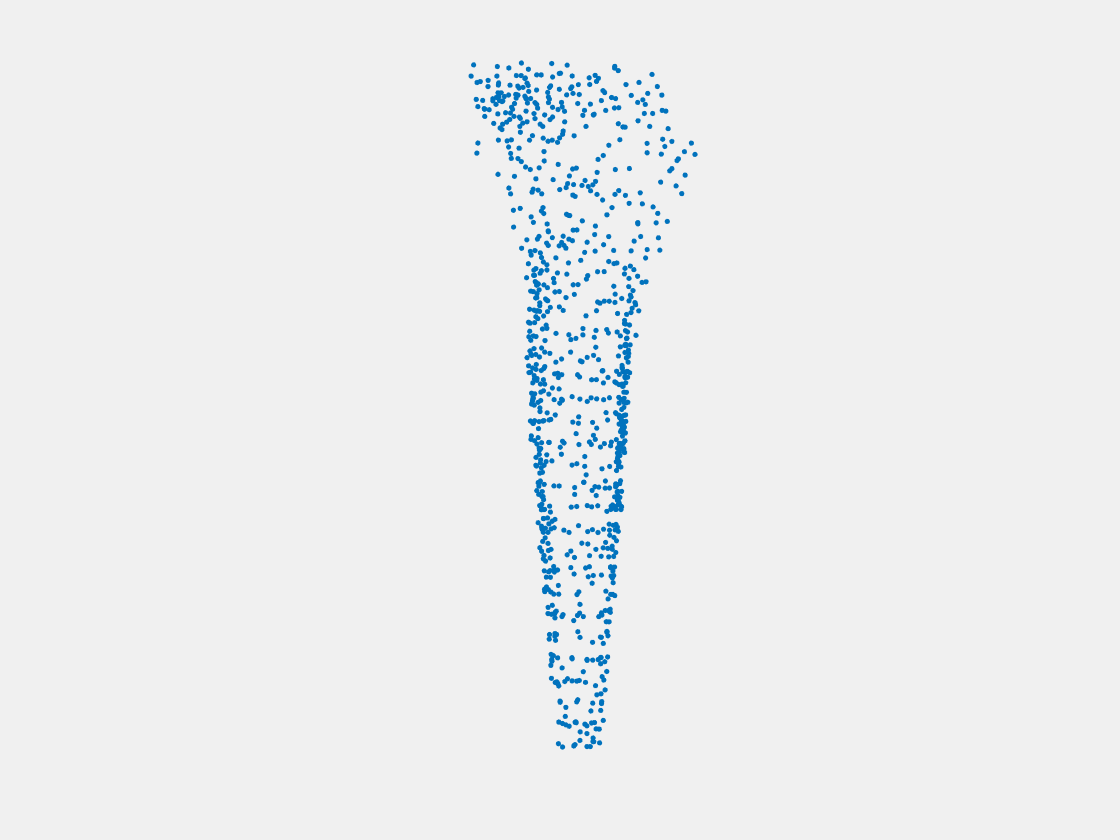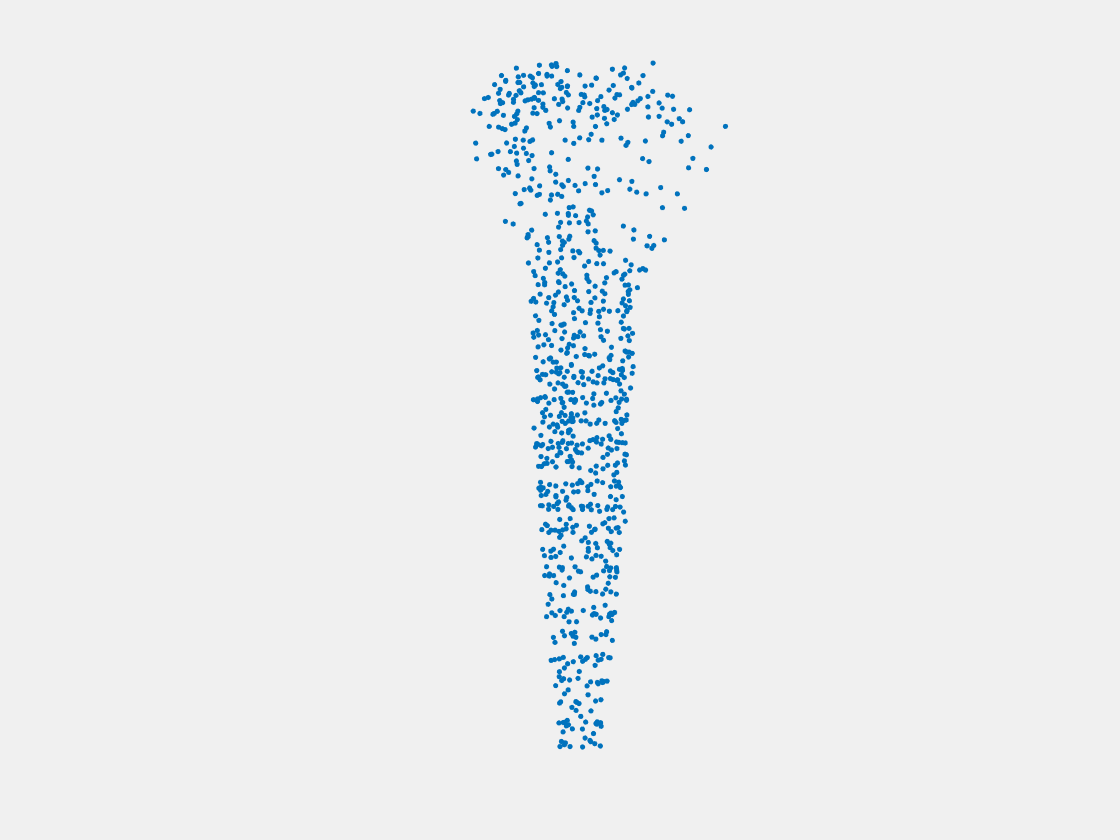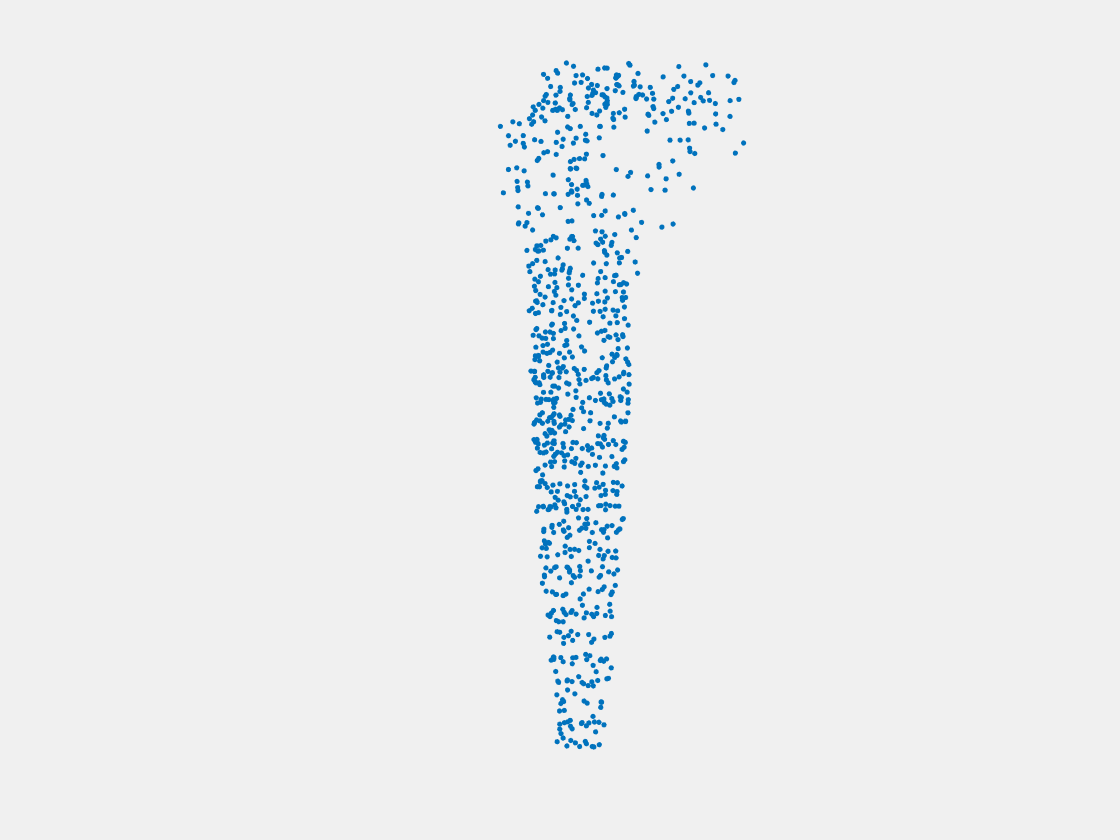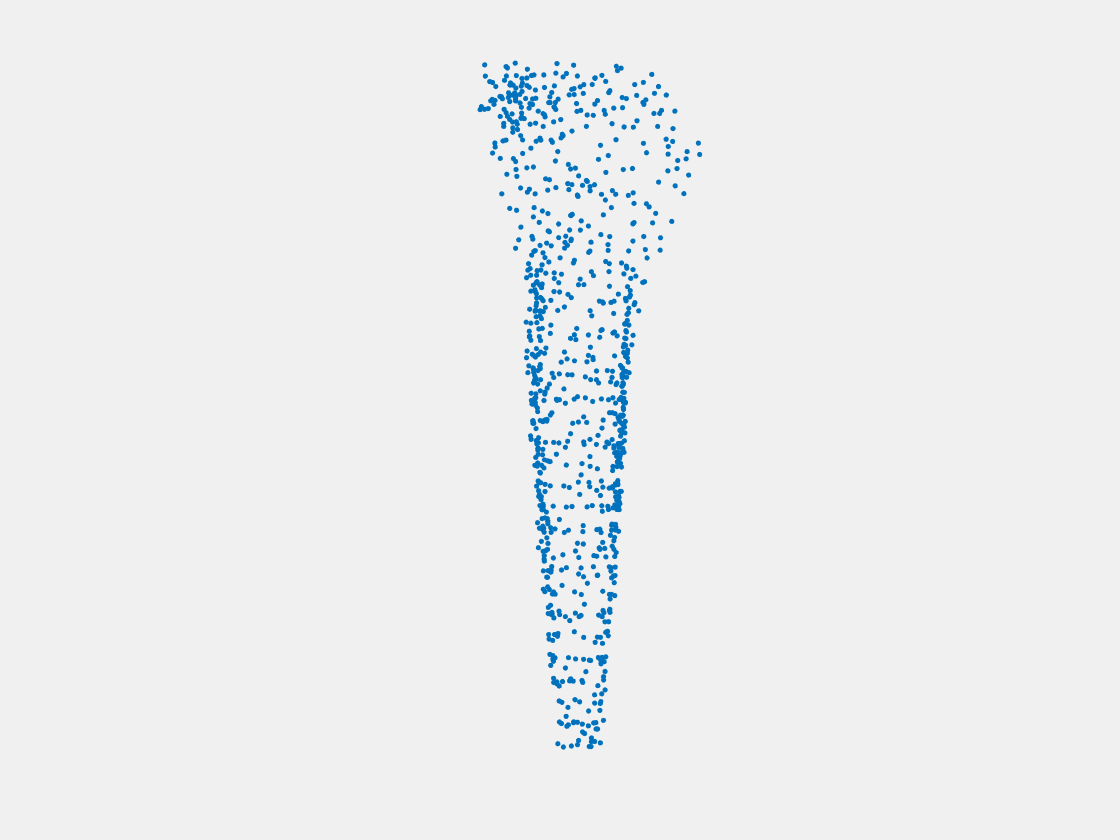

Figure 9: Point clouds of training image generated by PointSetNet fine-tuned with multiple (image, point cloud) pairs for each Pokemon. Left to right, top to bottom: Charmander, Blastoise, Pidgeot, Raticate, Arbok, and Pikachu.
Testing Samples
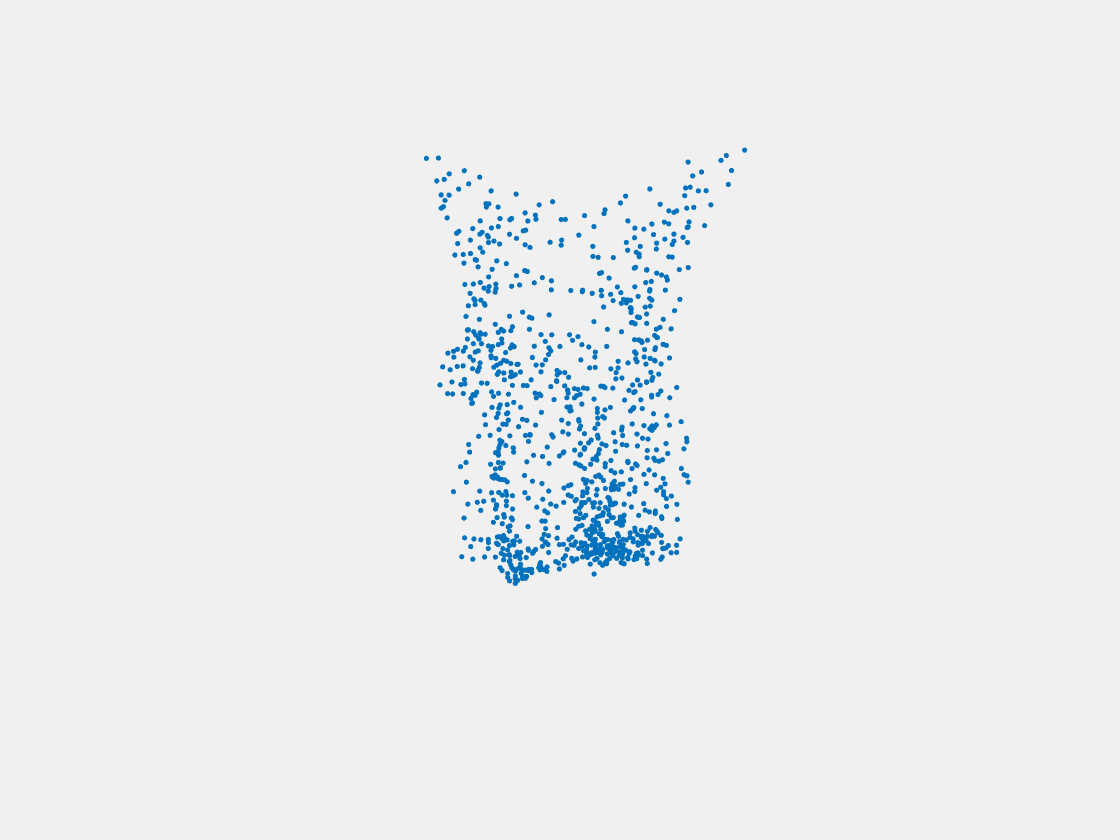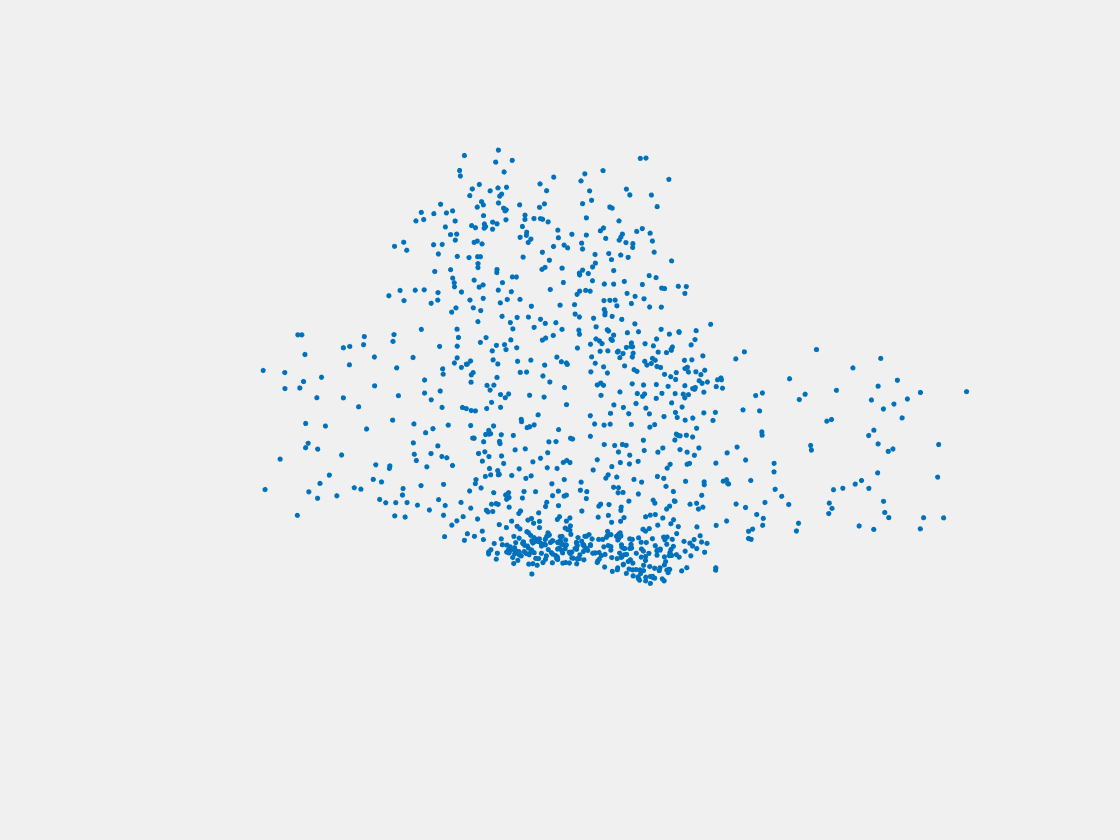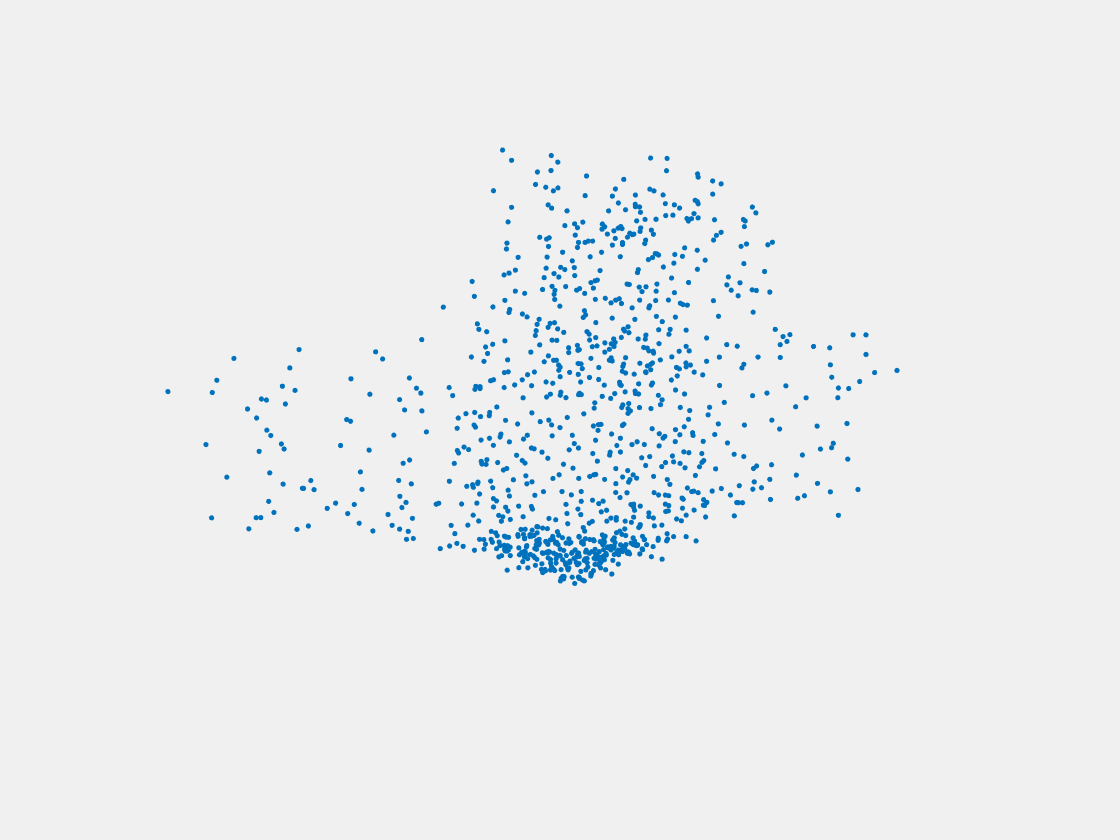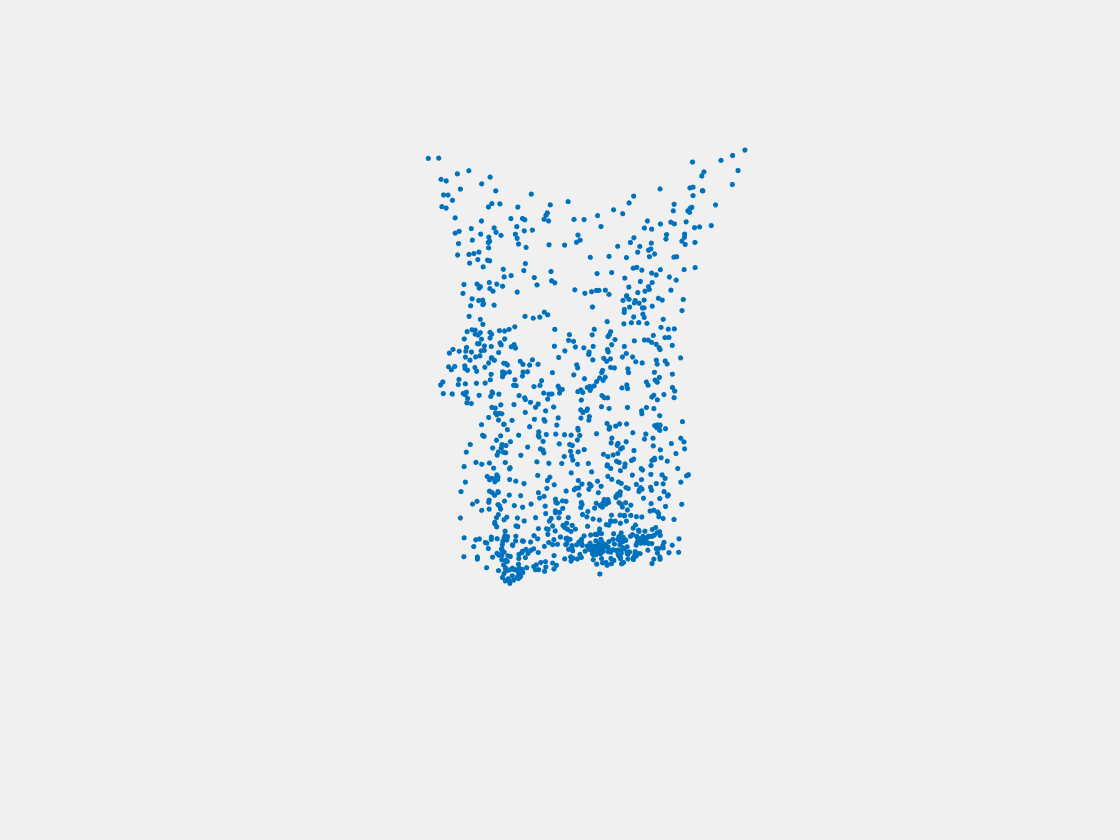





Figure 10: Point clouds of testing image generated by PointSetNet fine-tuned with multiple (image, point cloud) pairs for each Pokemon. Left to right, top to bottom: Pikachu, Farfetch’d, Dewgong, Gengar, Snorlax, and Mew. The point cloud predictions of training images look perfect while the point cloud predictions of testing images diffuse at the object-camera line-of-sight direction.
PointSetNet with Multi-view Pooling Layers (MVPNet)

To train a network that can handle V view images, our first attempt is to add “view pooling” layers between the encoder and the decoder. The reason for this design is described as follows. Each view image (e.g., 192x256x3 tensor), when passed through the encoder, is transformed into a feature tensor (e.g., 3x4x128 tensor). The feature tensors of different view images from a common object can be regarded as similar features, but extracted from different views. Here, our aim is to aggregate those V feature tensors into one, then pass it through the decoder to obtain a point cloud that includes information from all views. We consider that this aggregation procedure can possibly be achieved by a pooling operator.
For implementation, we add this pooling layer to every stages between the encoder and the decoder (as illustrated by the dashed line in the figure above, so there are four additional pooling layers). Each input sample is a set of V view images and its ground truth output is a single point cloud, corresponding to the view point of the first view image. This is intended for the network to learn to always match the view point of the first view.
Training Samples
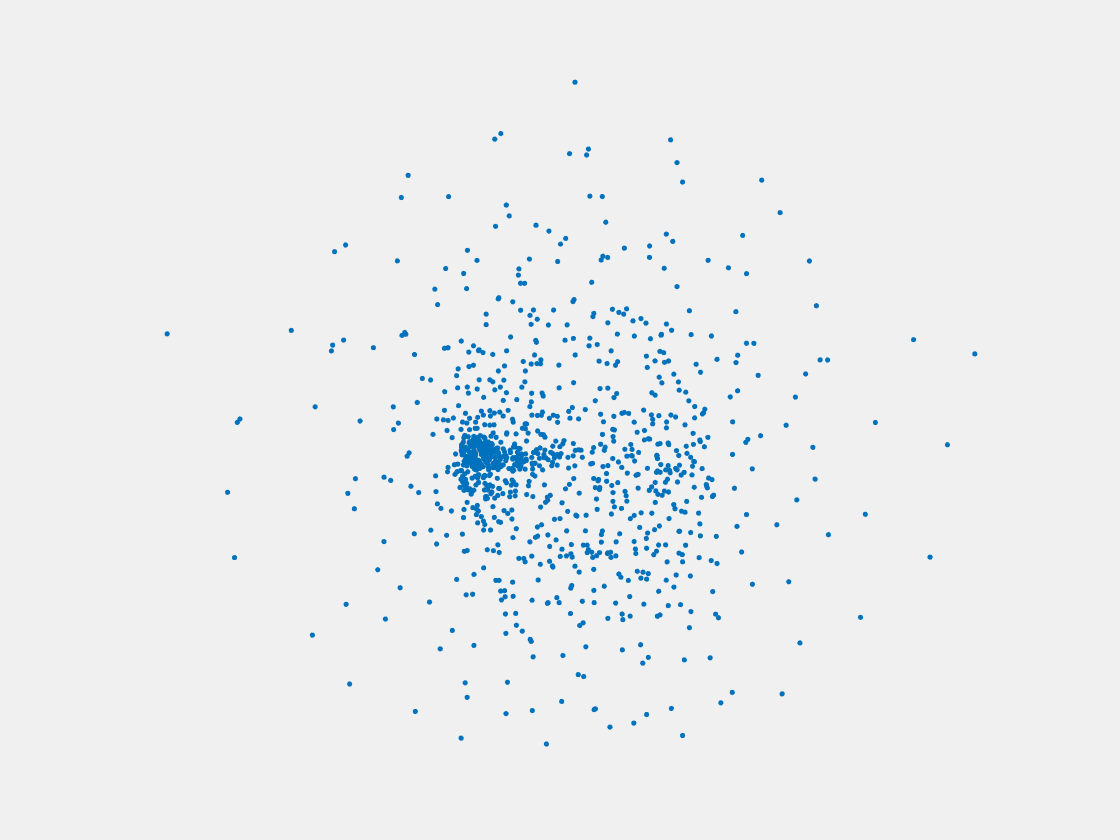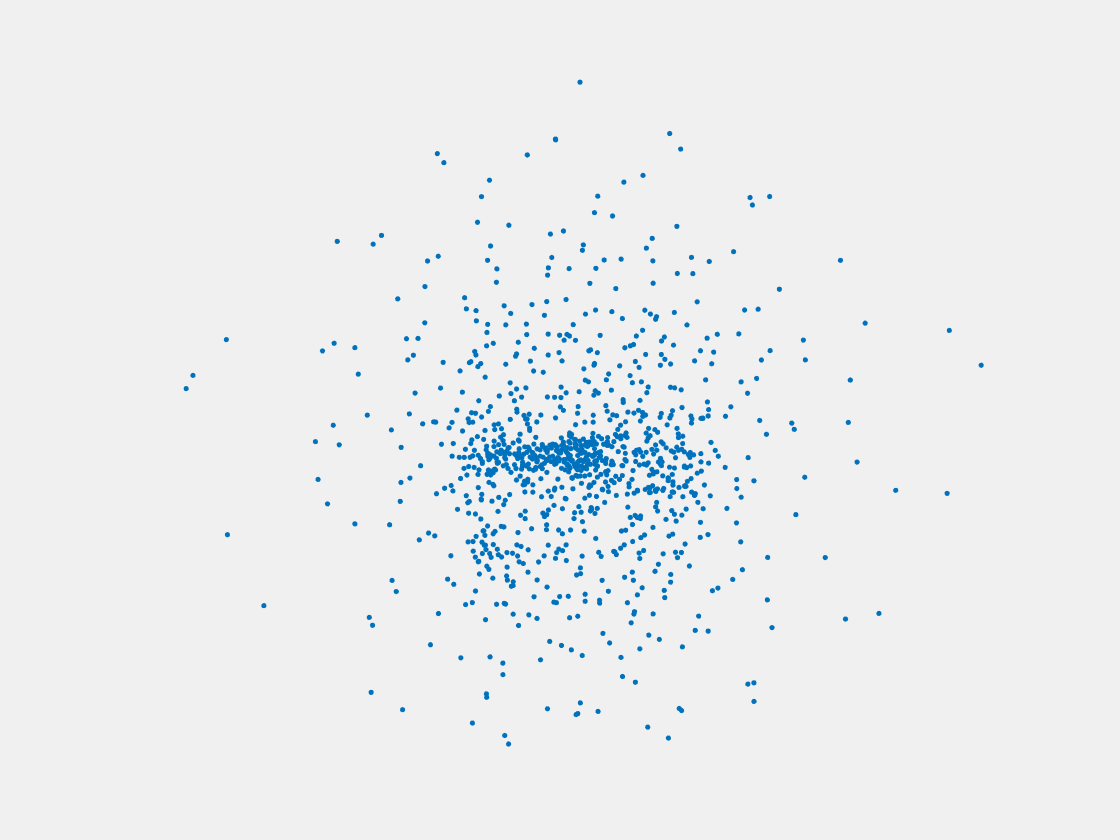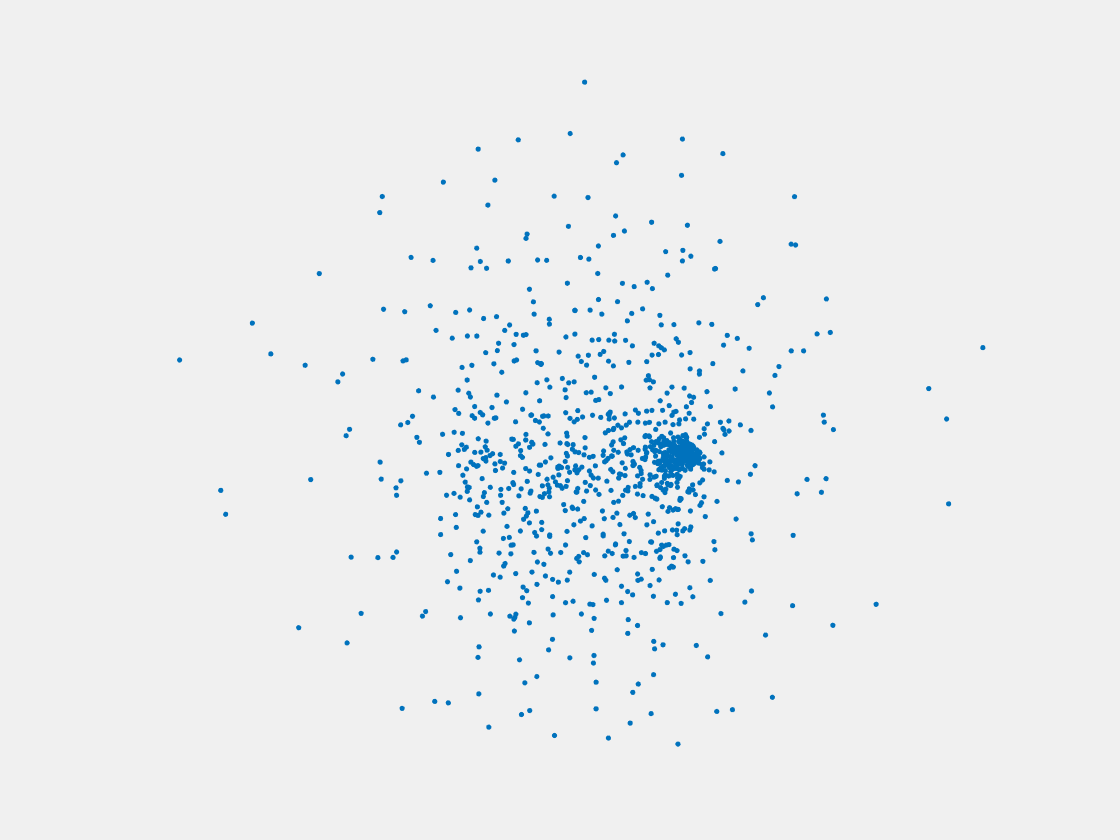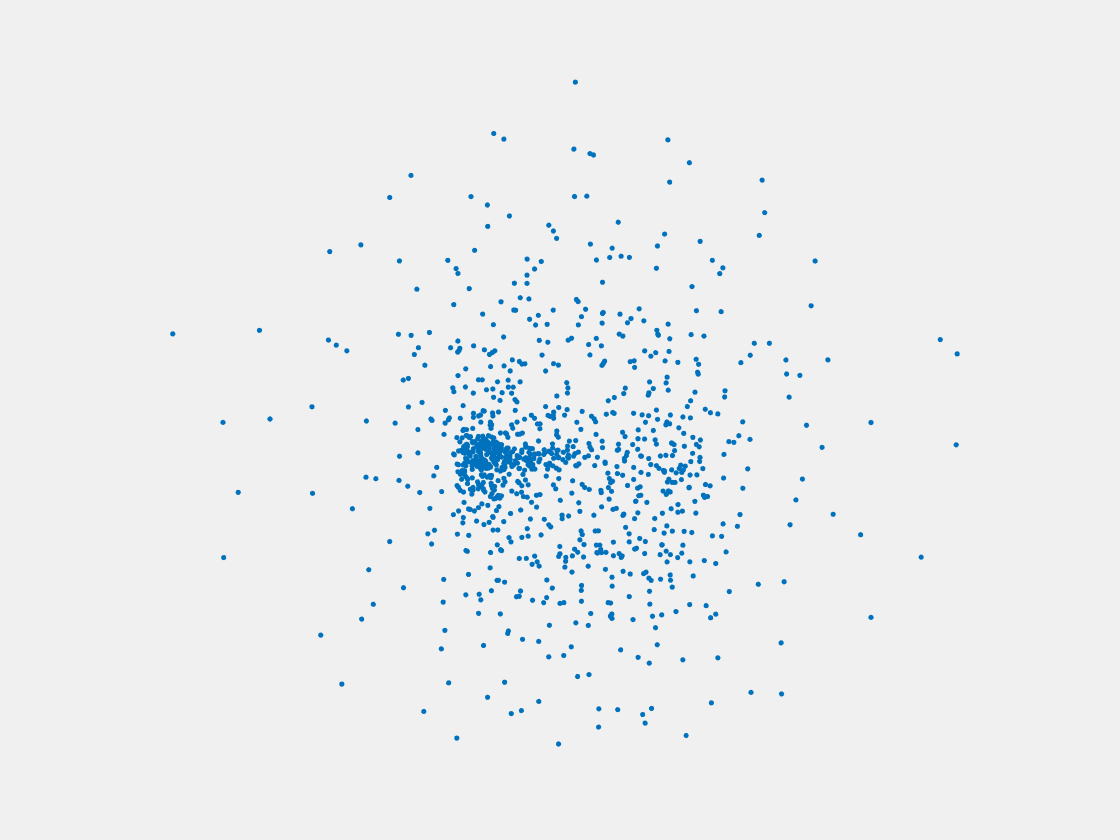
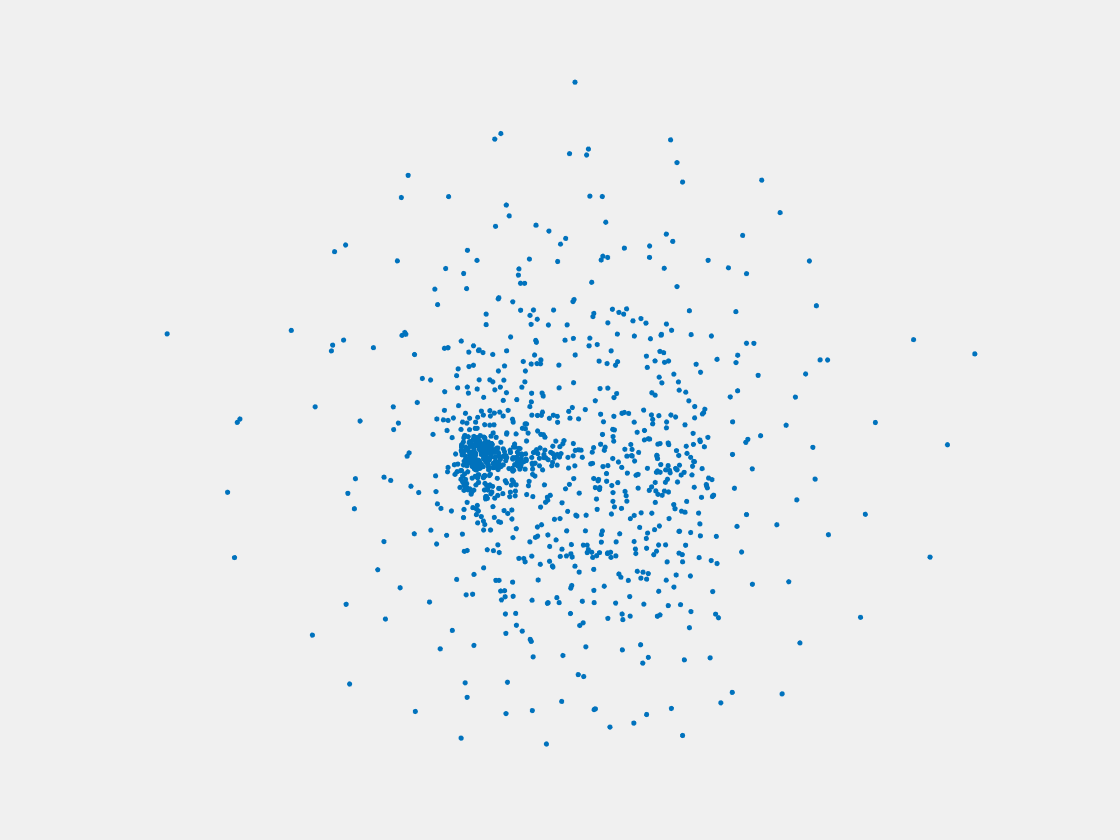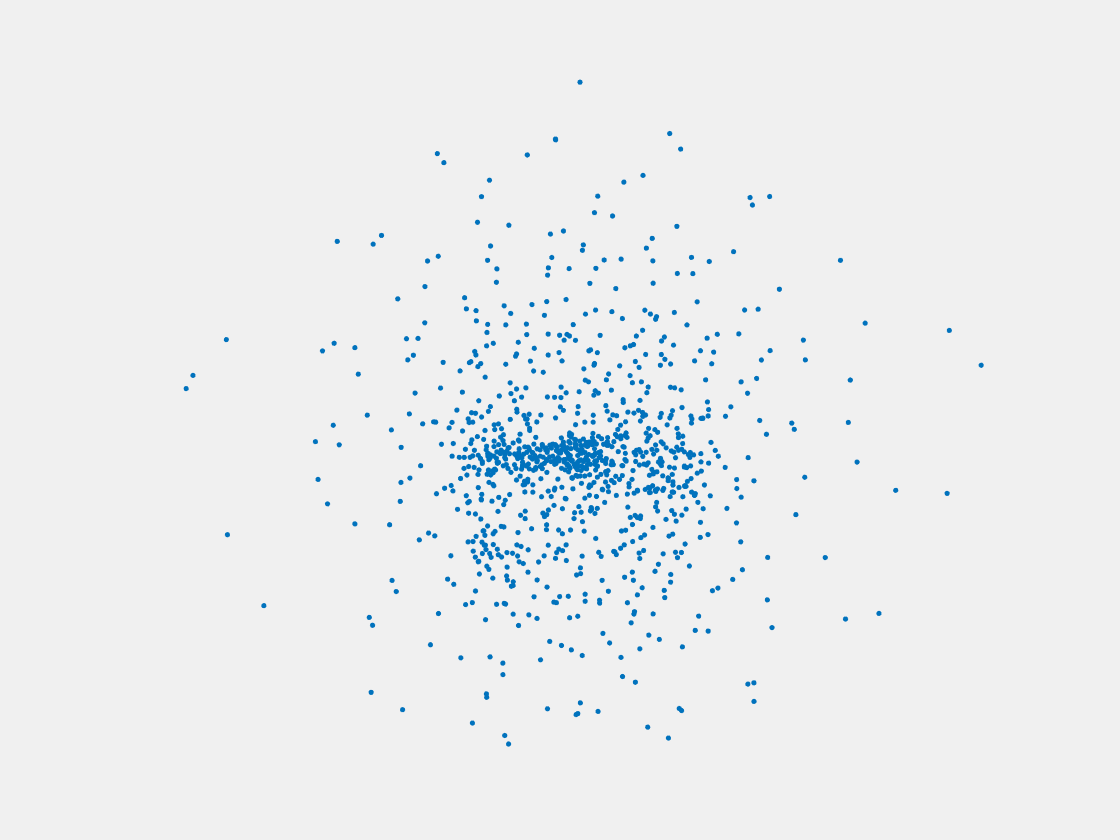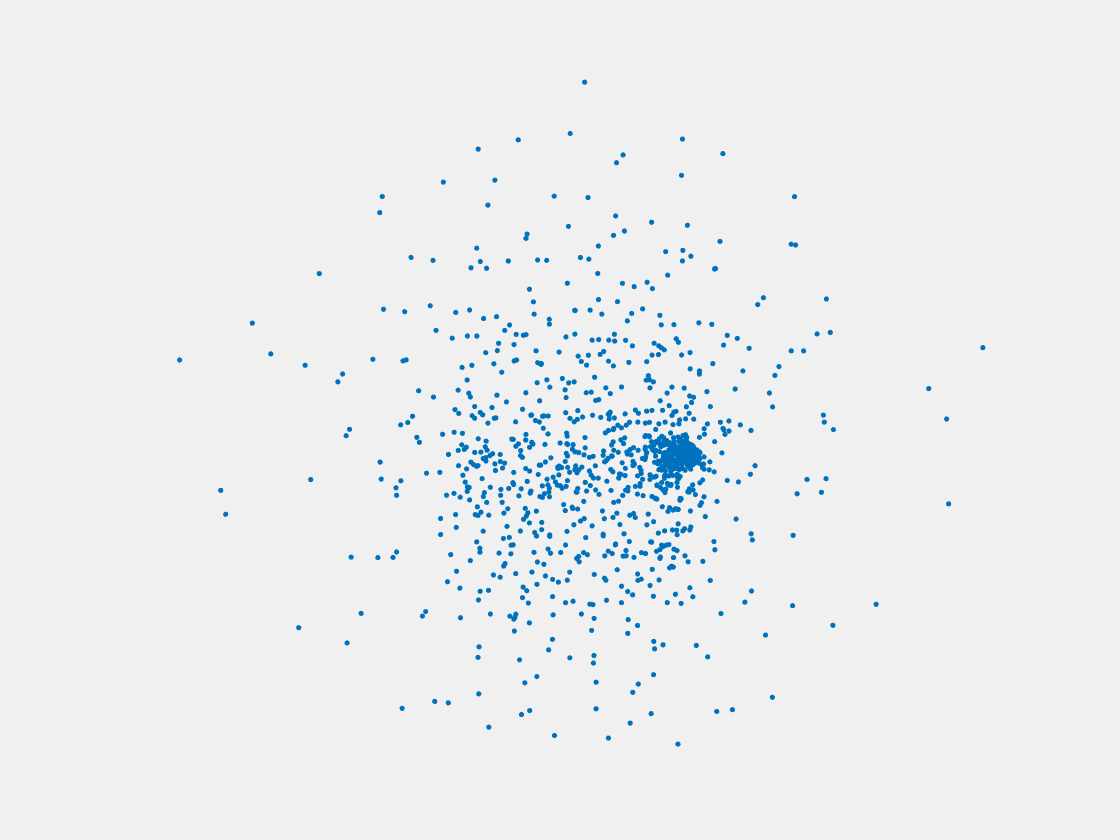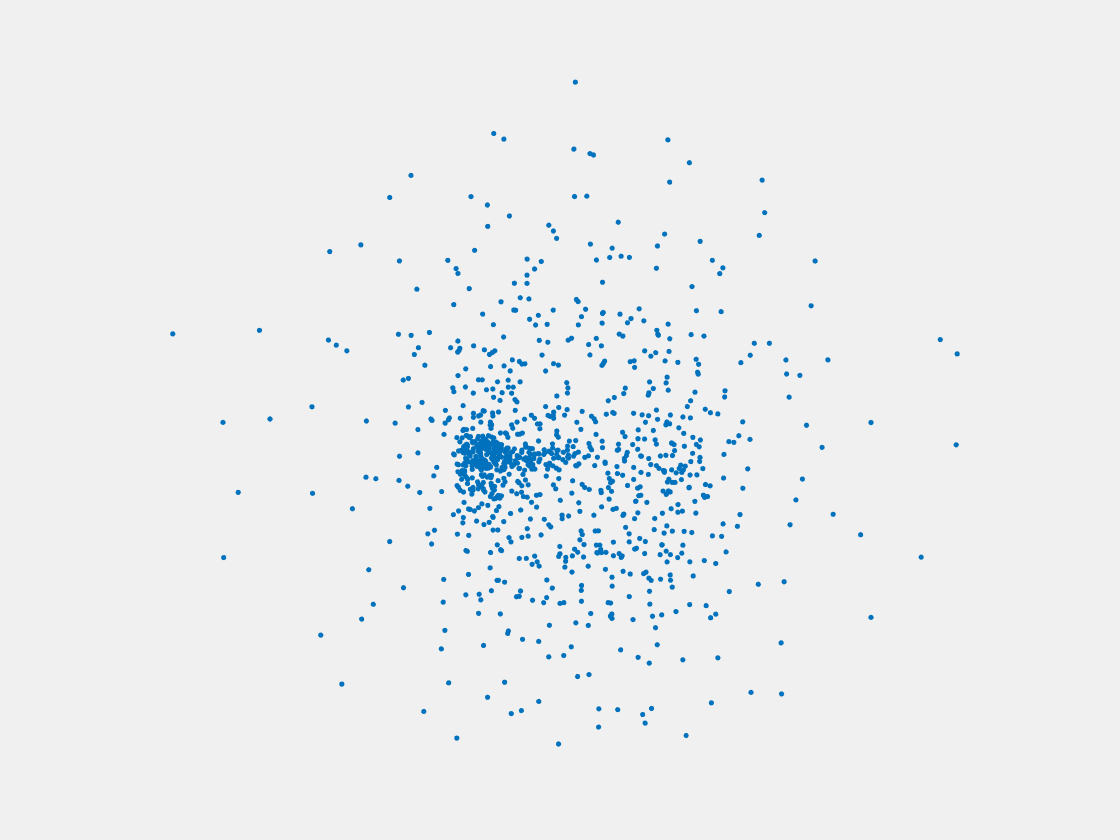
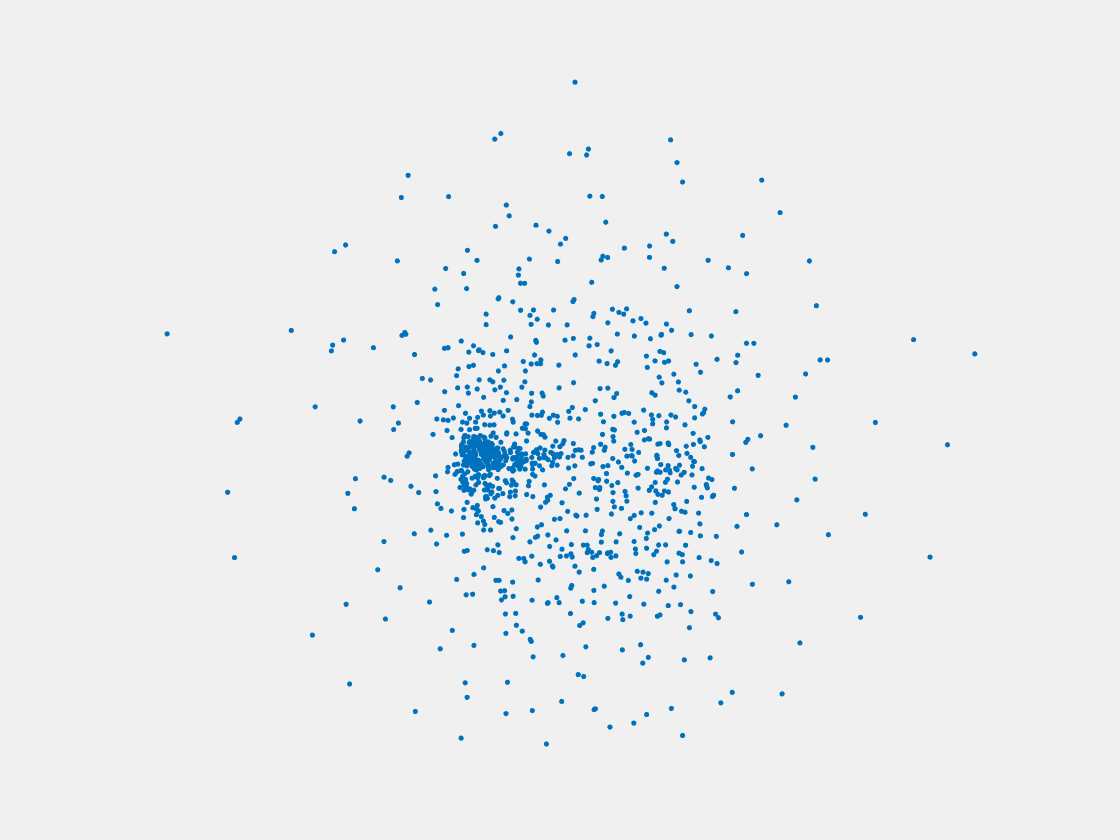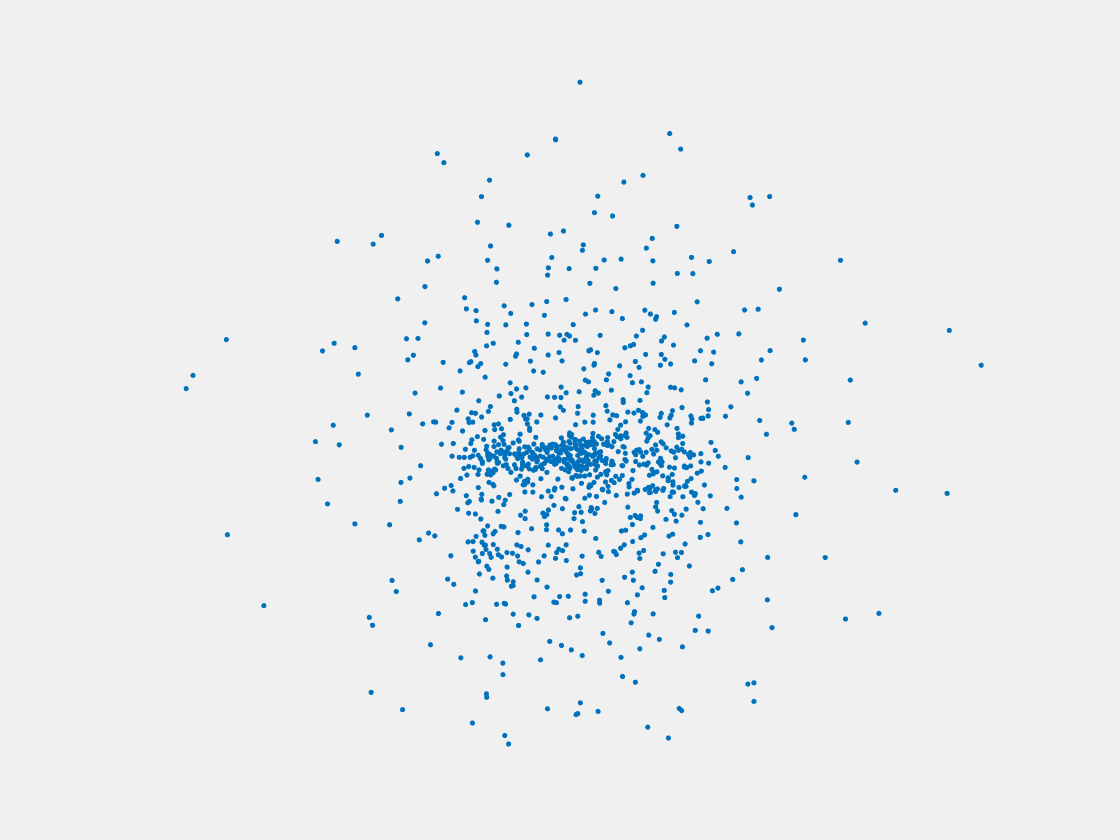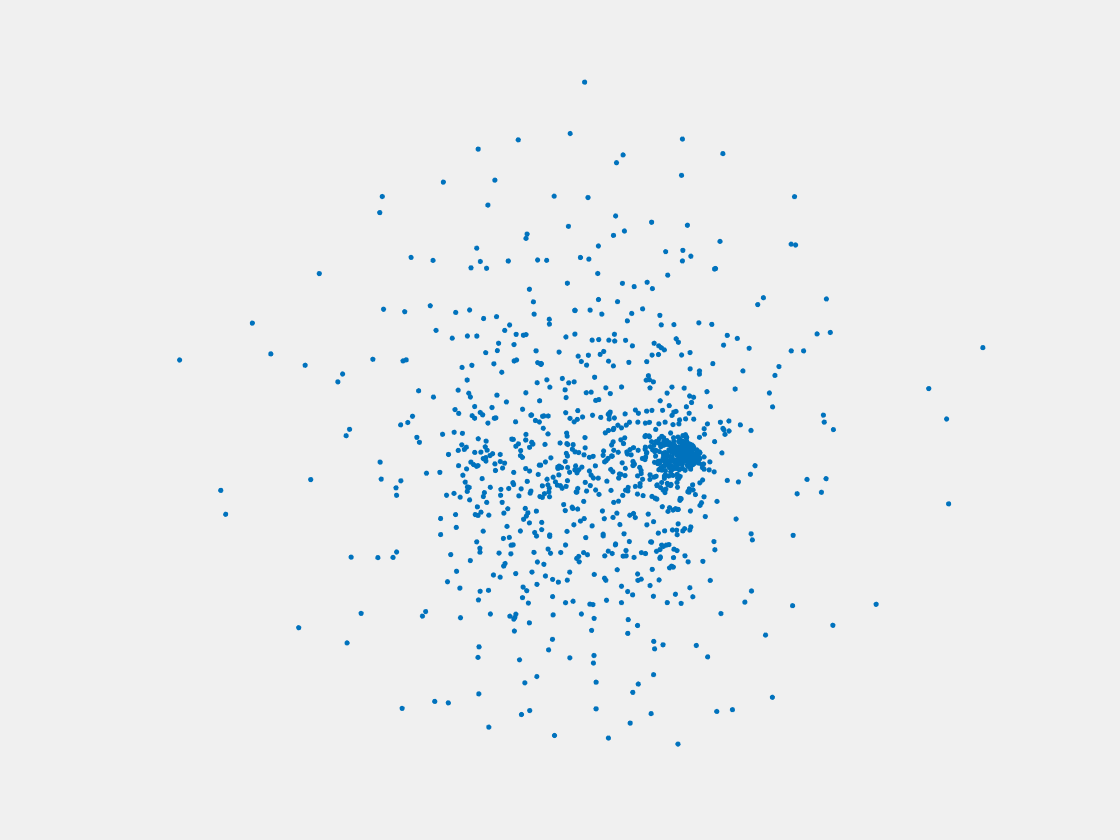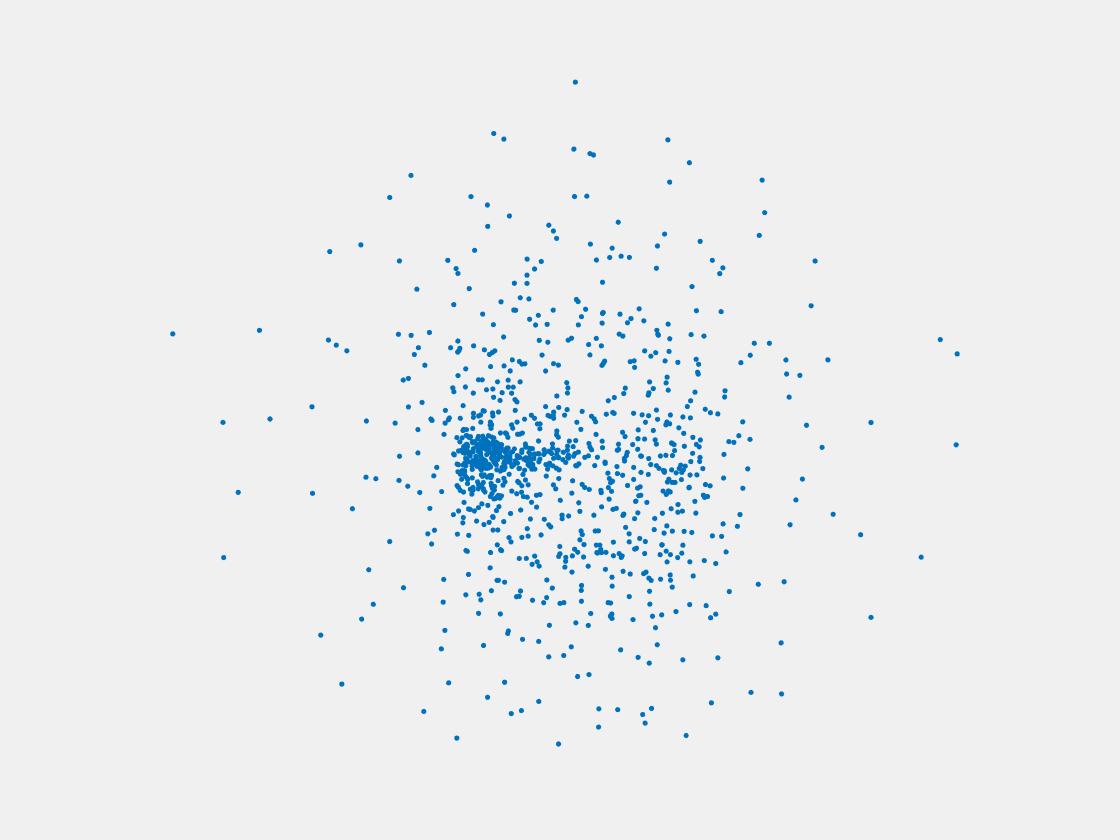
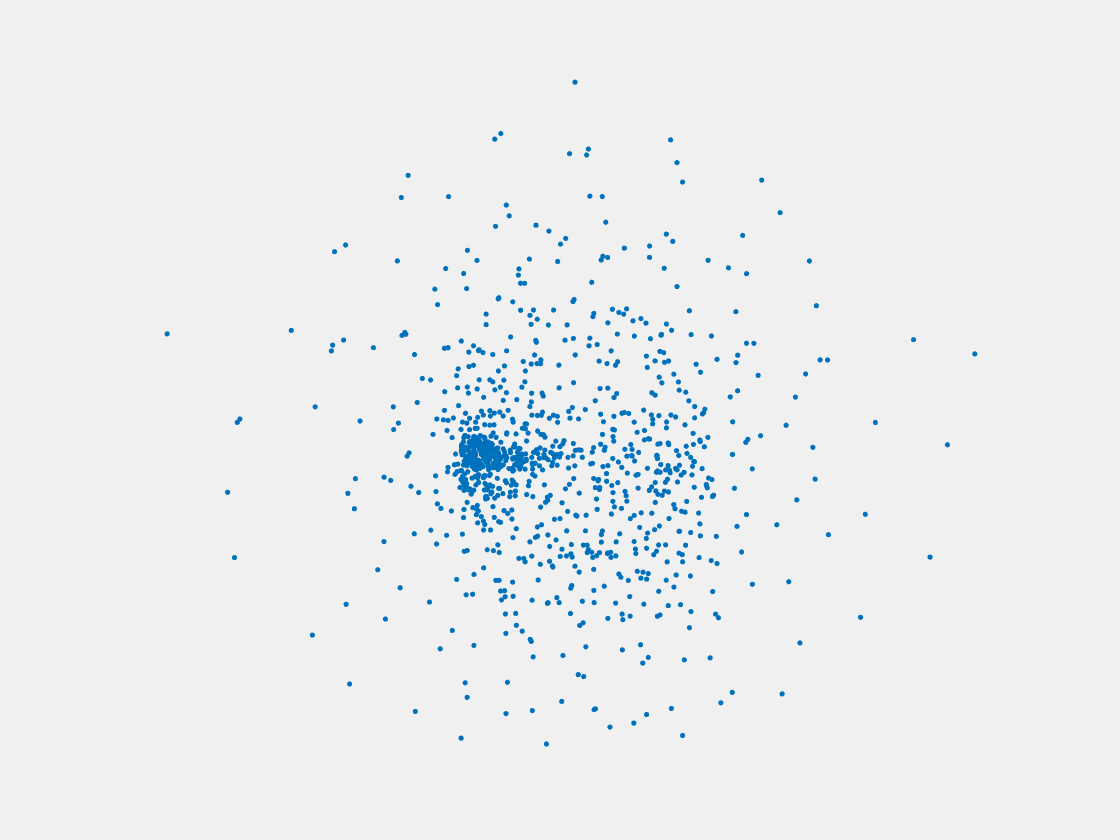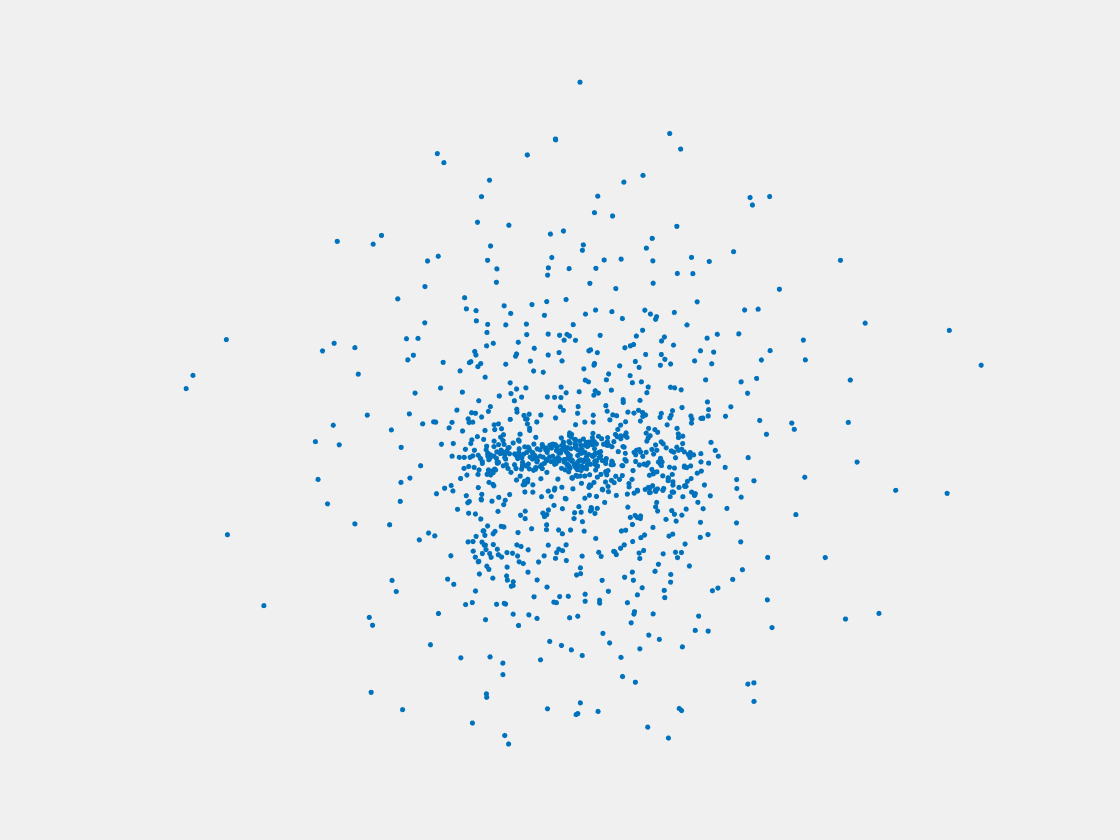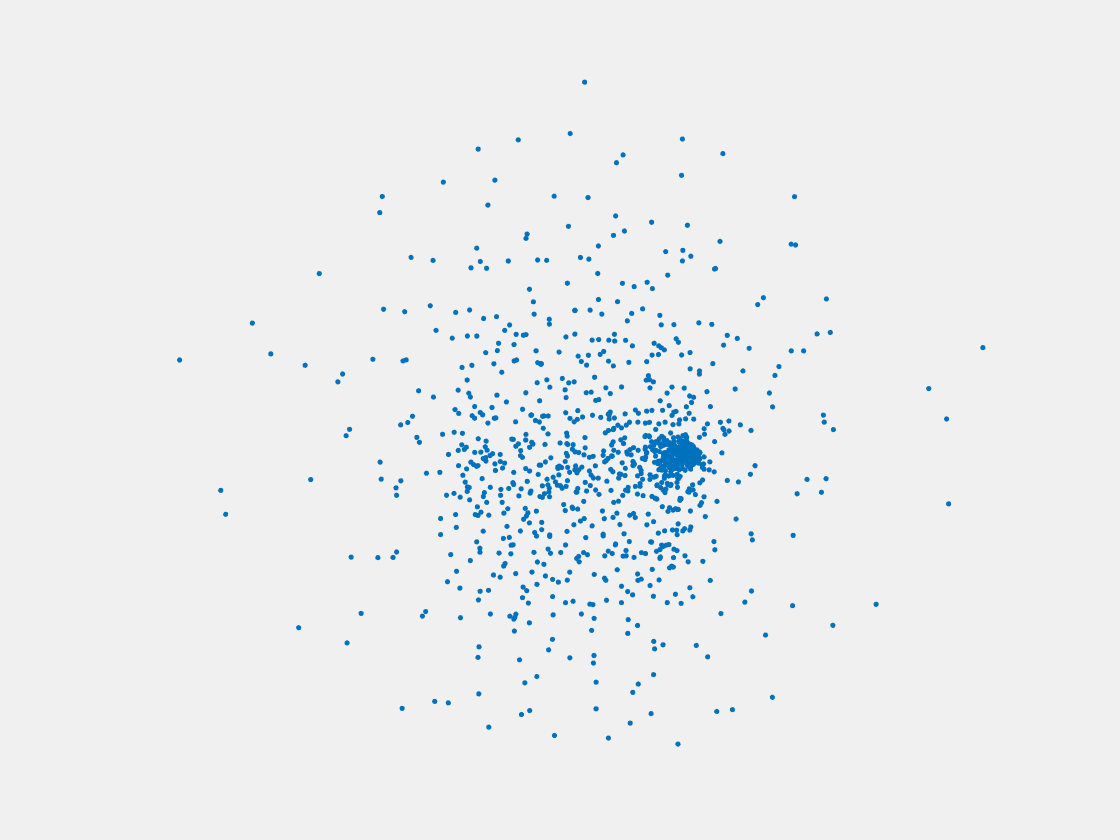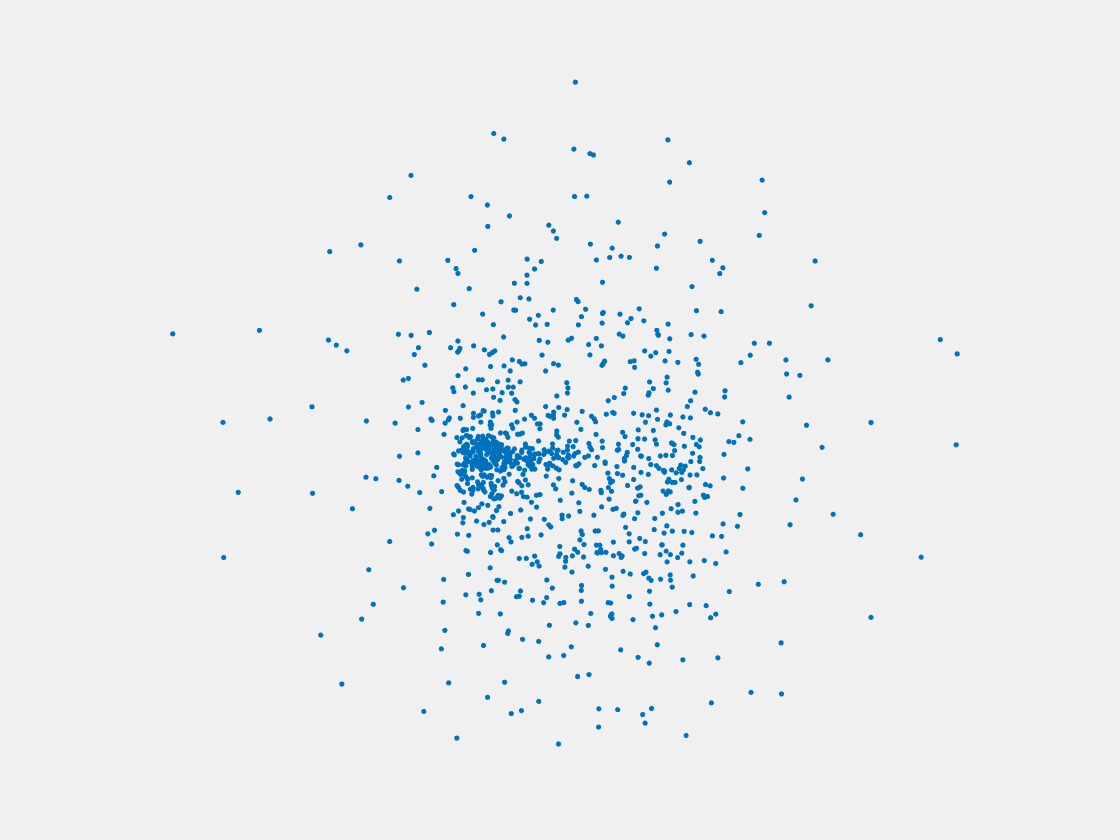
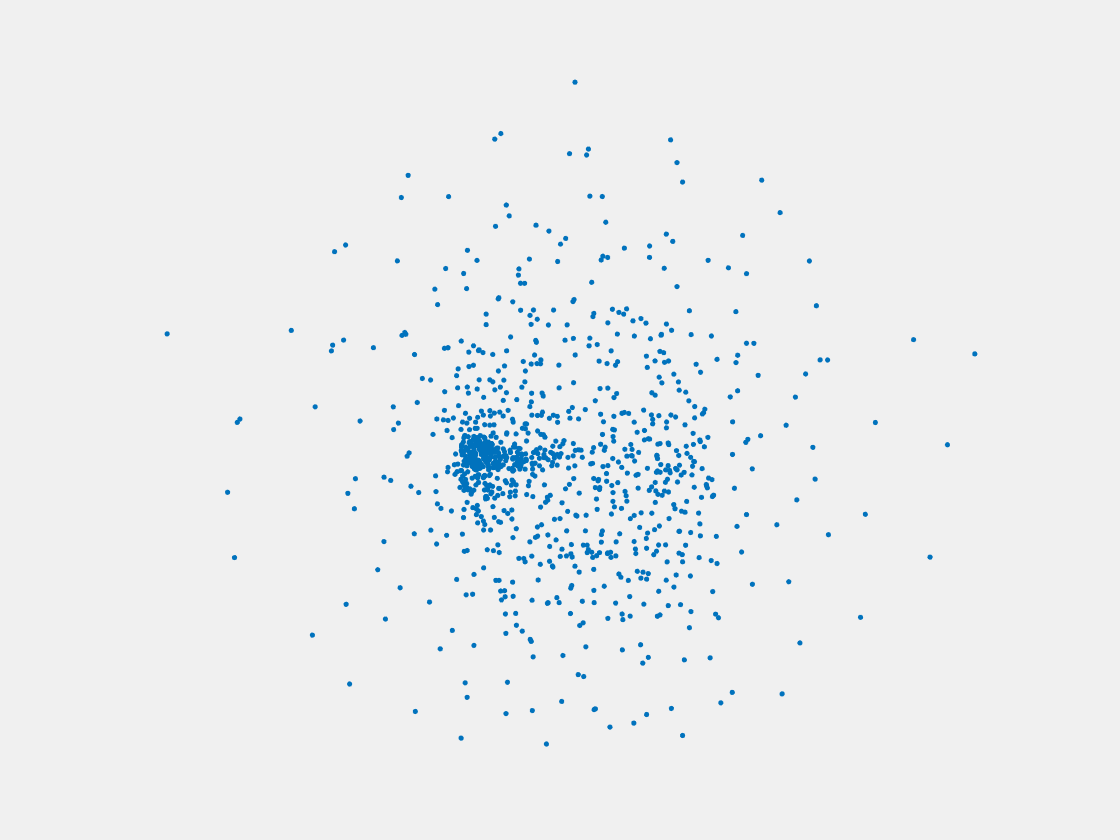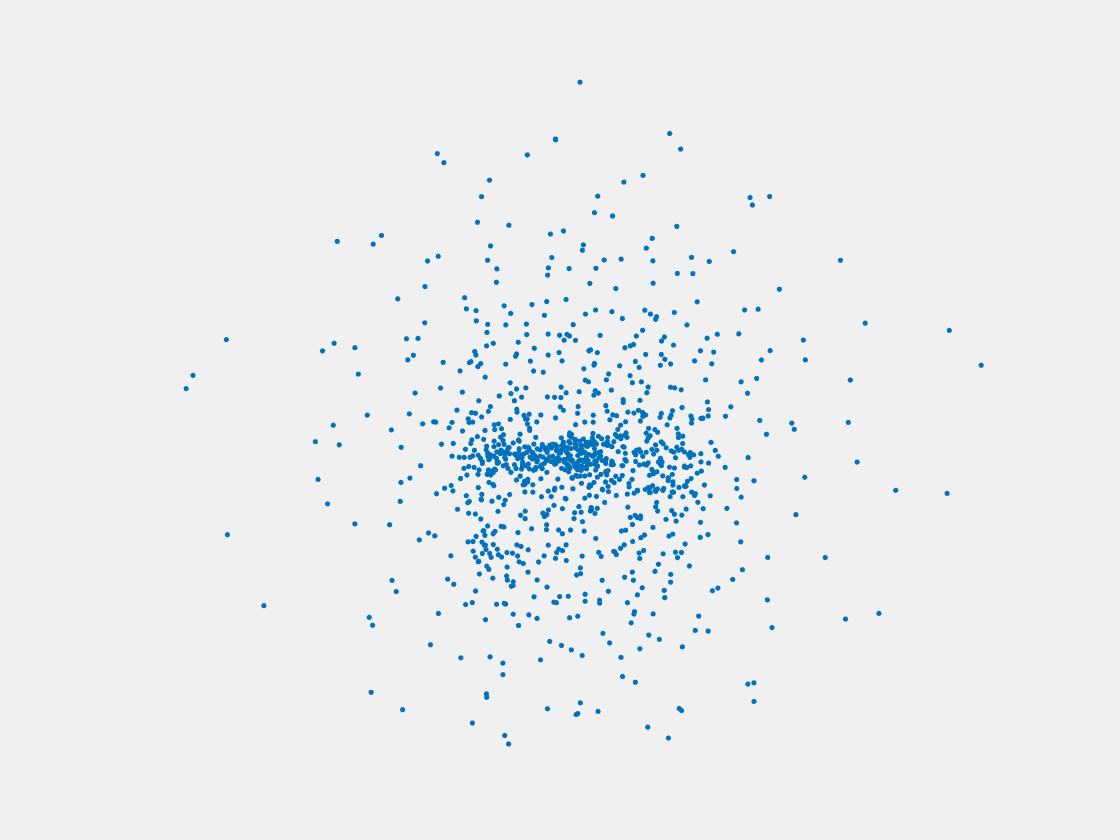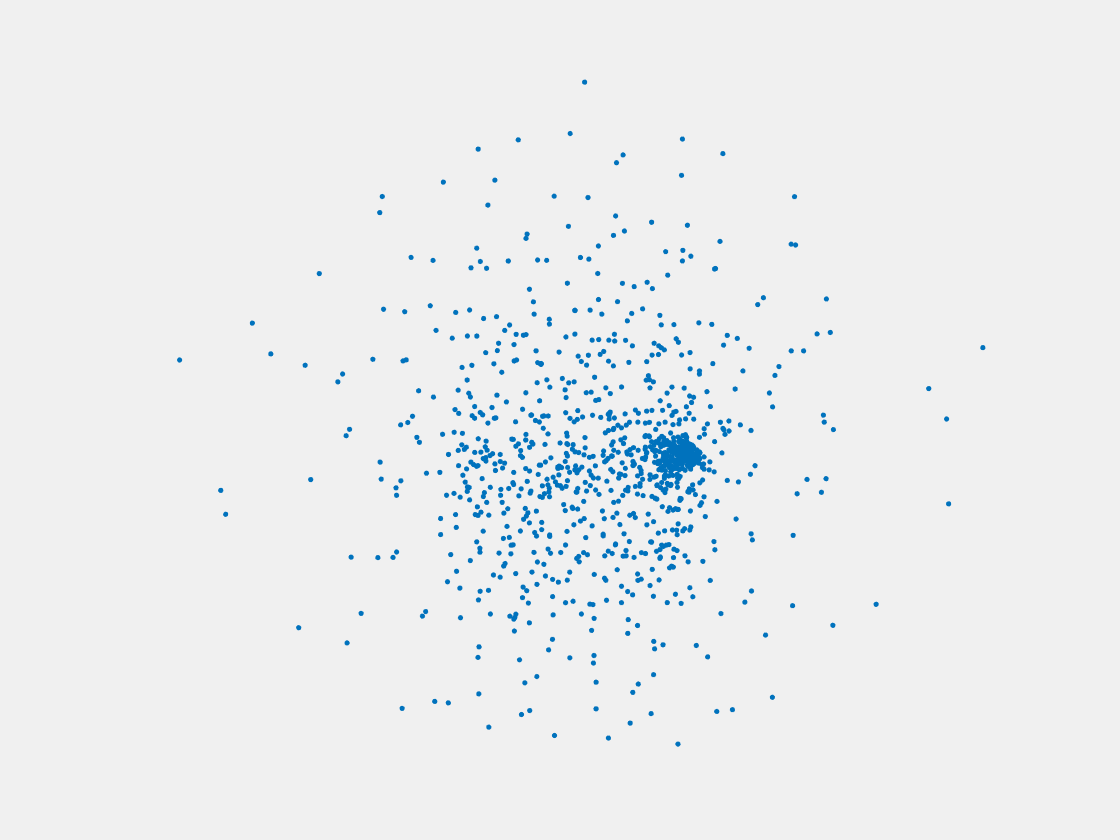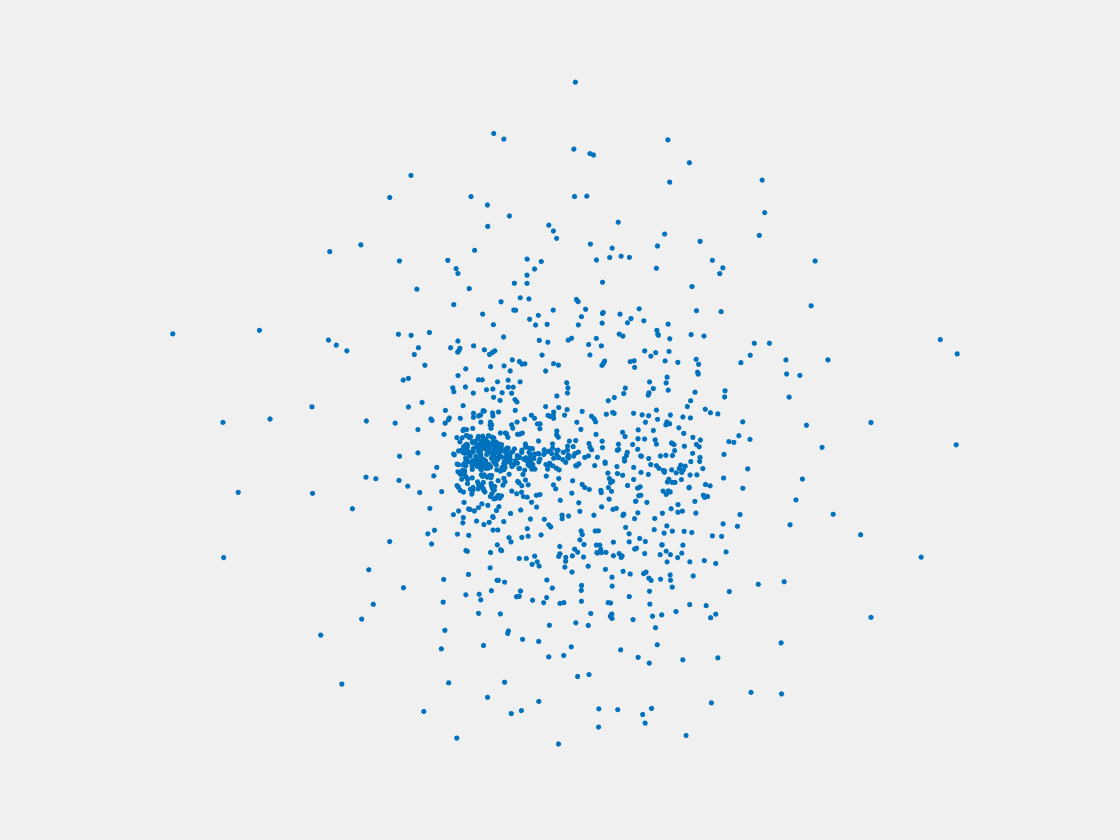
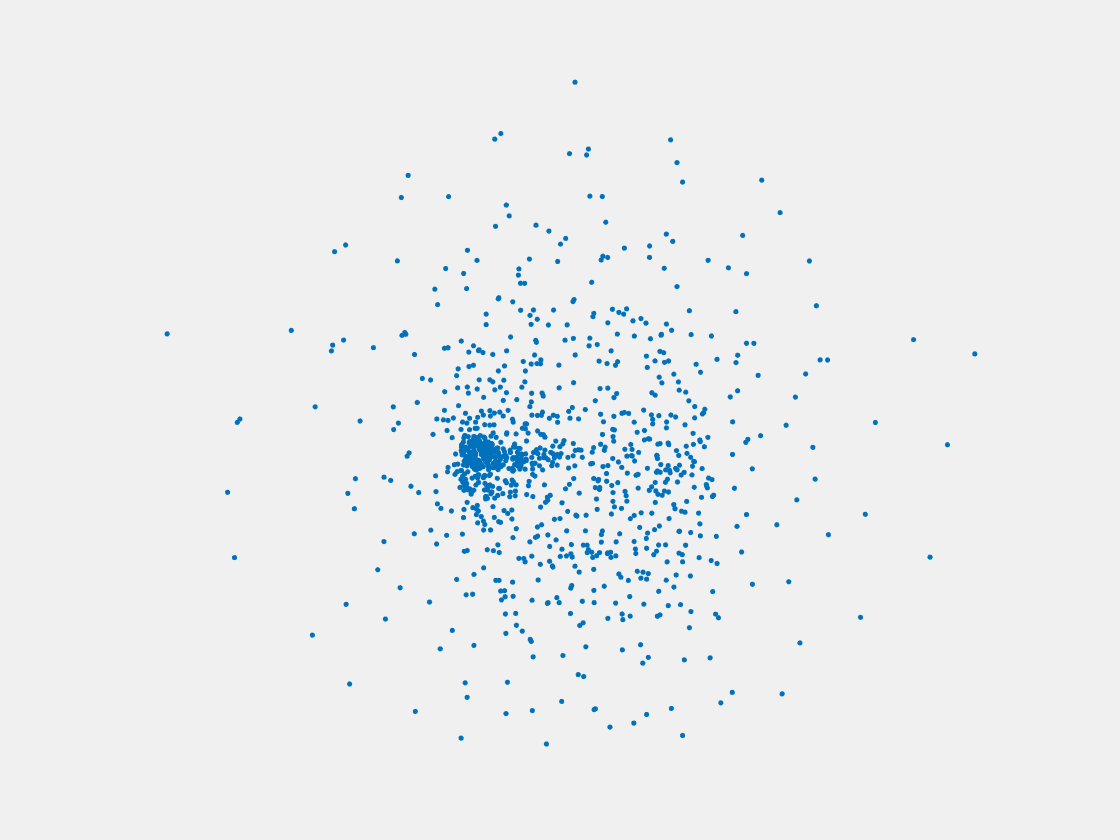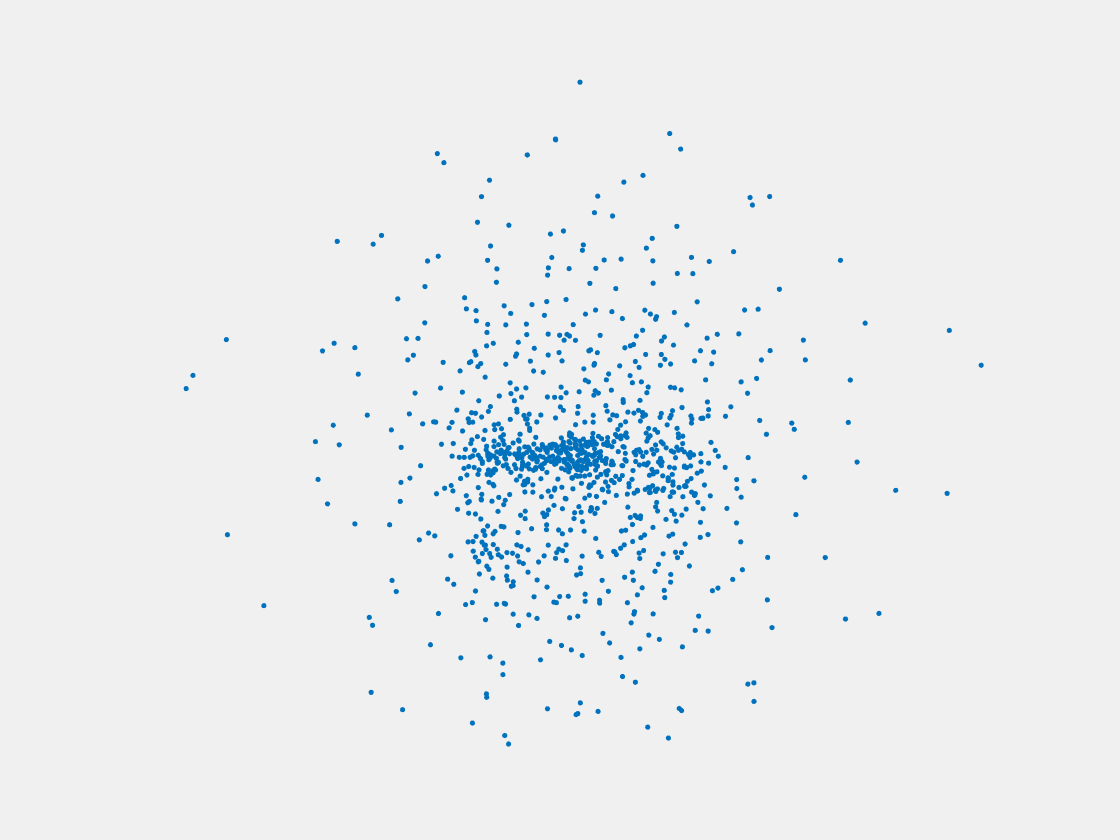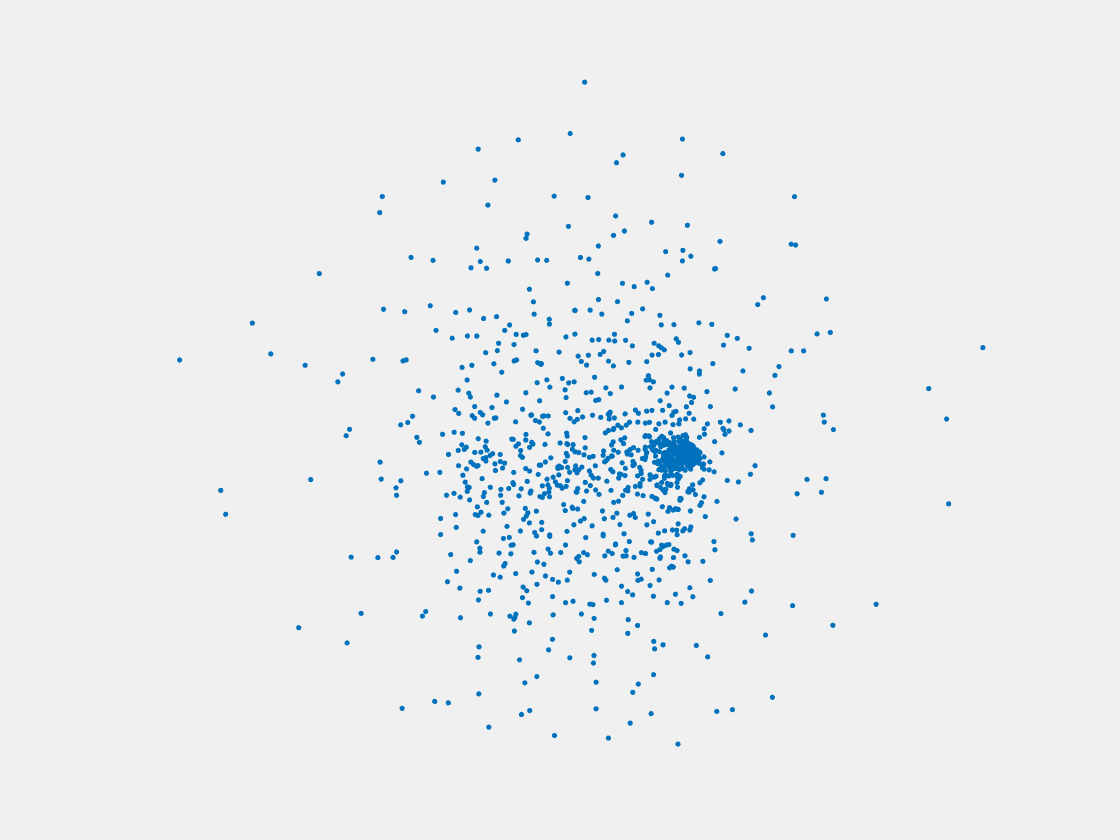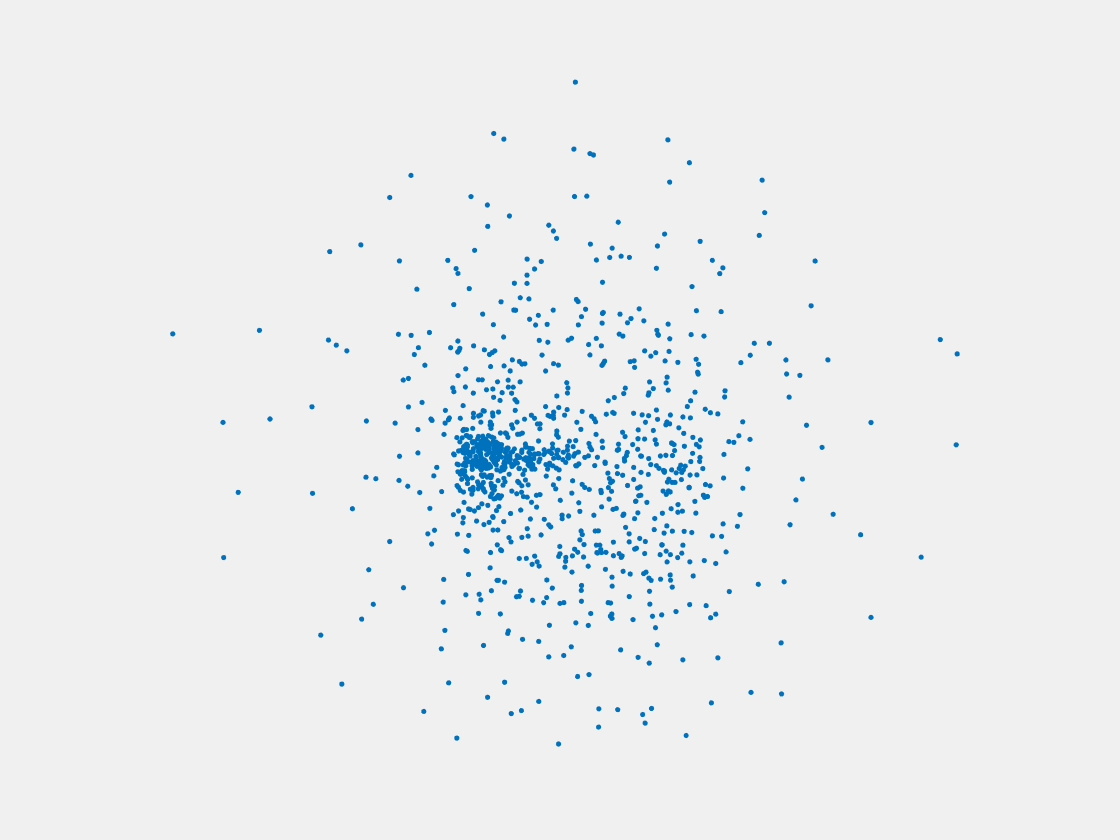
Figure 11: Point clouds of training image generated by MVPNet. Left to right, top to bottom: Charmander, Blastoise, Pidgeot, Raticate, Arbok, and Pikachu.
This model fails even for training data. As can be seen above, all resulting point clouds are sparsely distributed in the whole box region. Observing those results, we have the following conjectures. The max pooling layer simply adds up information from all views, which is probably why the resulting point clouds are more rounded than expected. Instead, what would be preferable is to keep overlapped information from images with similar view angles, and forget local information from previous view images. Thus, what would be left is the common information shared by many view angles, which is more relevant because the desired point cloud is shared by all view images.
Multi-view Selective Updating with LSTM Layers (MuSullyNet)
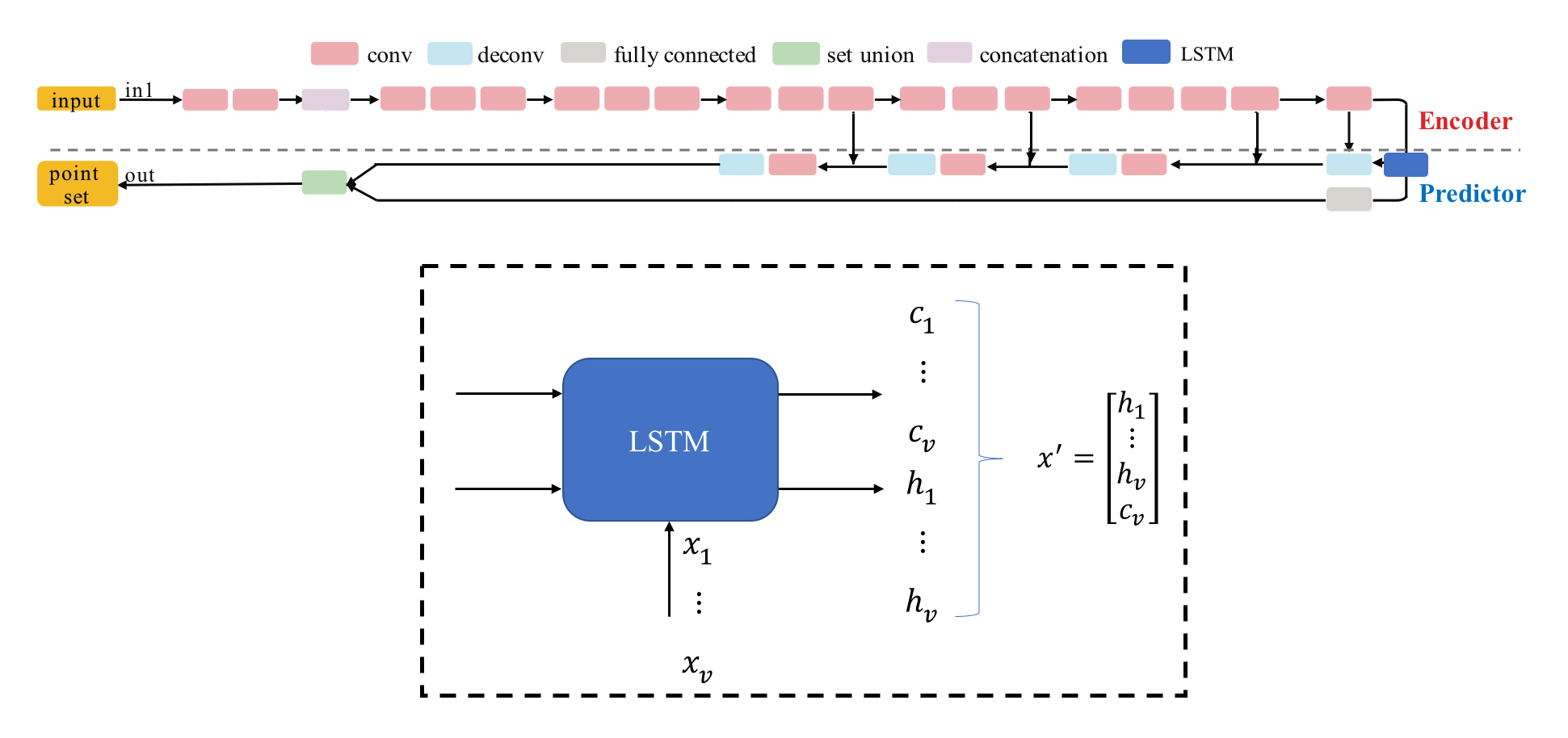
To implement such a layer with the ability to forget, we consider using long short-term memory (LSTM) layers instead of a max pooling layers because LSTM layers are able to forget unnecessary information. Here, we design a new architecture which can capture the common features of multi-view images: Multi-view Selective Updating with LSTM Layers (MuSullyNet). The details of our design will be shown below. Part of the design is also inspired by [2].
Before the LSTM layer, the encoder extracts high level features from eqaully phase-shifted multi-view images. Then we sequentially feed these features into the LSTM layer. We hypothesize that outputs of LSTM layer contain distinct information of encoded features from different viewpoints while the last hidden state captures 3-dimensional common structure of the Pokemon which is hidden in each of the multiview image. Therefore, we stack up these variables into a vector which is then fed into the input of the predictor.
Version 1
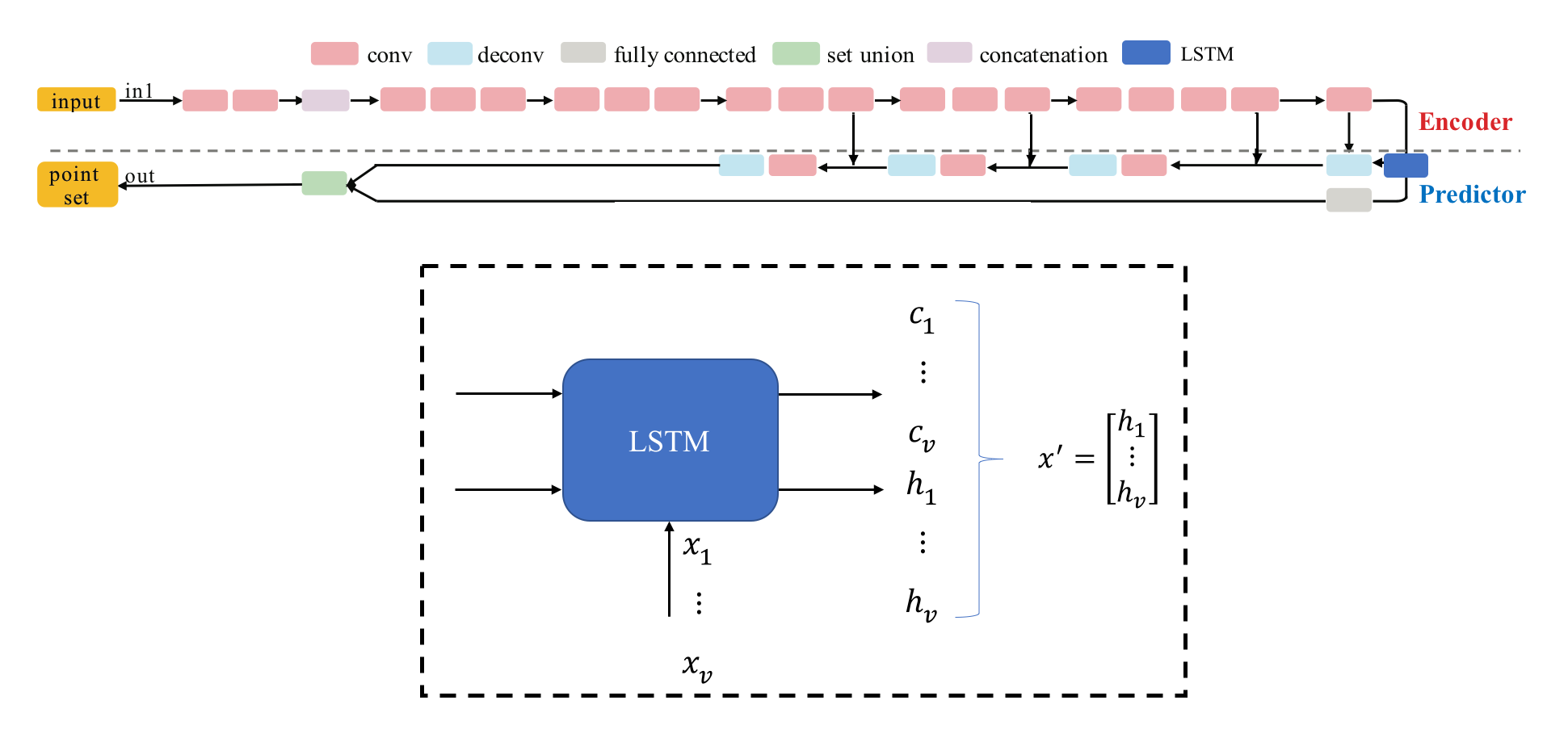
Training Samples



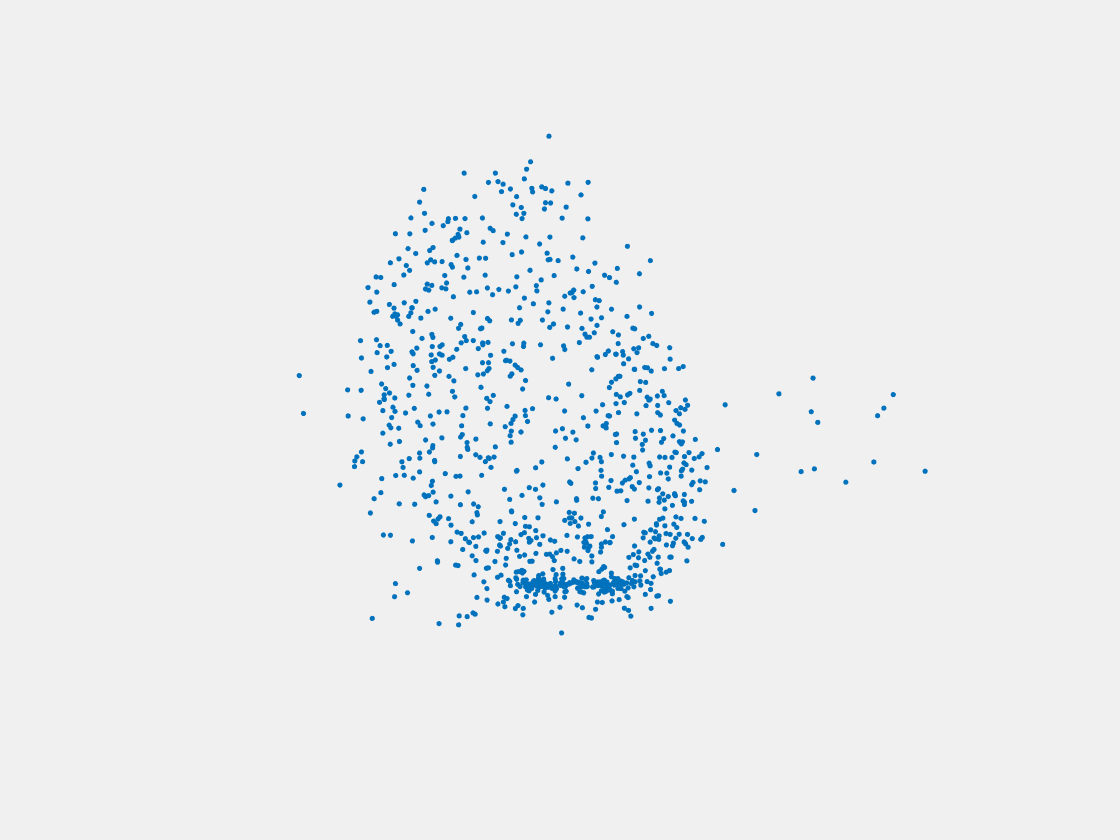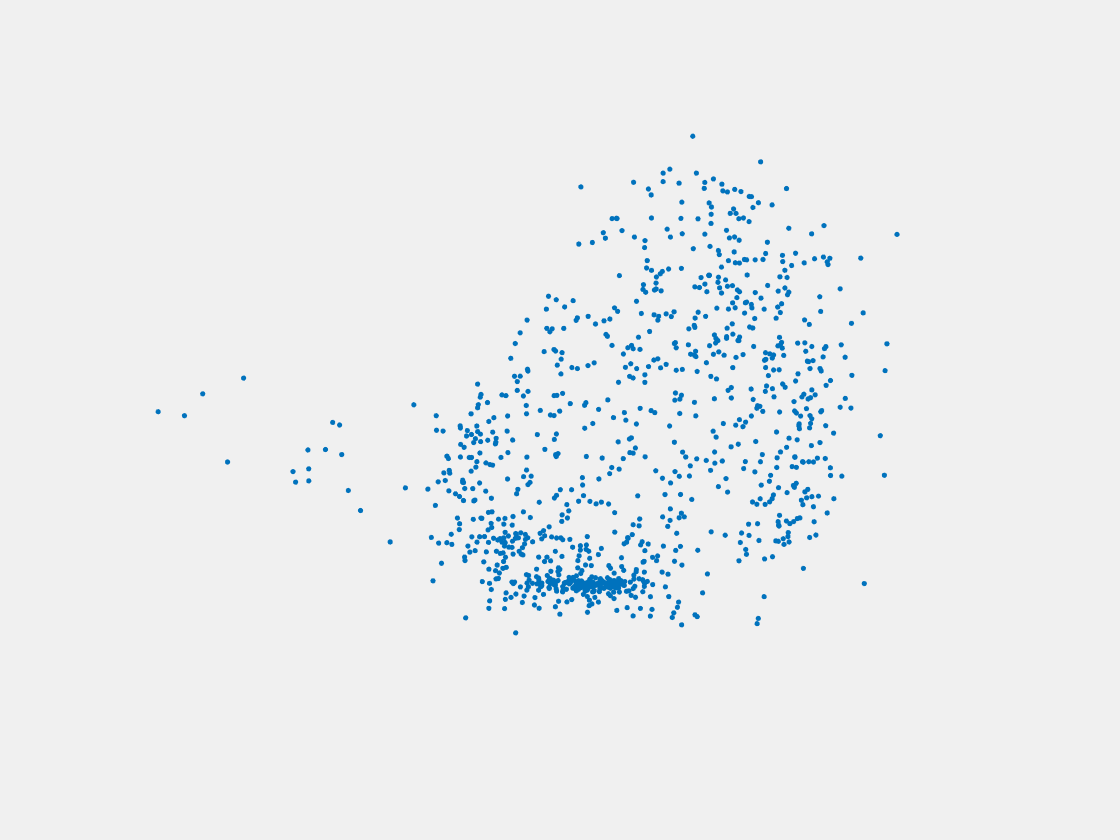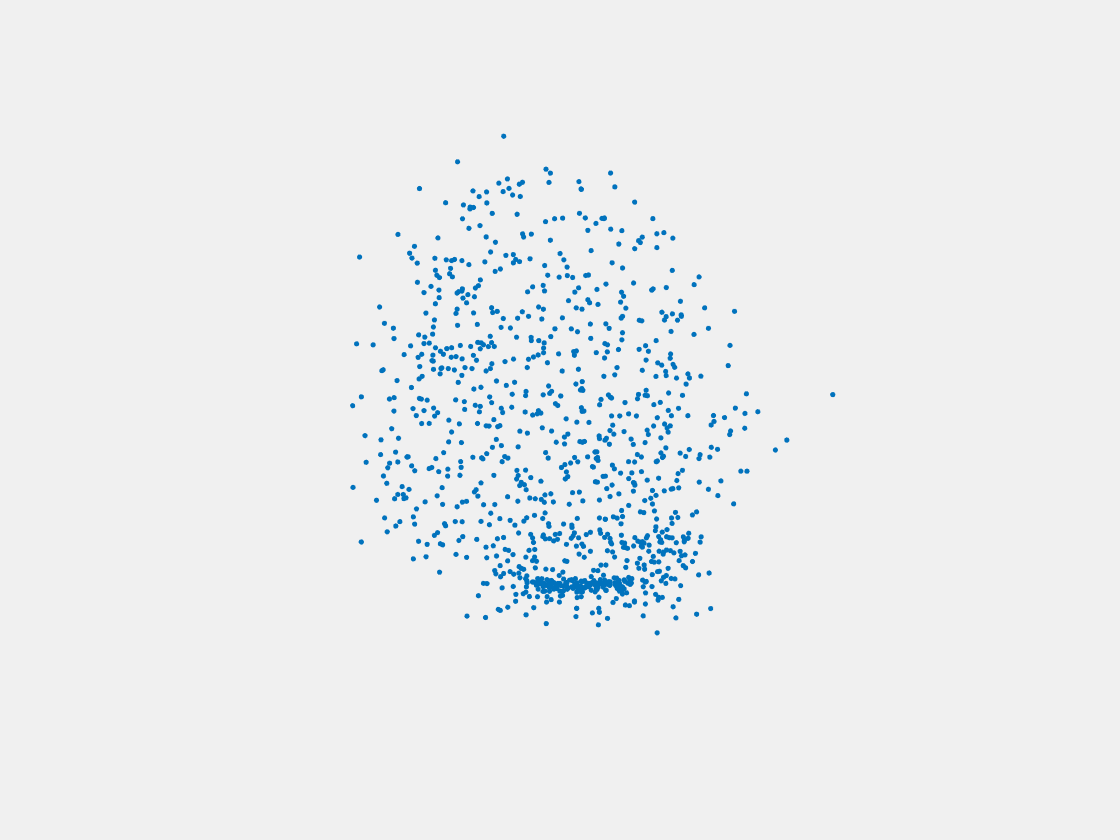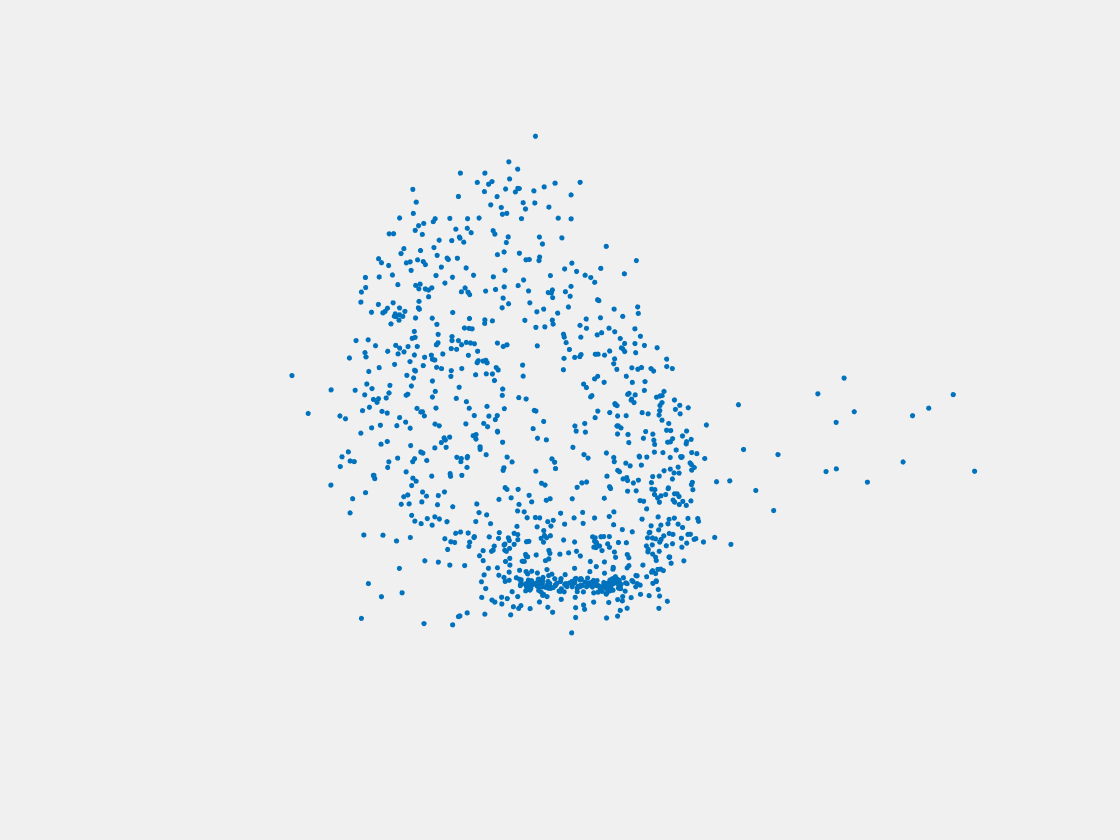
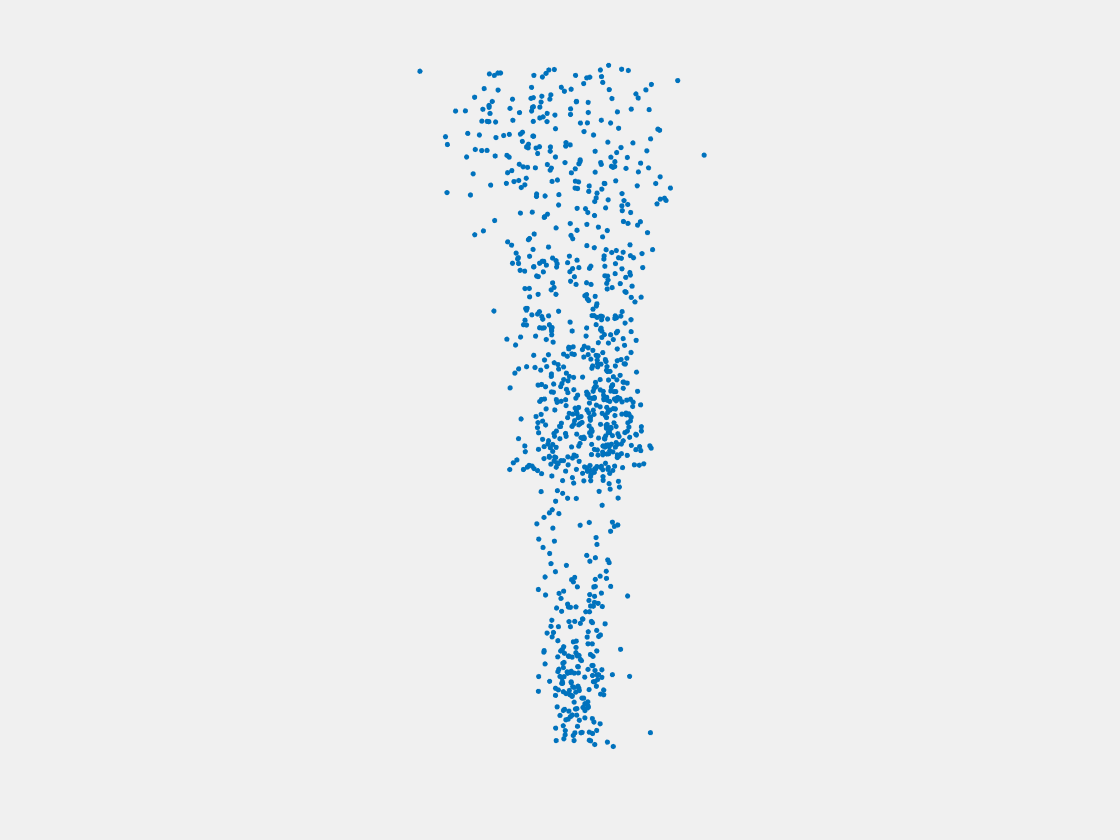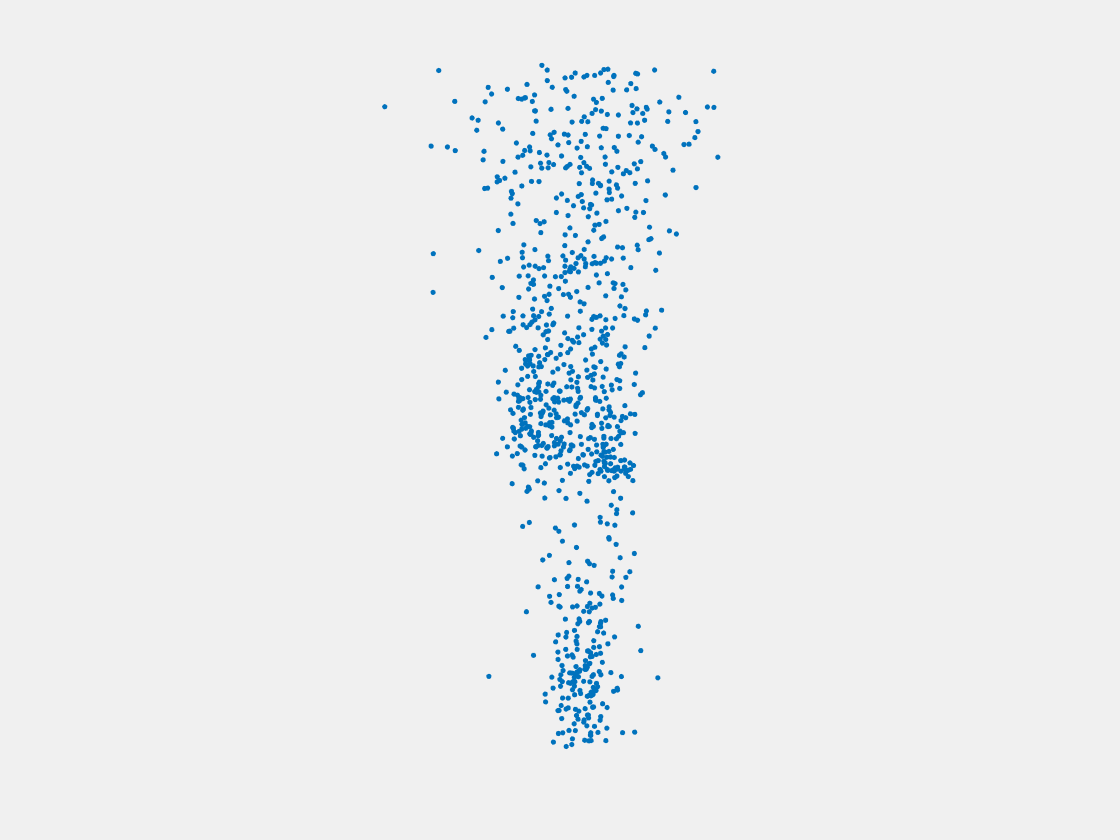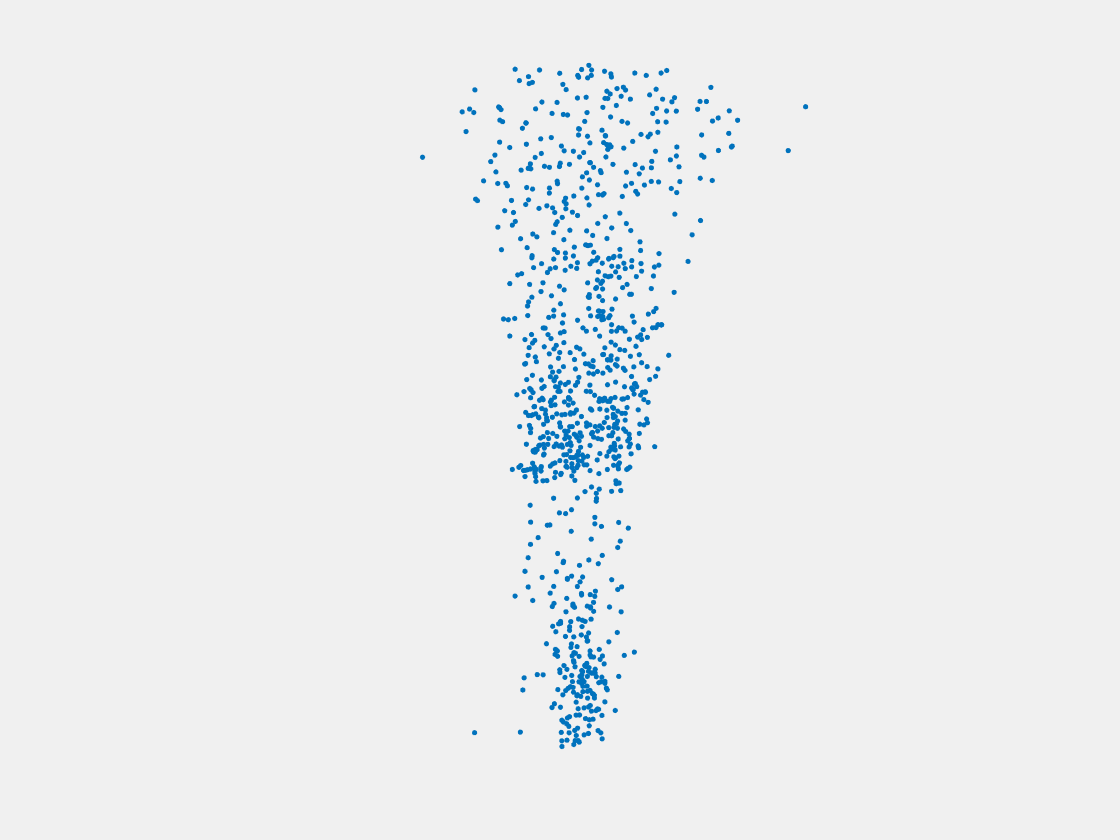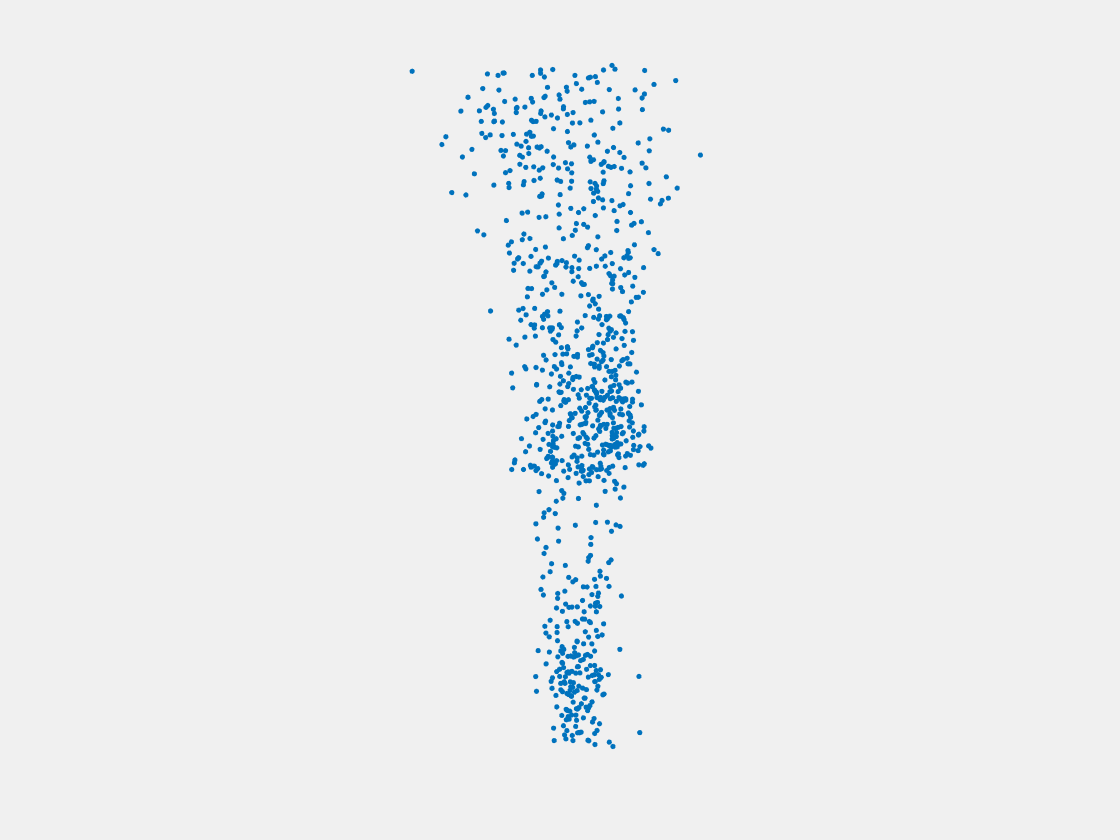
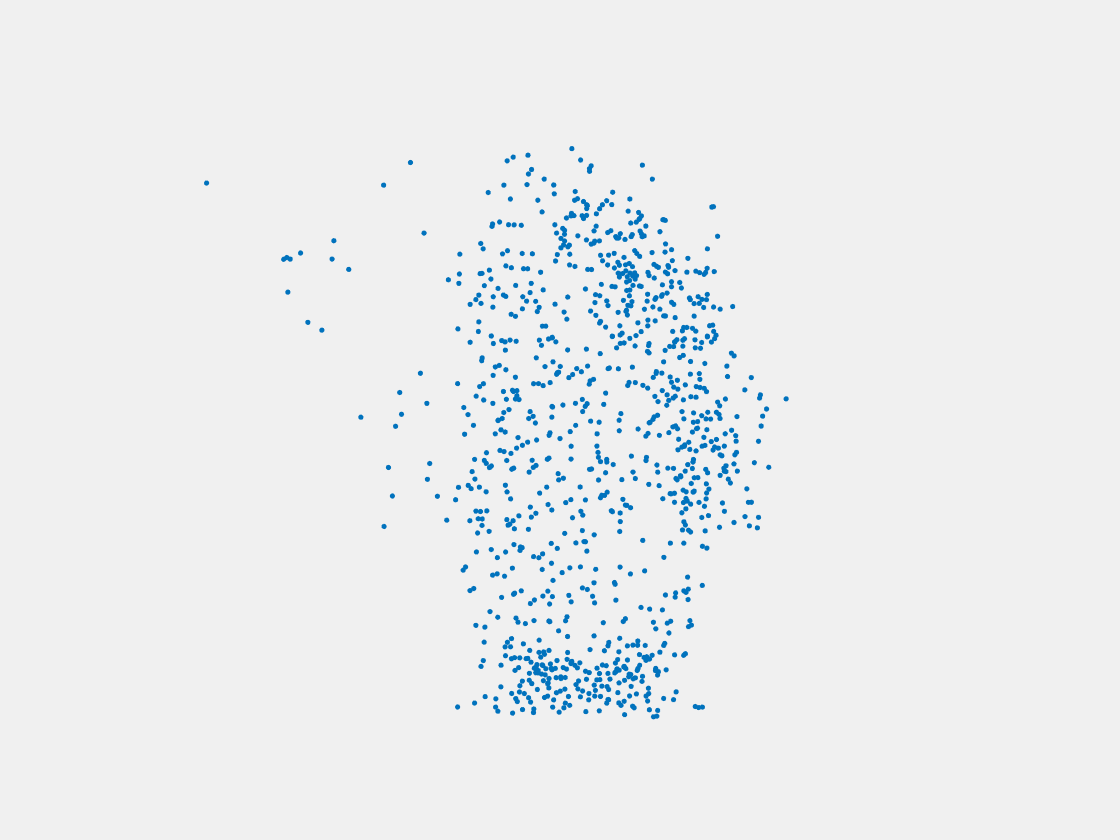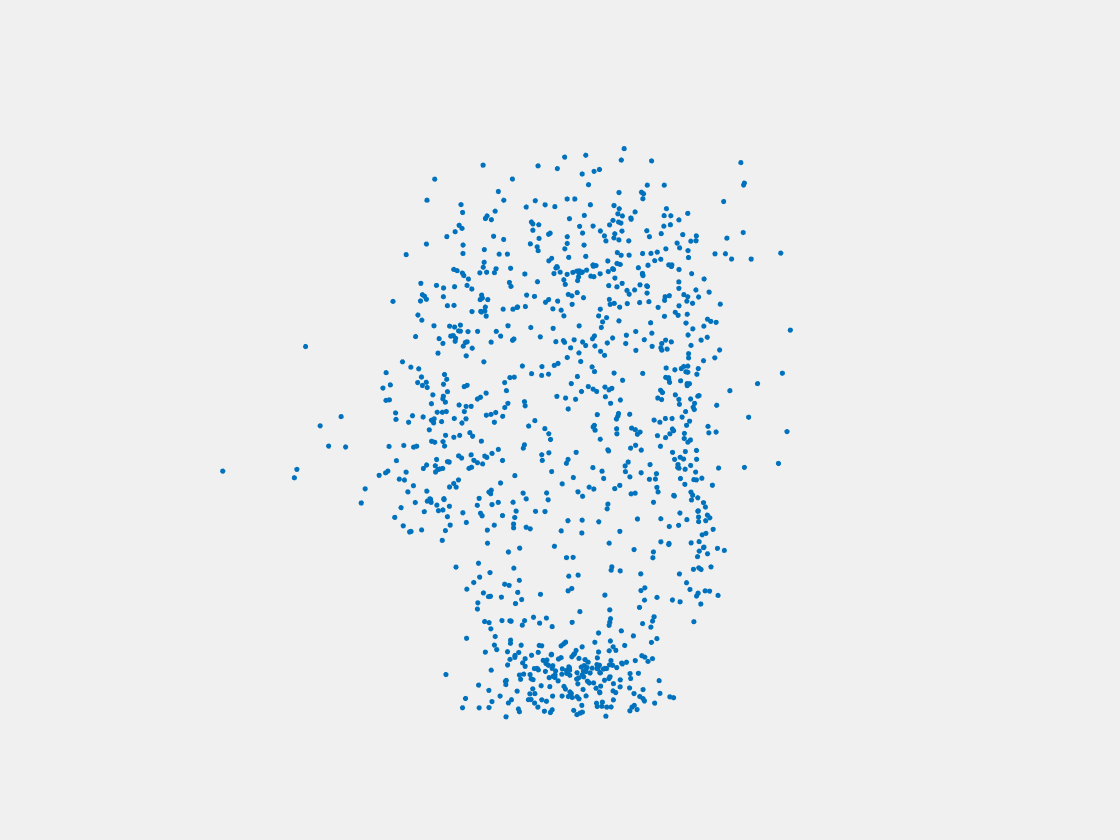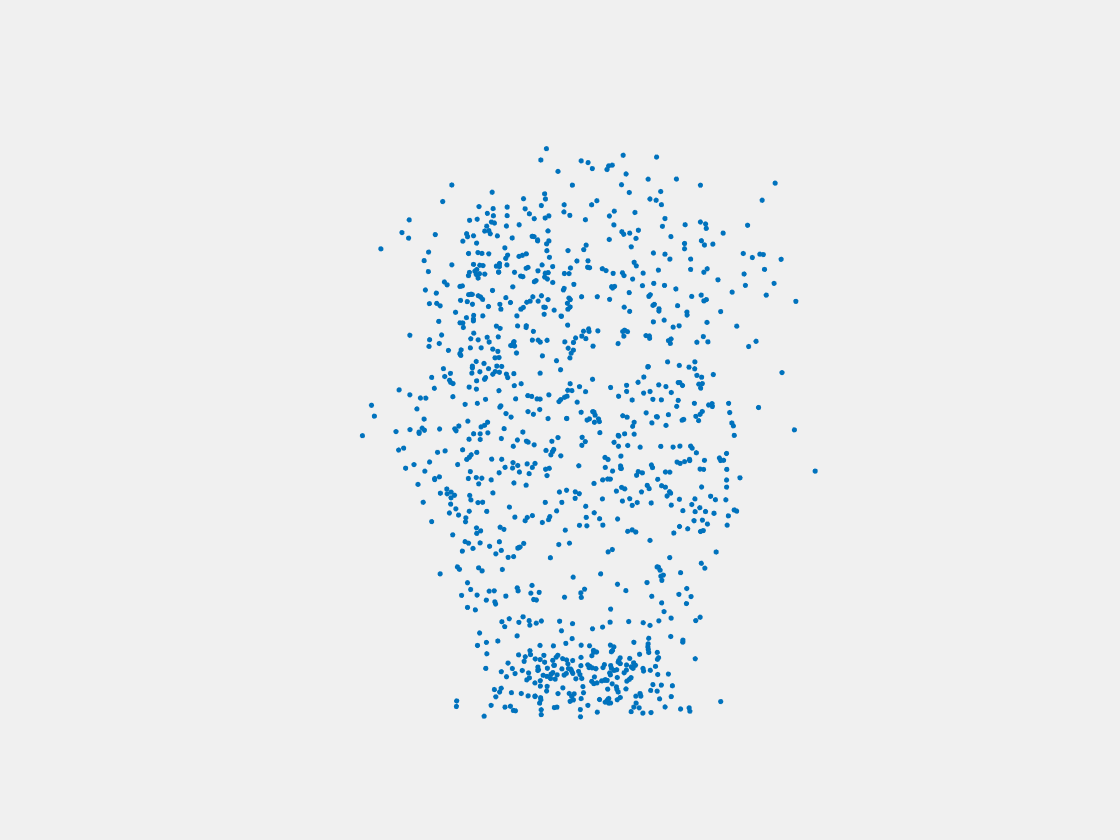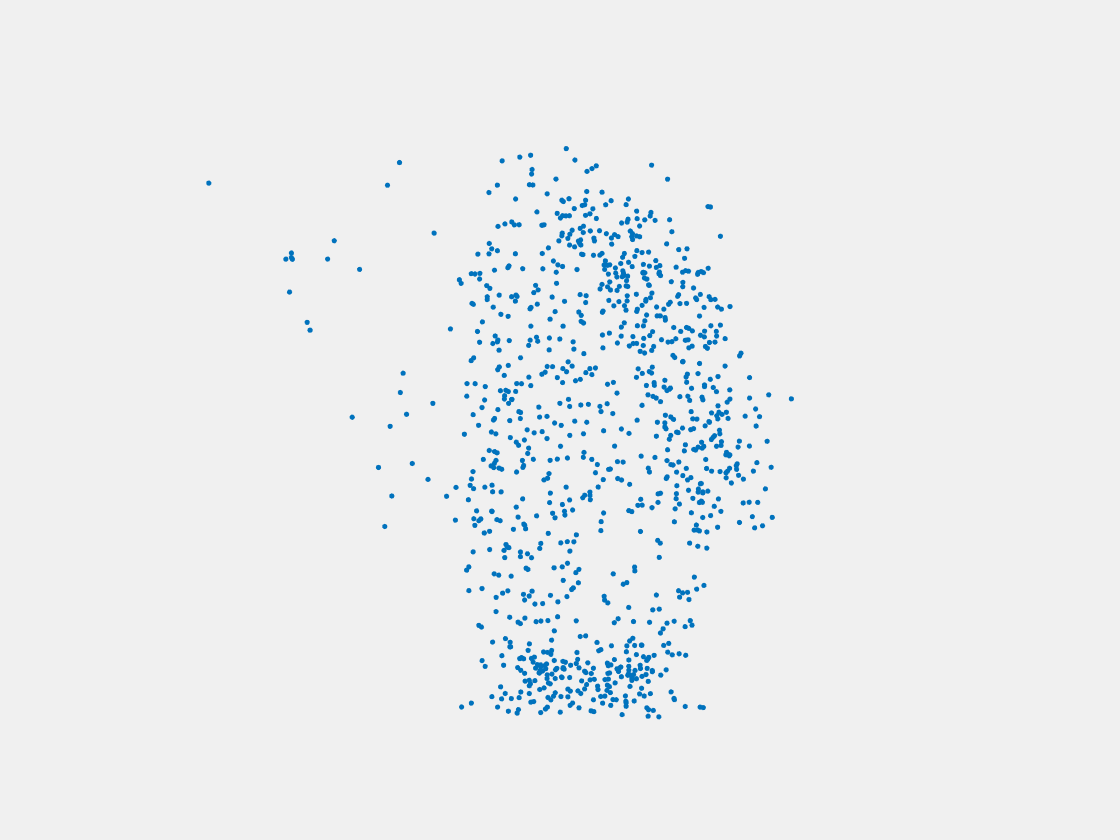
Figure 12: Point clouds of training image generated by MuSullyNet_v1. Left to right, top to bottom: Charmander, Blastoise, Pidgeot, Raticate, Arbok, and Pikachu.
Testing Samples


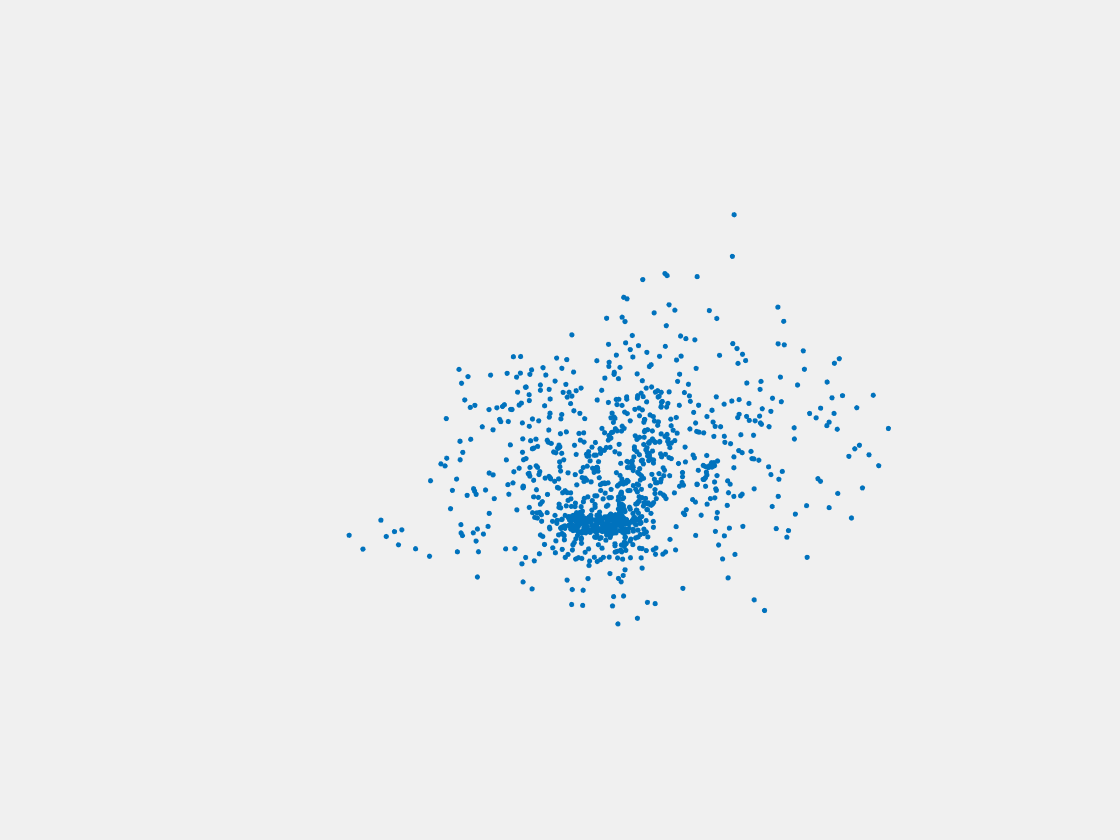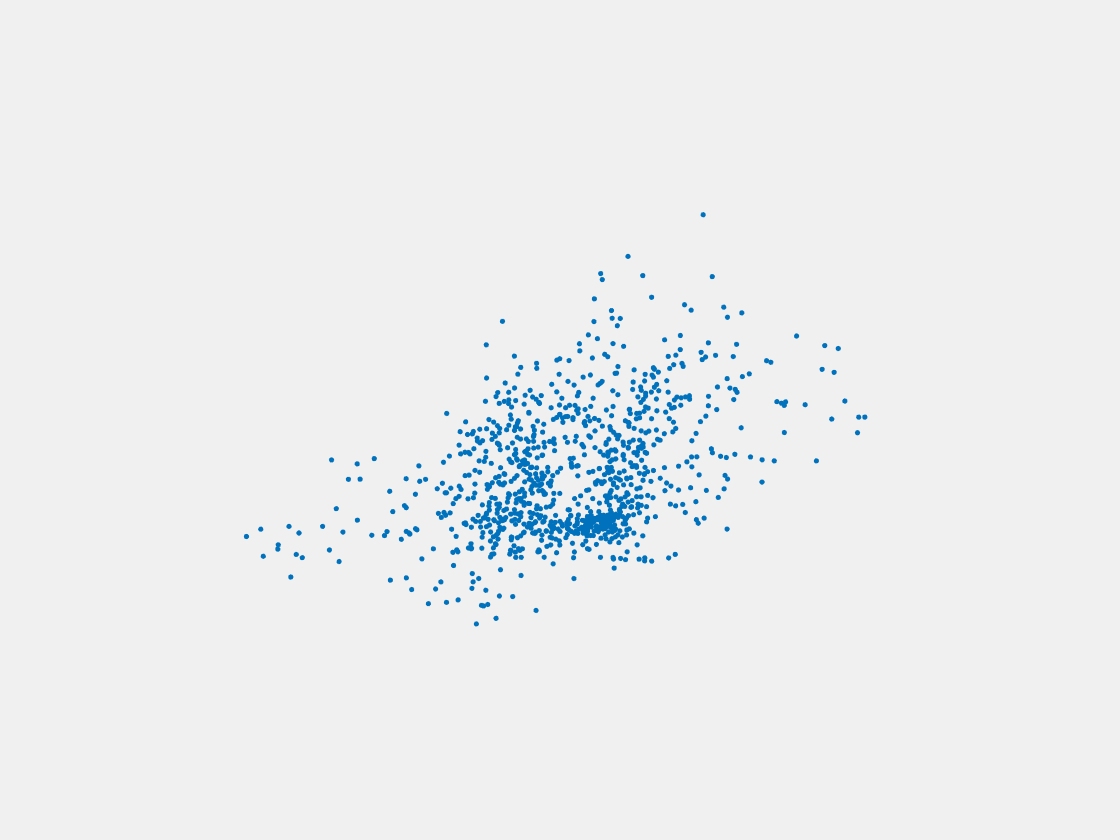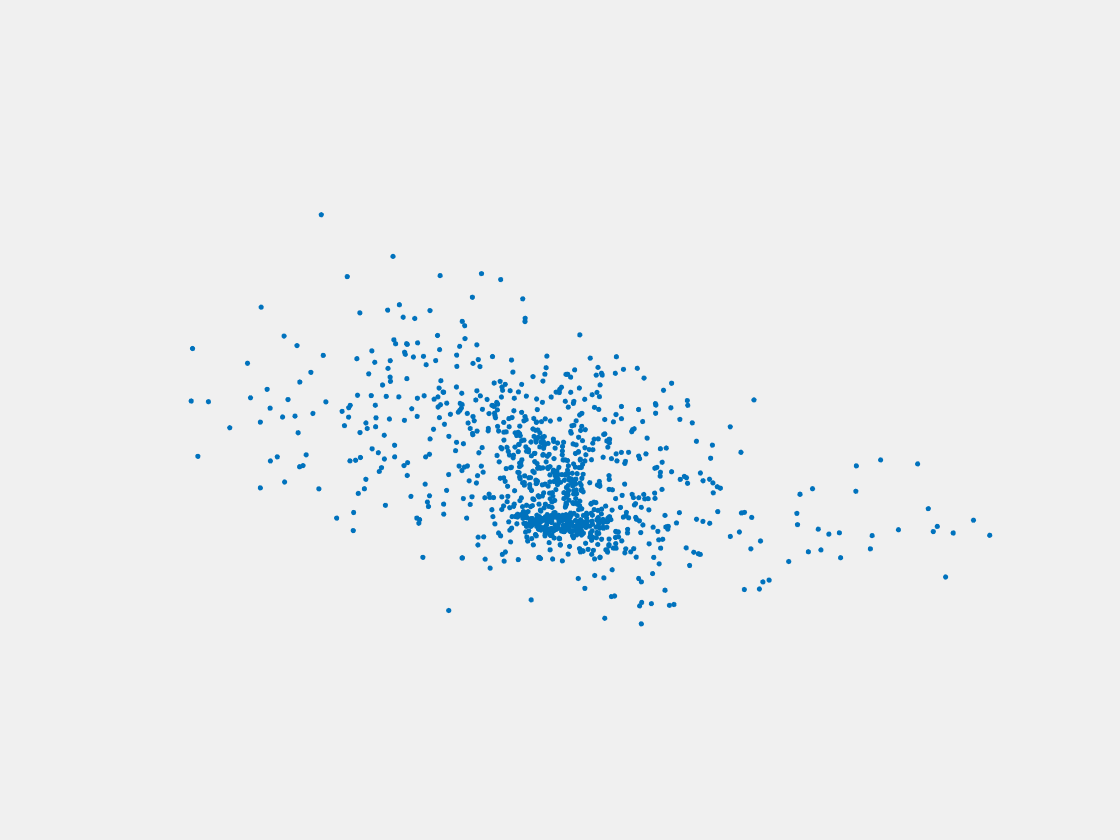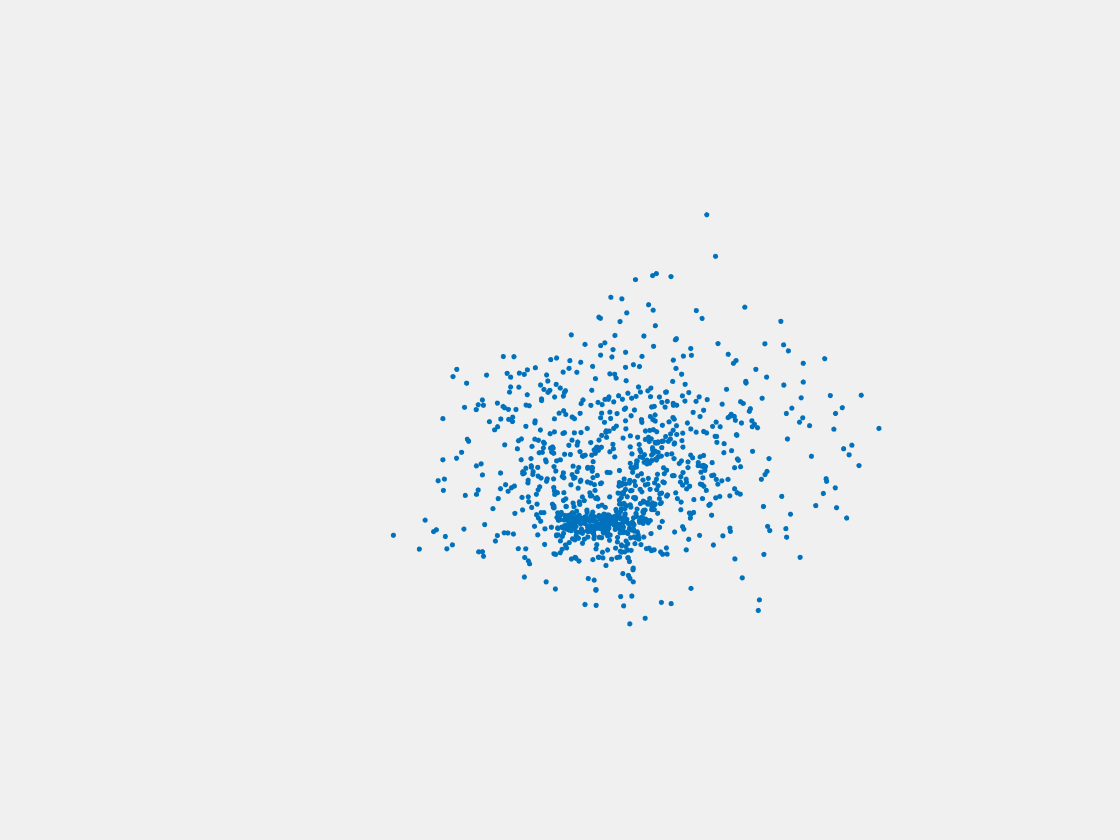
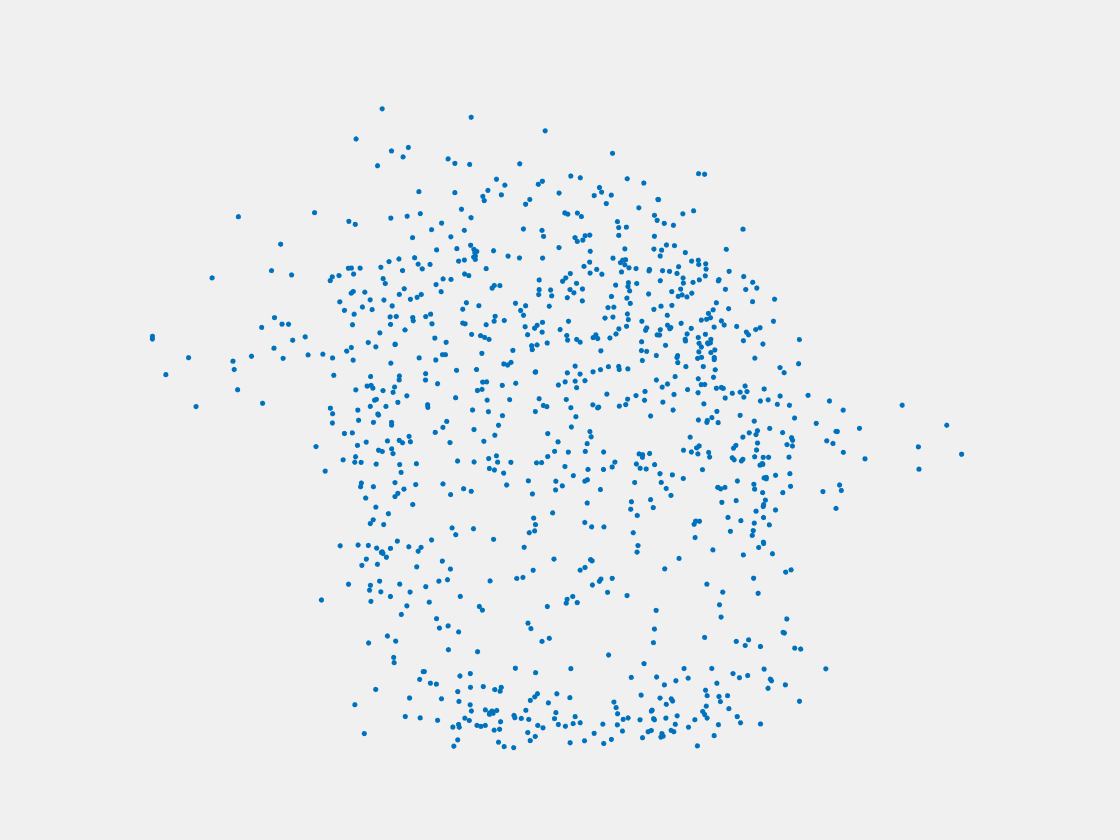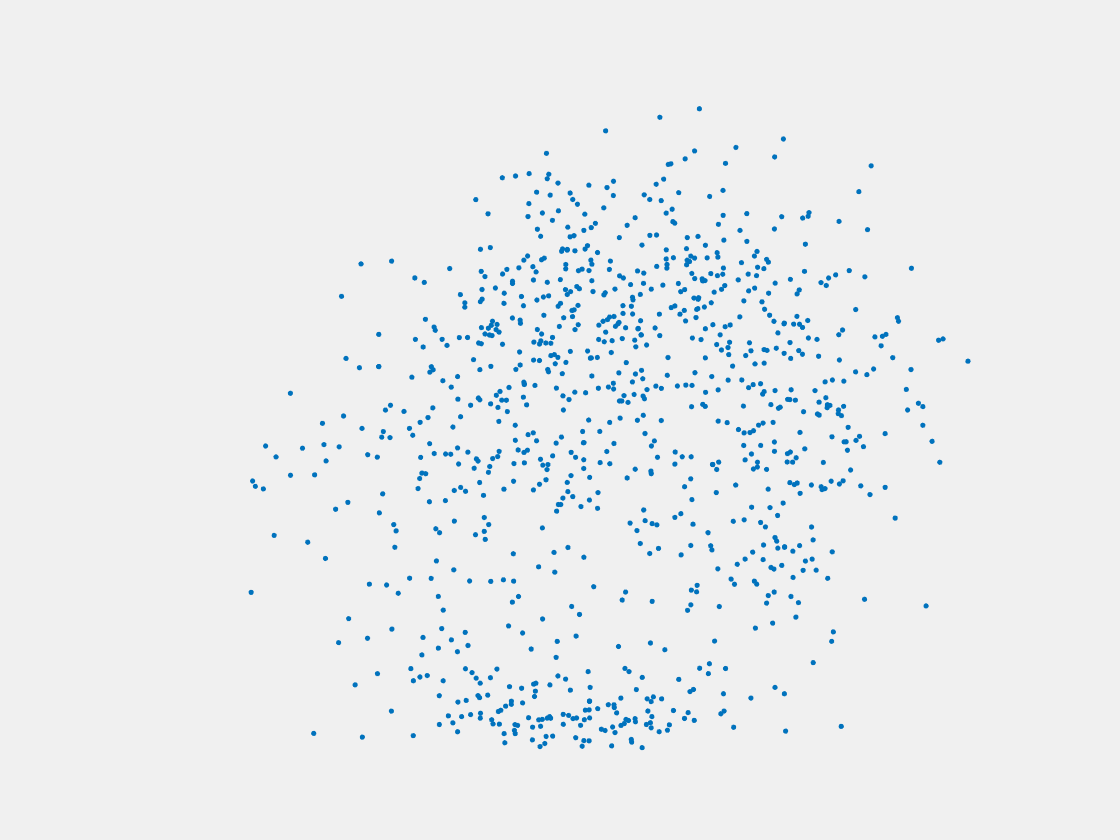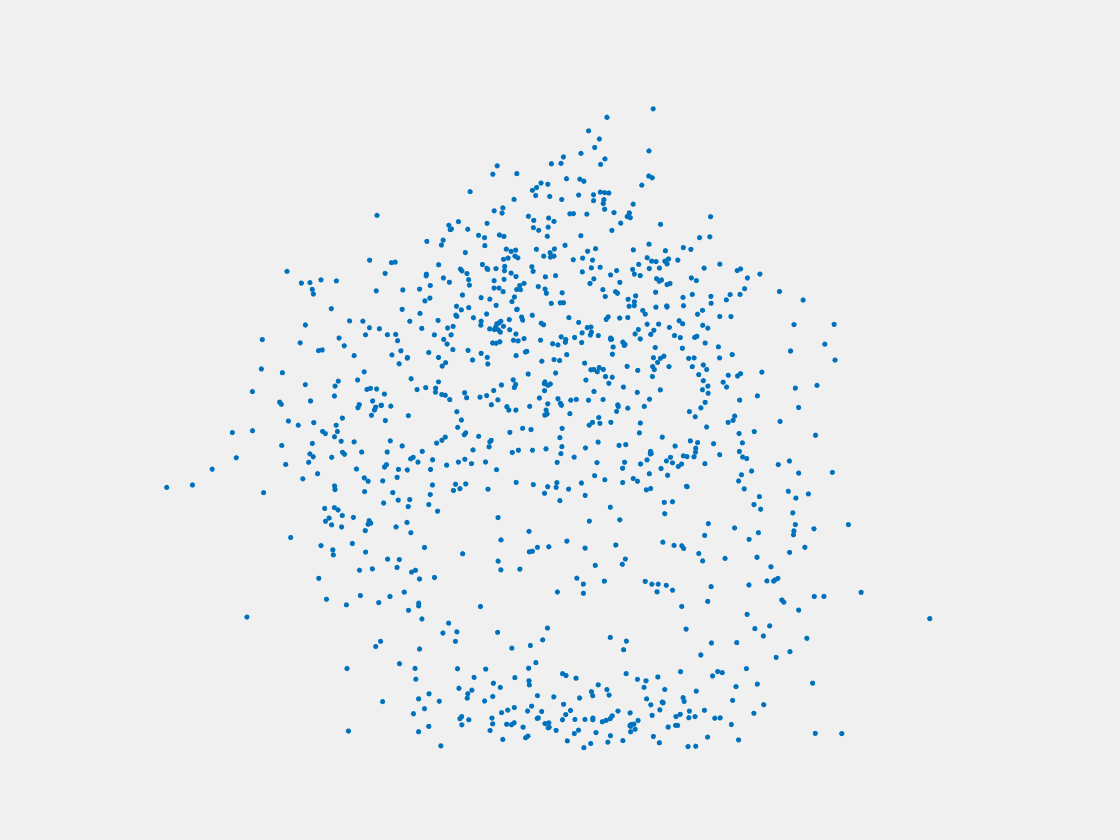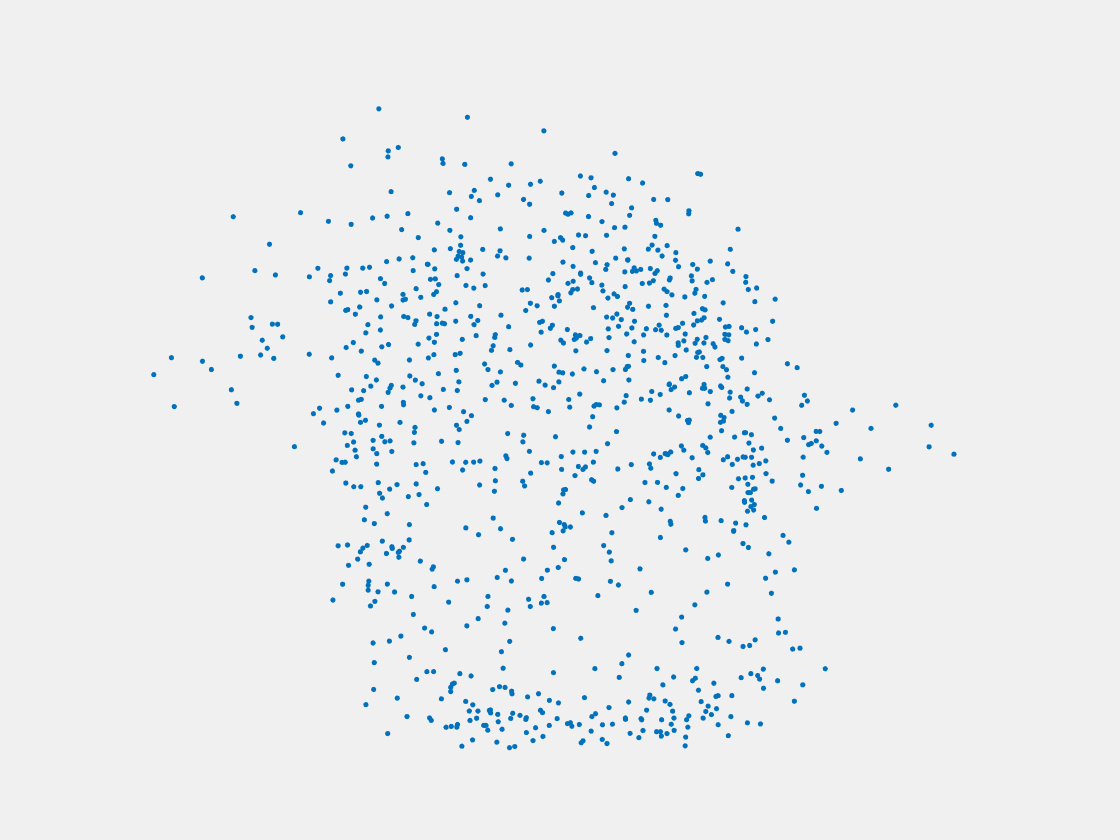
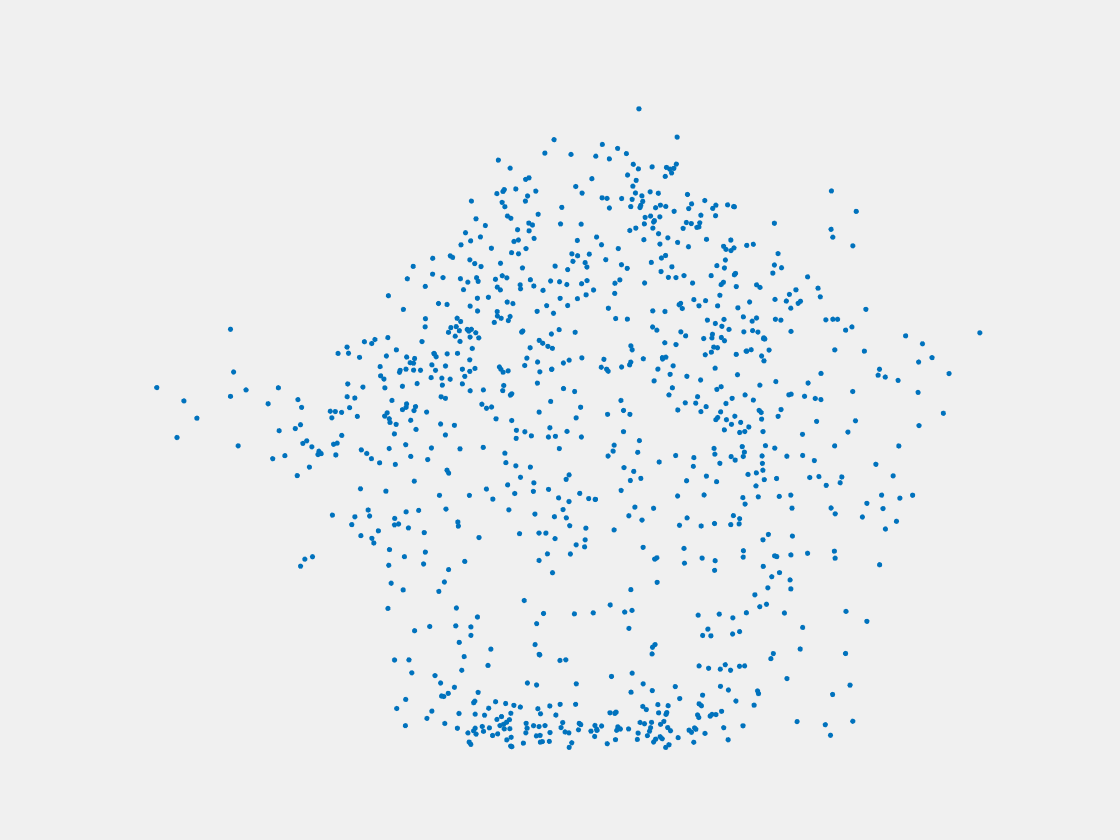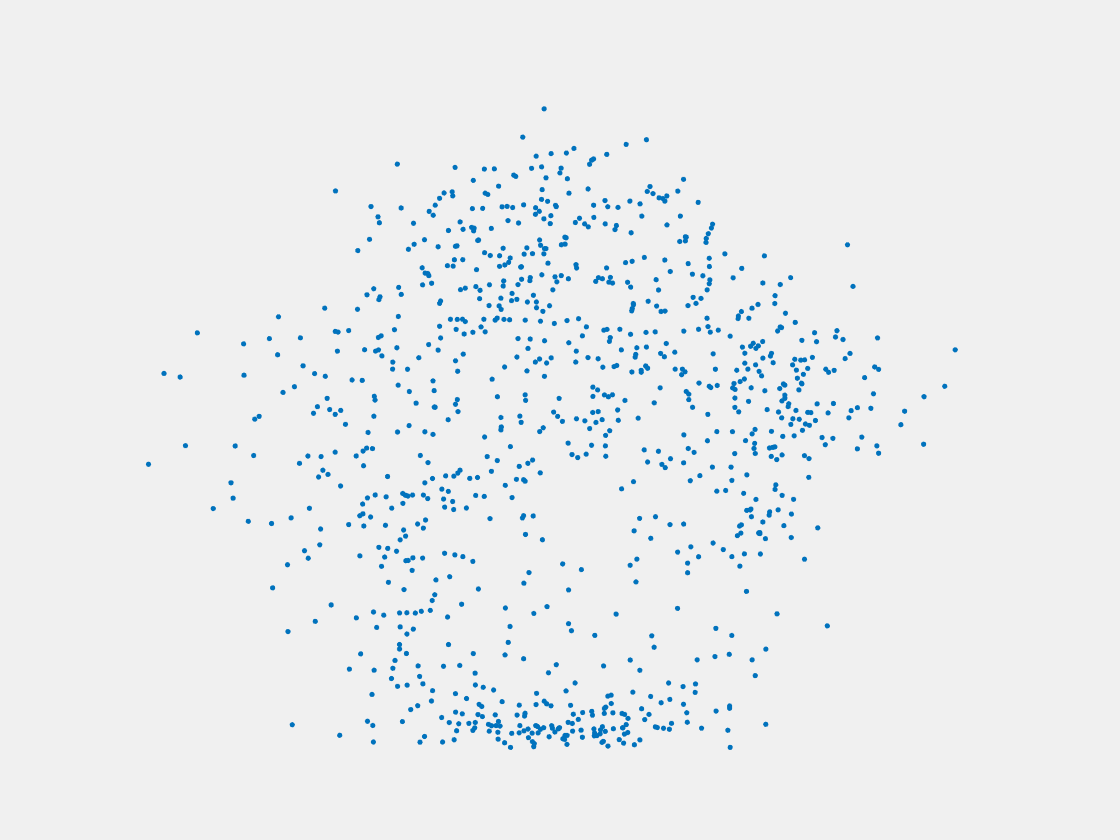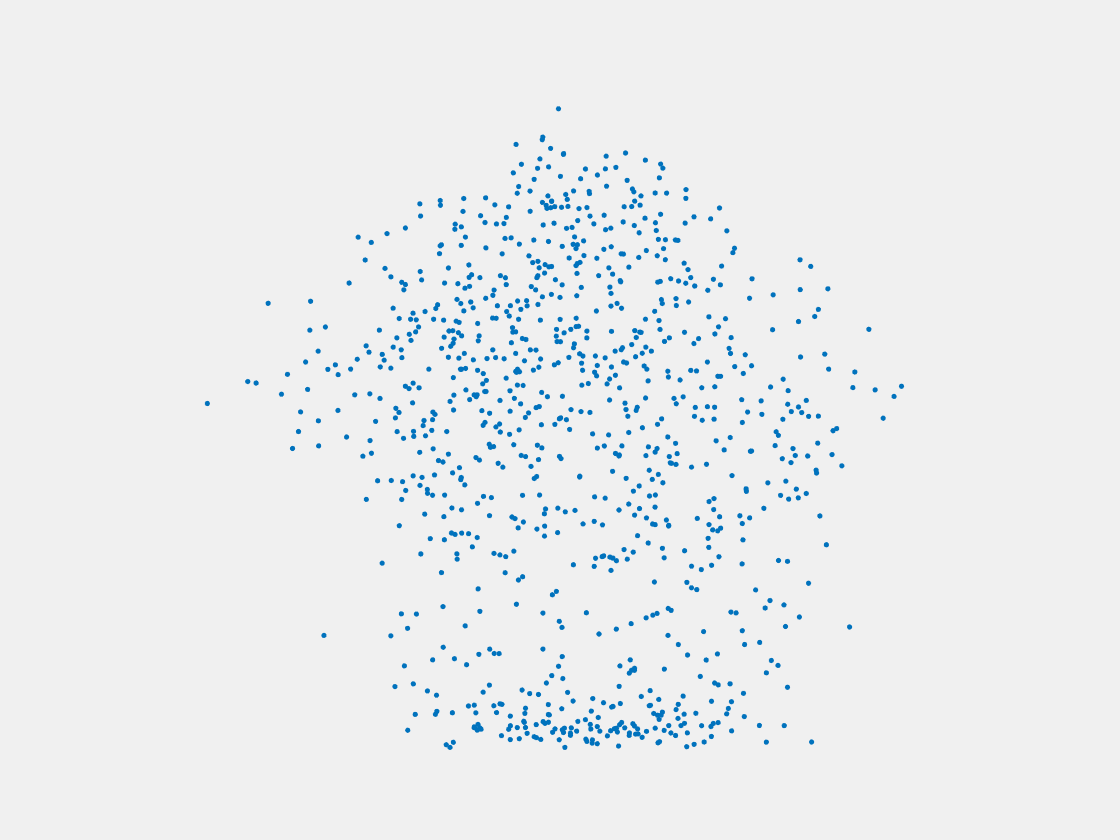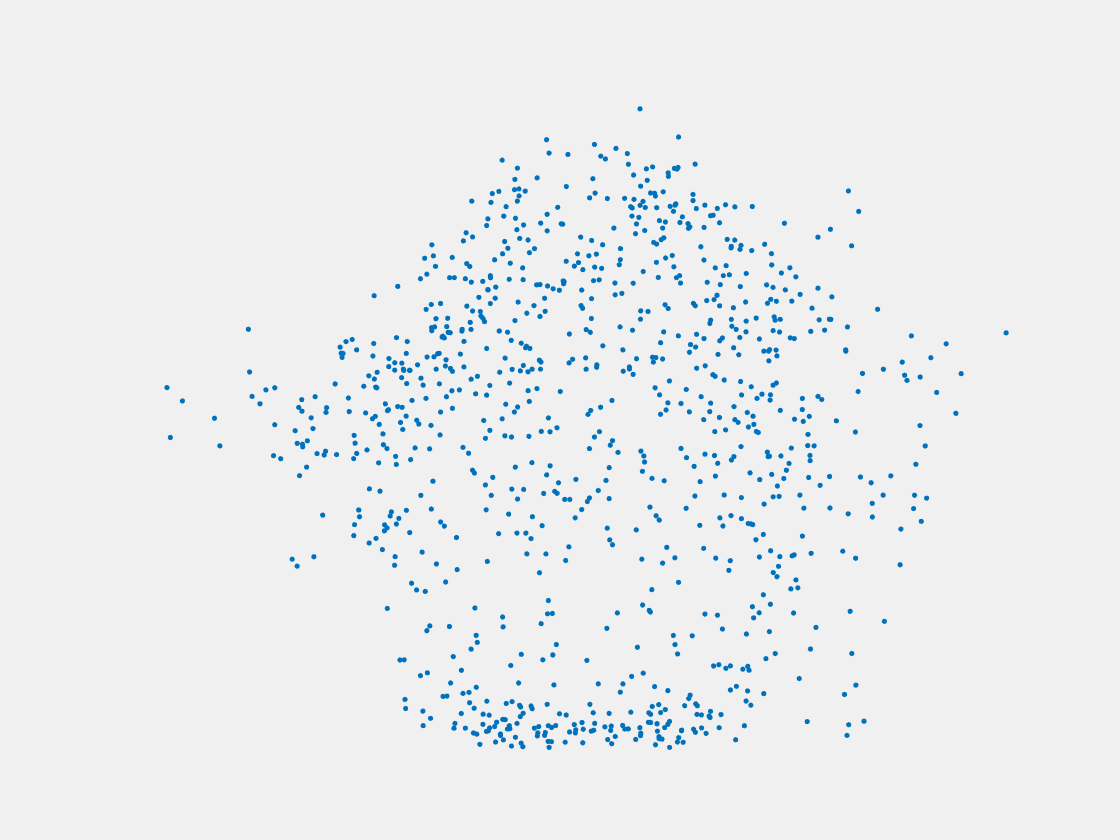
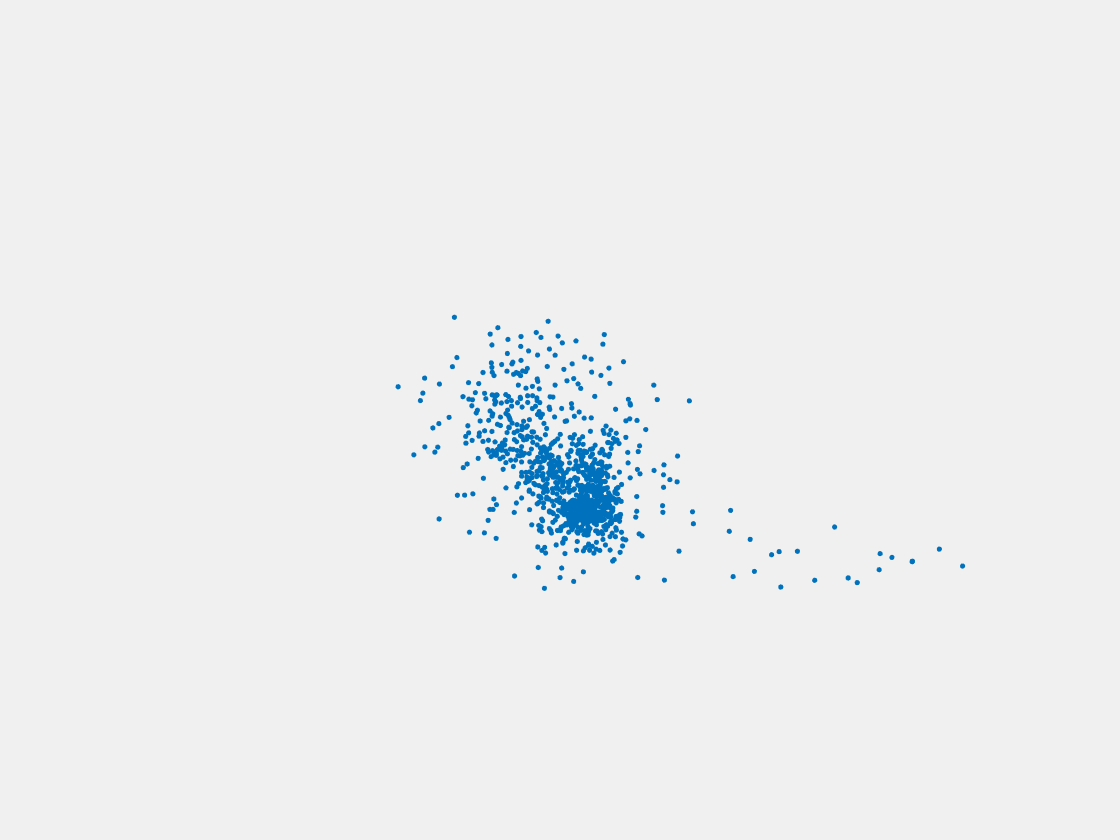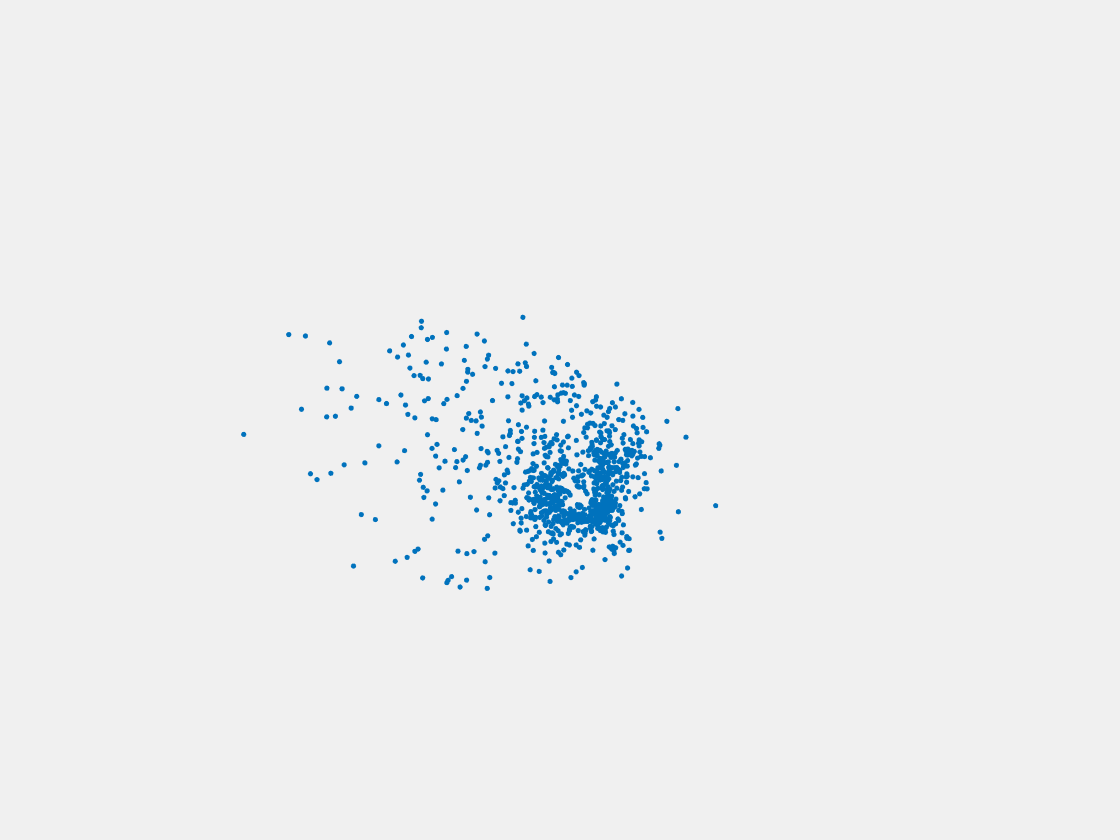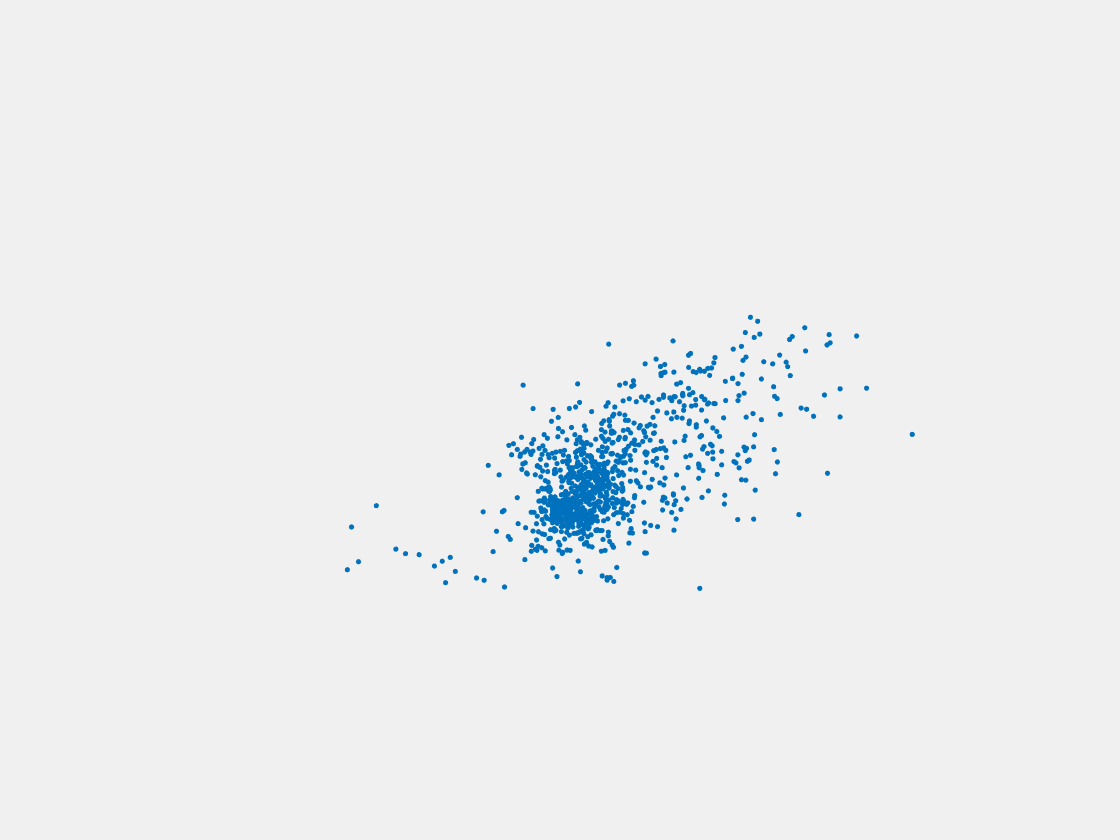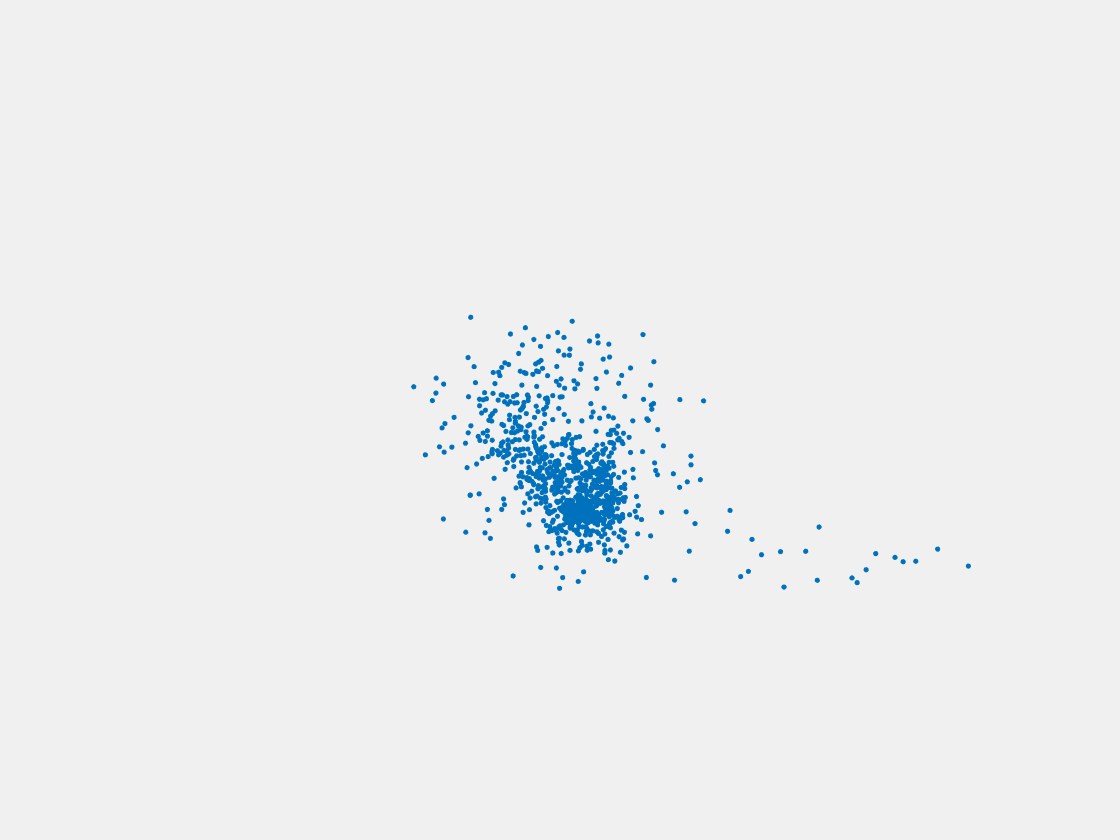
Figure 13: Point clouds of testing image generated by MuSullyNet_v1. Left to right, top to bottom: Pikachu, Farfetch’d, Dewgong, Gengar, Snorlax, and Mew.
Version 2
Training Samples




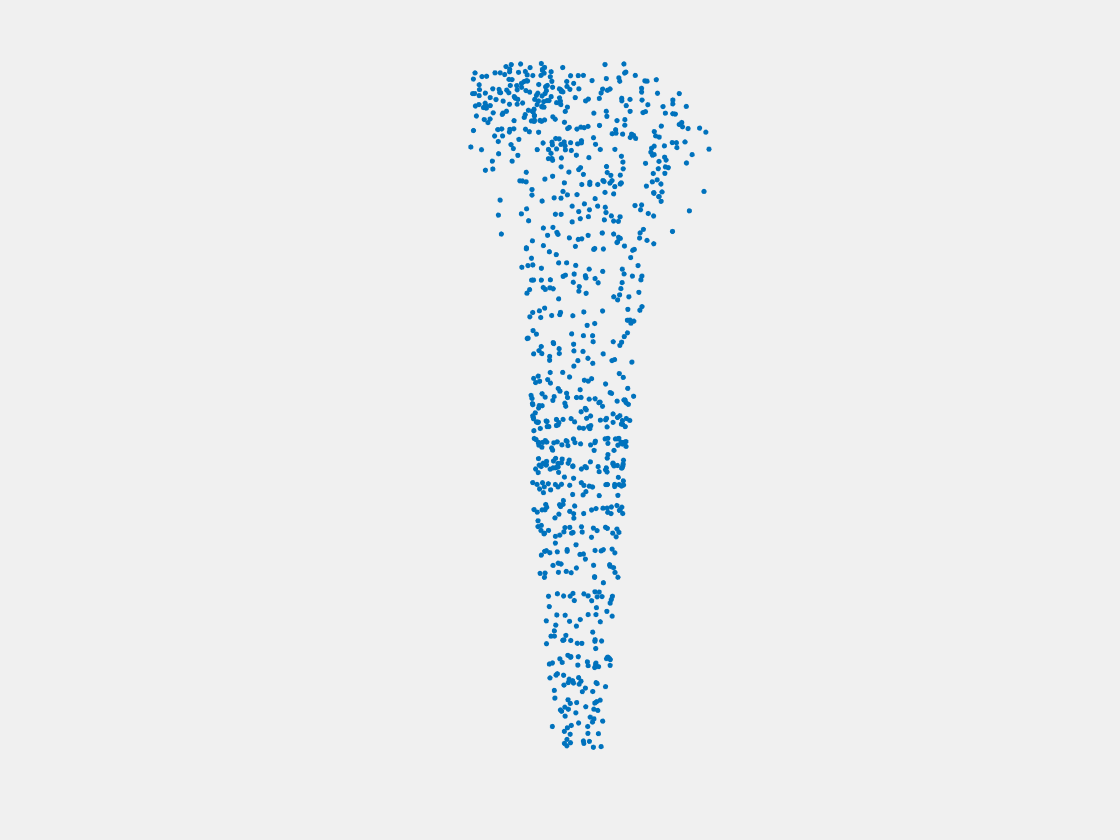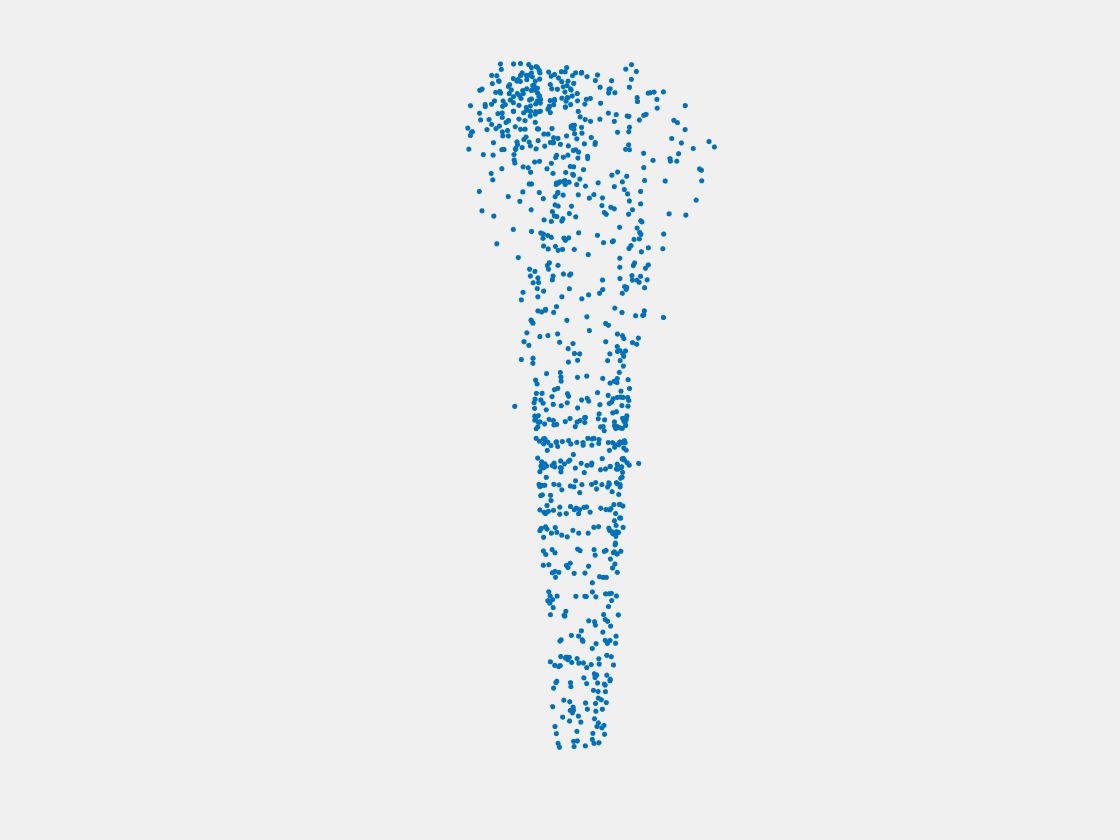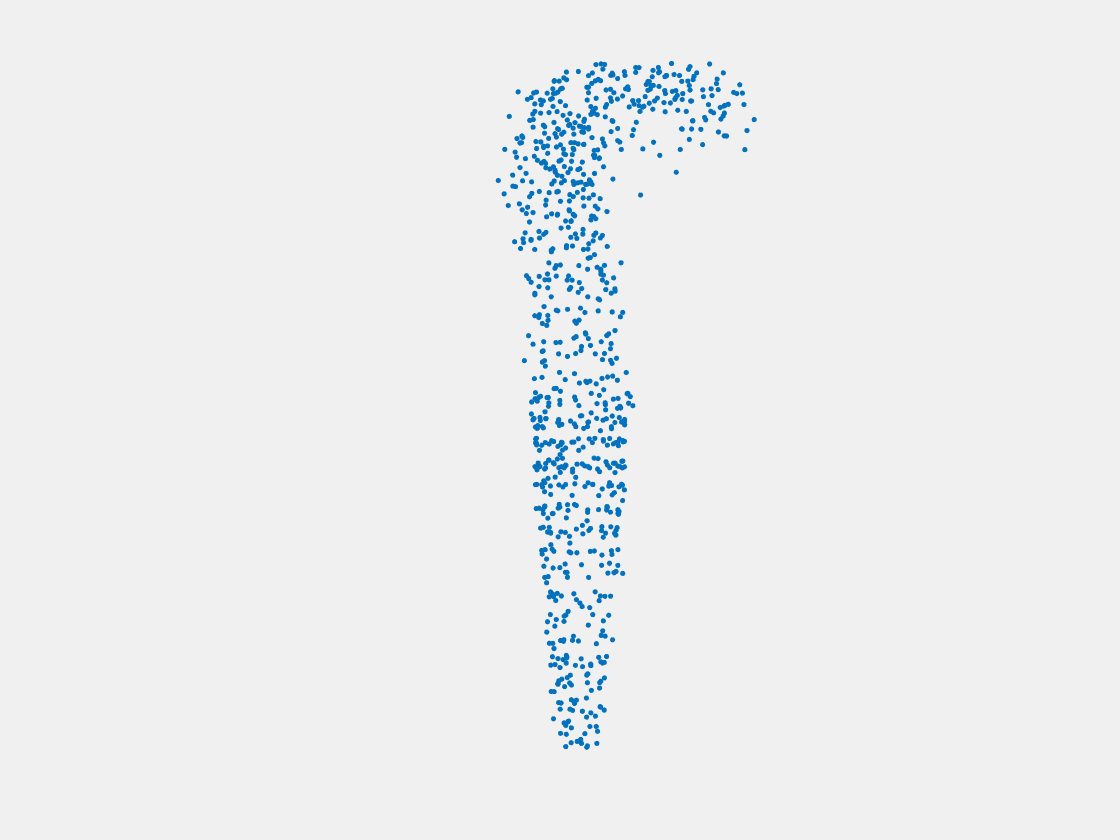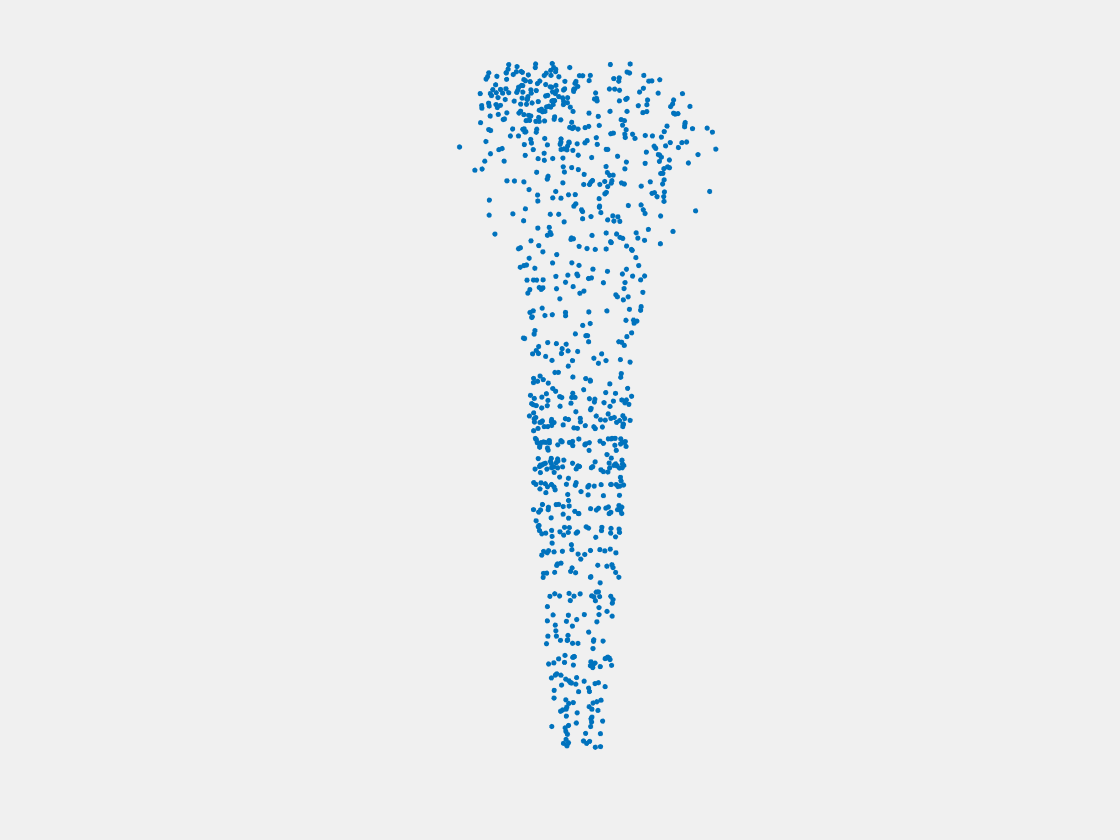
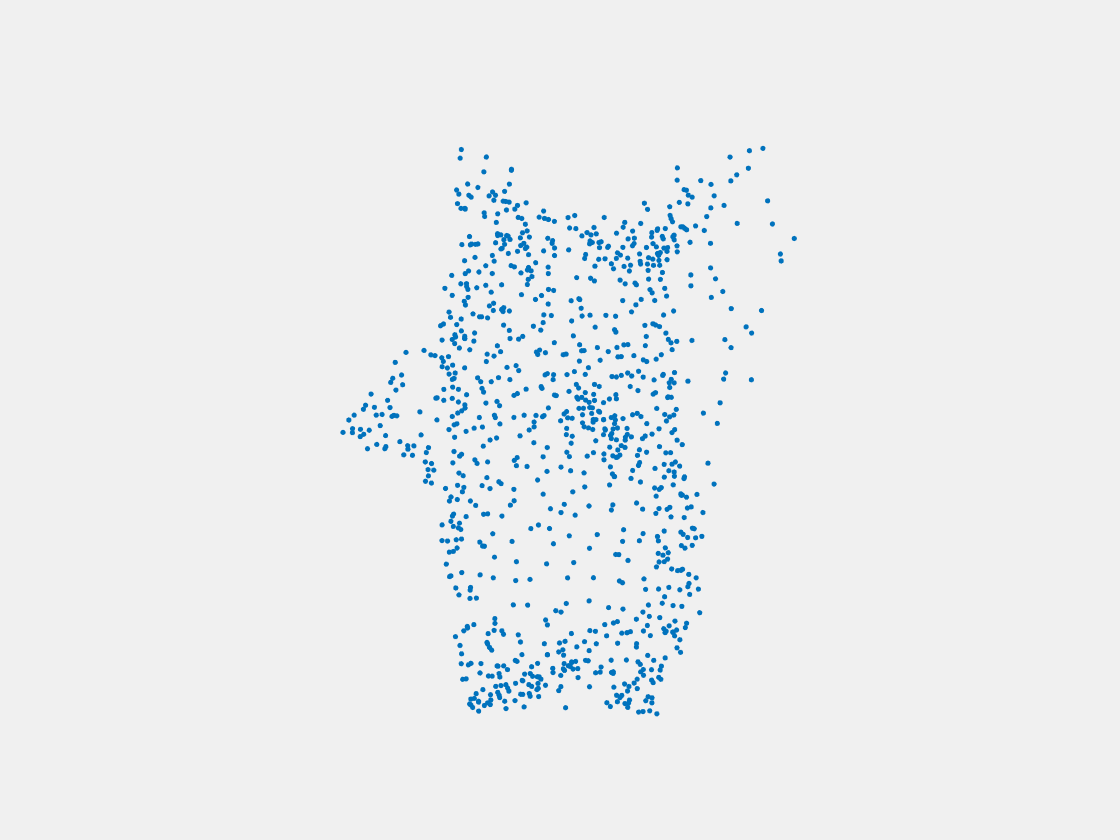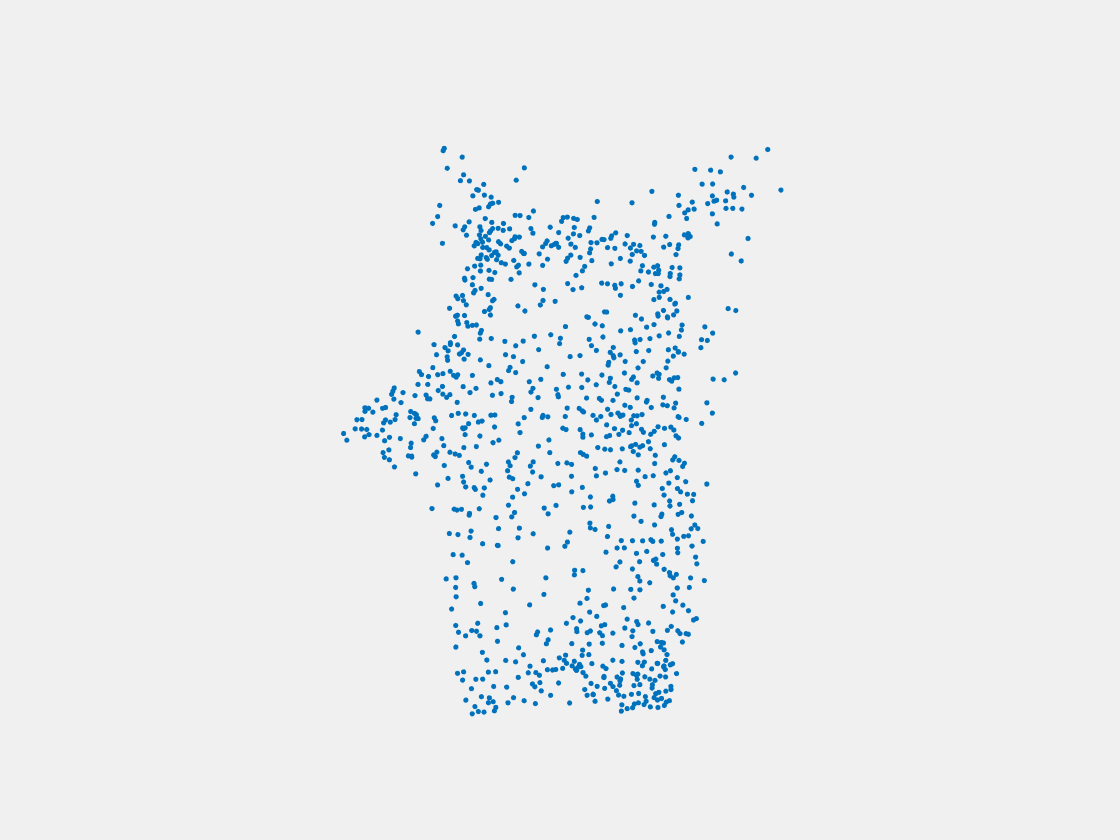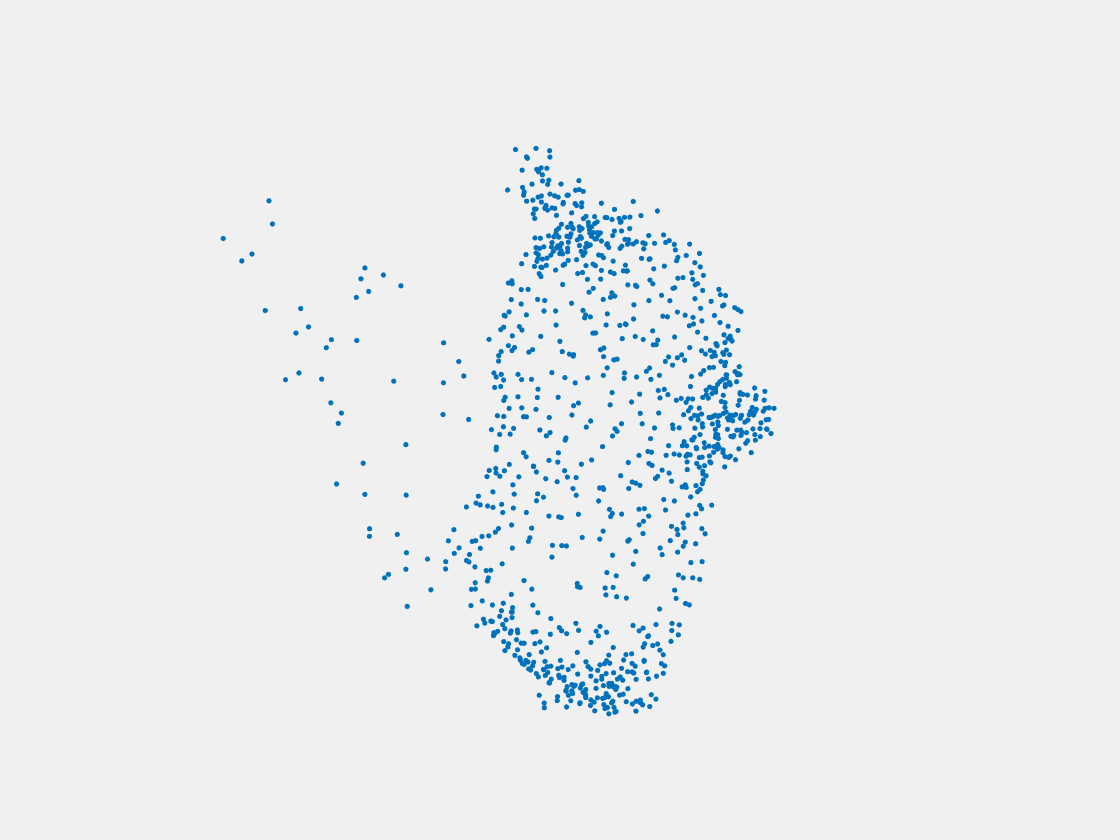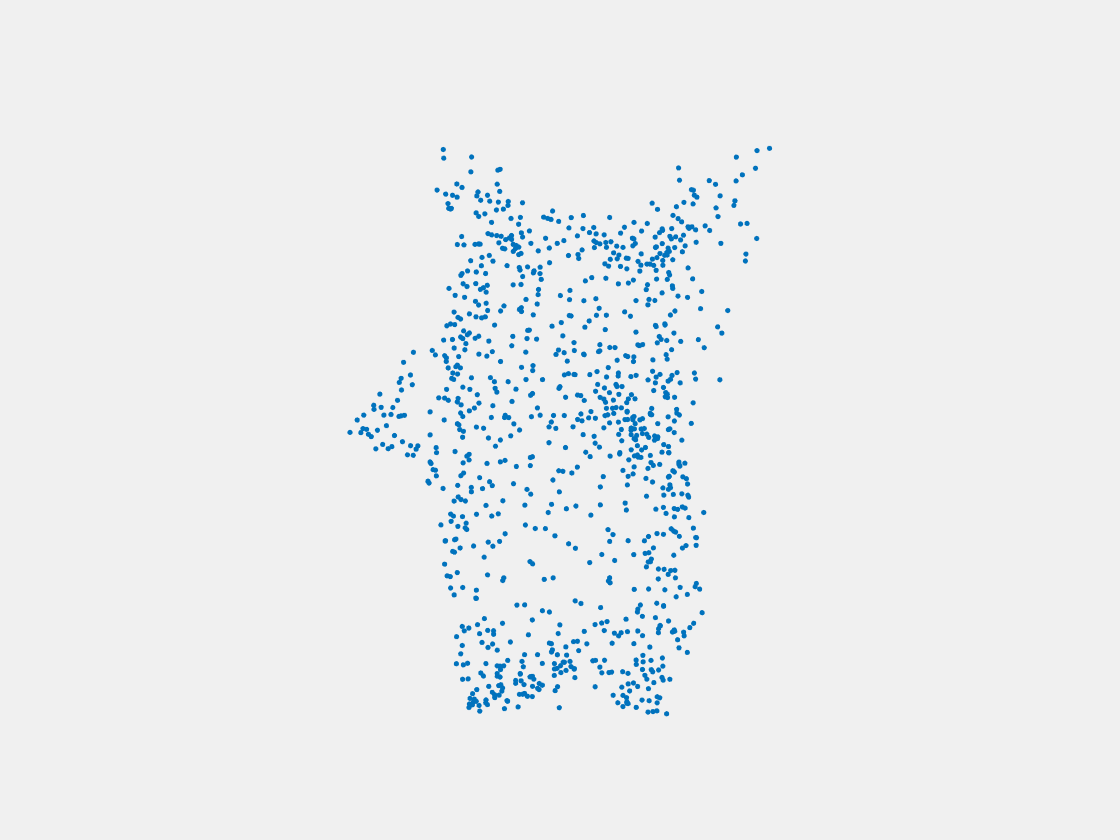
Figure 14: Point clouds of training image generated by MuSullyNet_v2. Left to right, top to bottom: Charmander, Blastoise, Pidgeot, Raticate, Arbok, and Pikachu.
Testing Samples
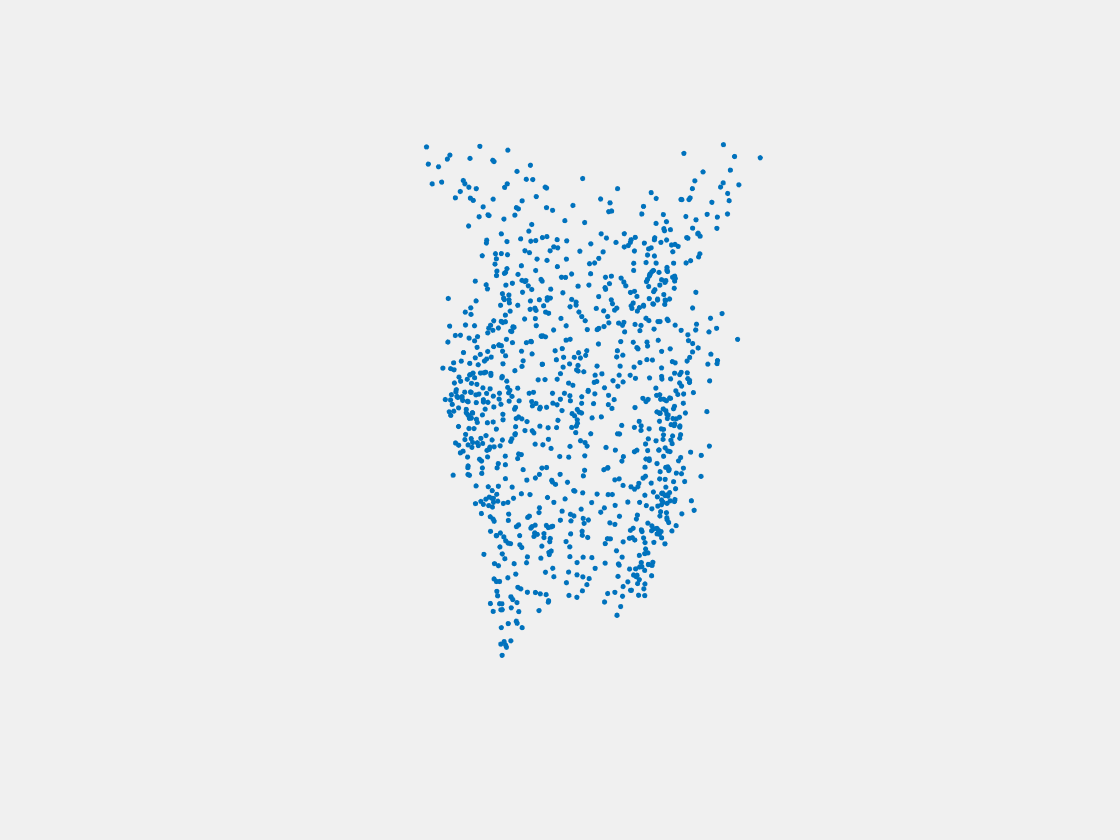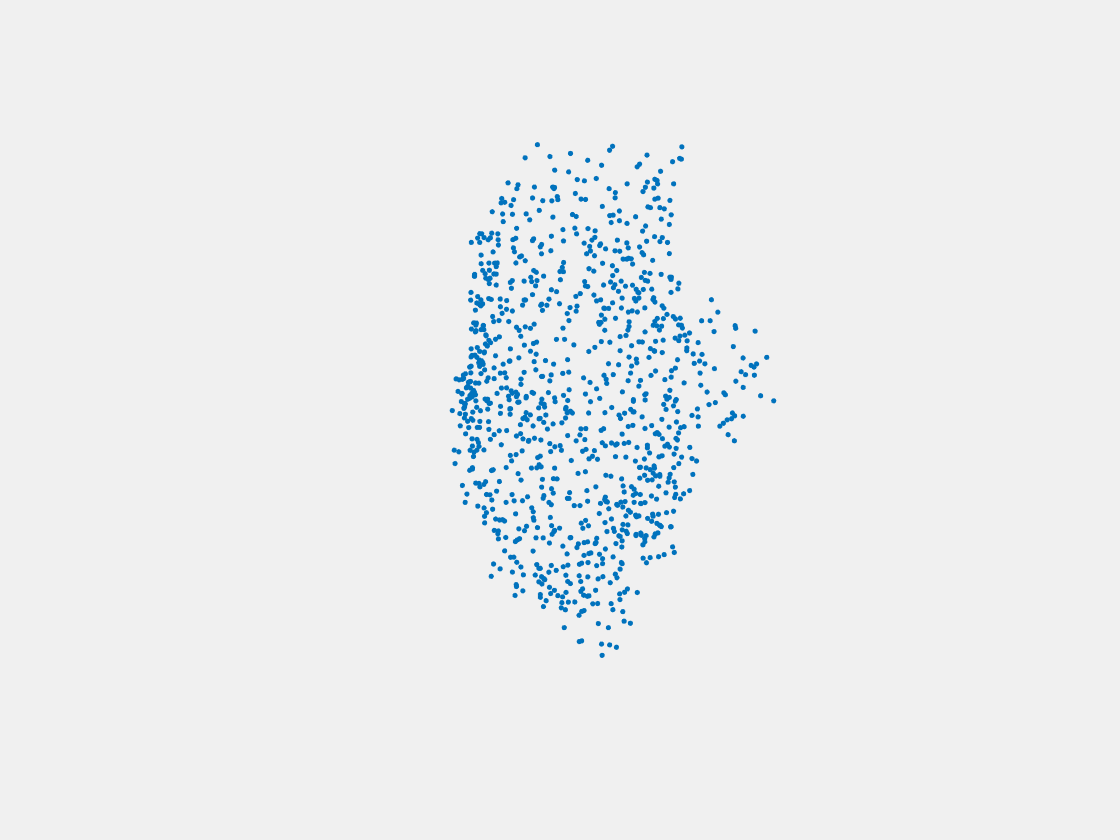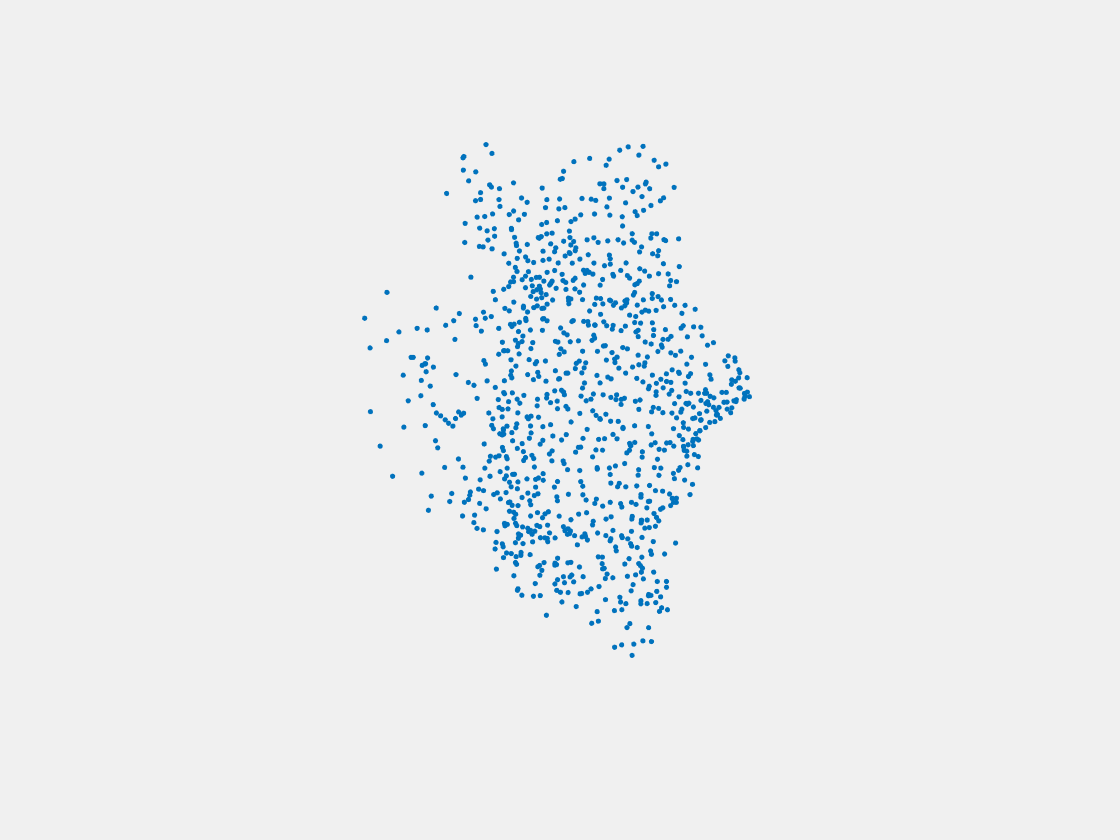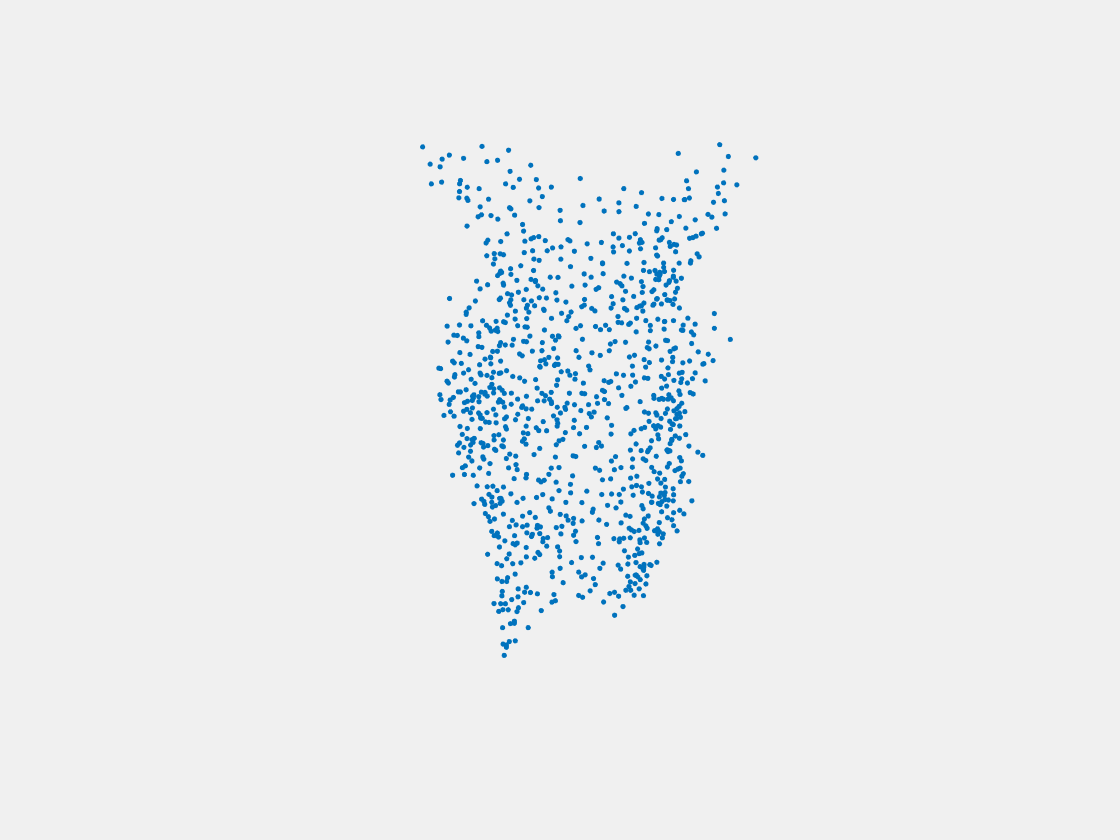

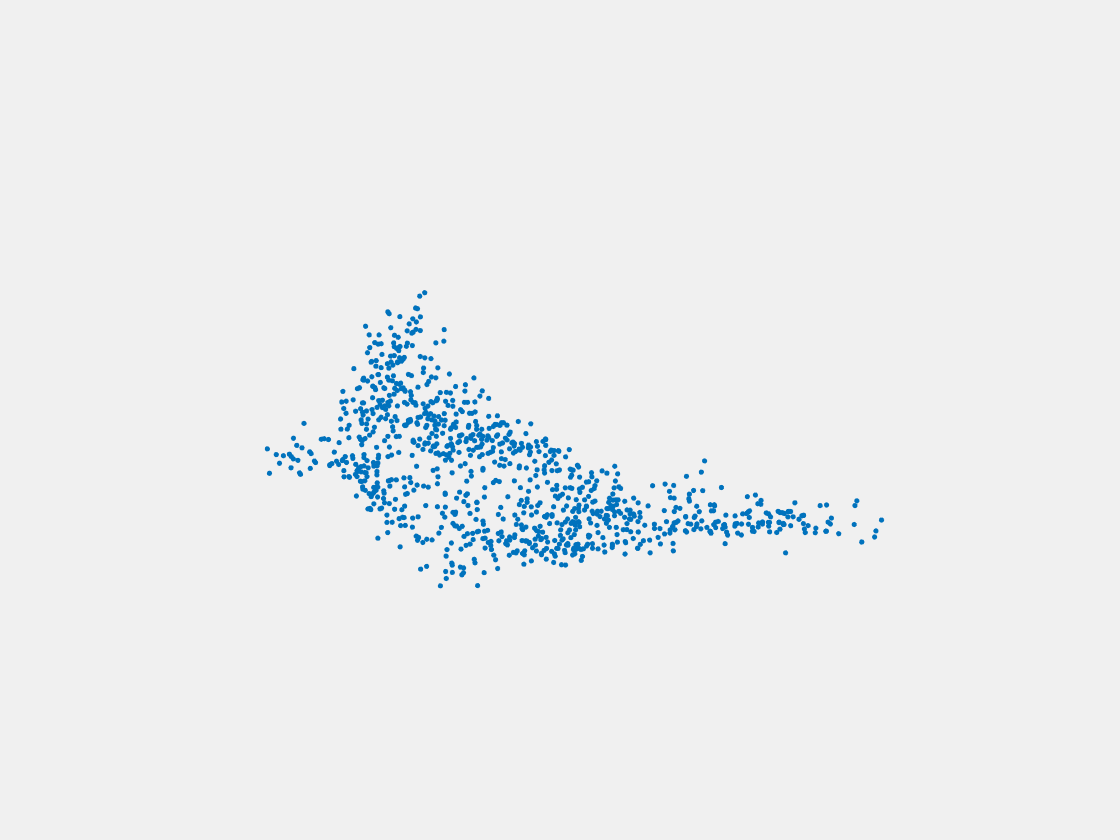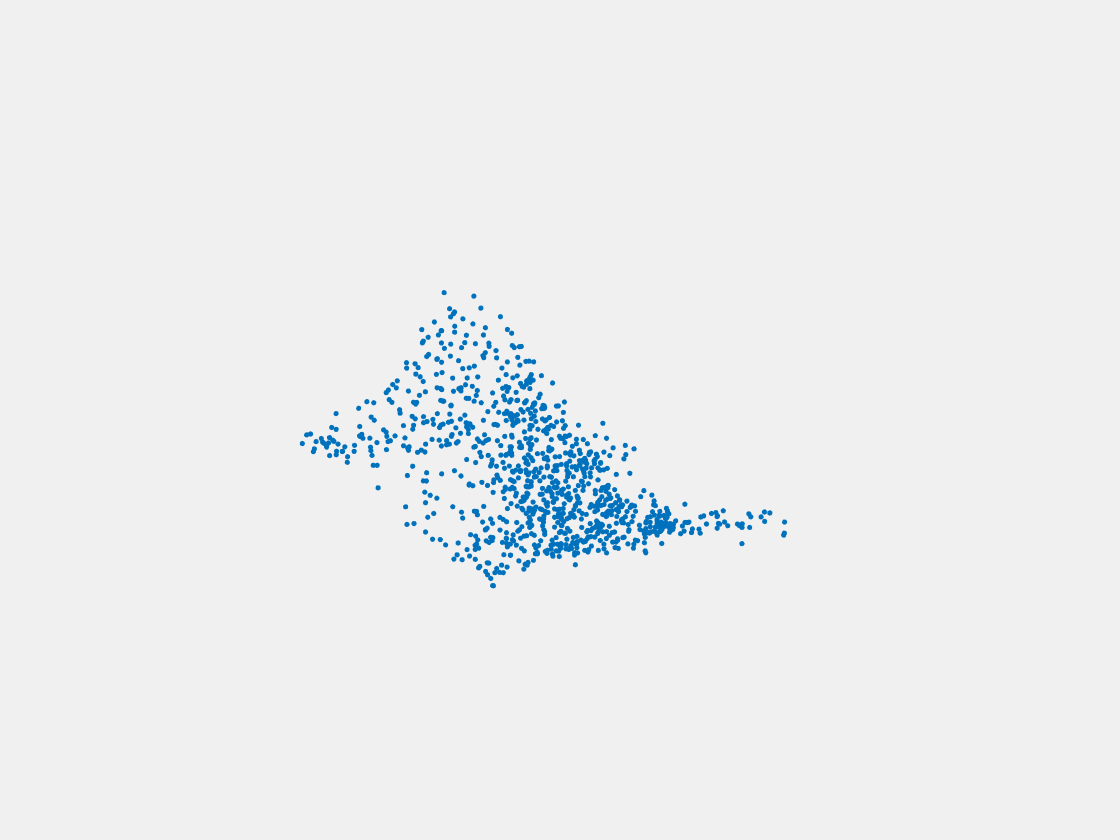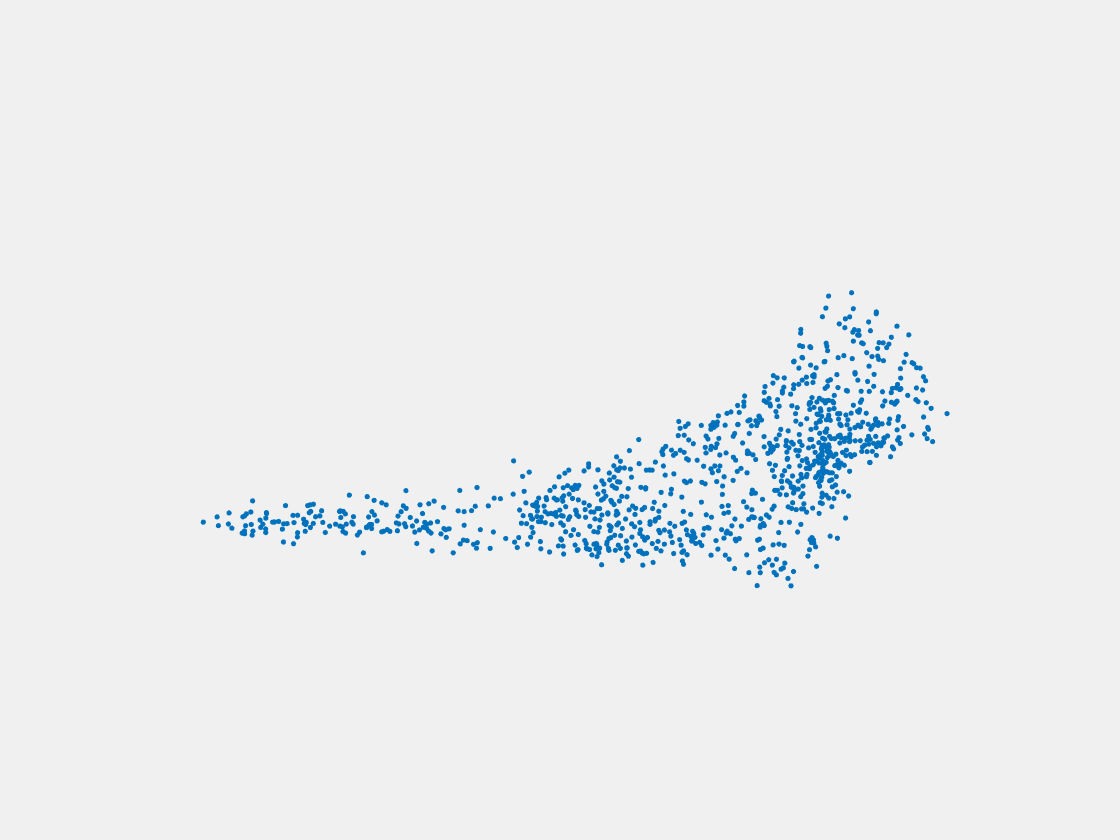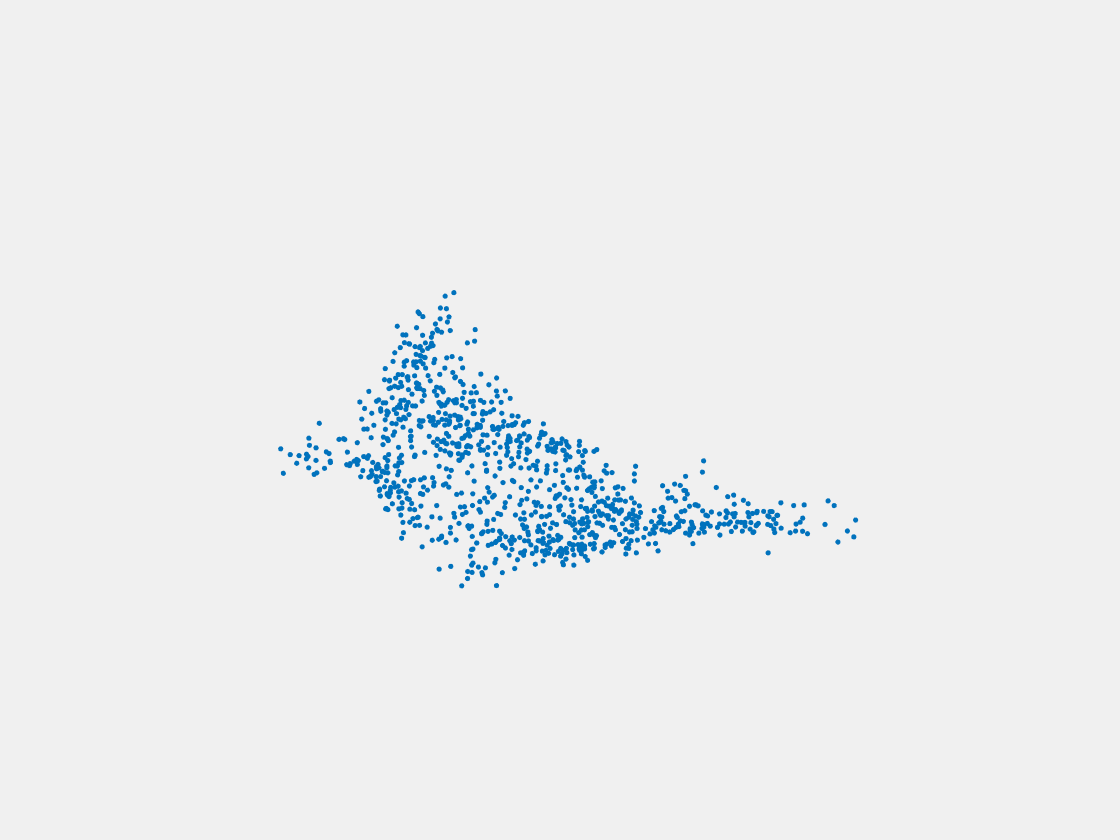



Figure 15: Point clouds of testing image generated by MuSullyNet_v2. Left to right, top to bottom: Pikachu, Farfetch’d, Dewgong, Gengar, Snorlax, and Mew.
First, compared to the results generated by simply fine tuning with PointSetNet, we can see that the results using our proposed MuSullyNet on training samples achieve as good as the results using fine tuning. Moreover, the results on testing samples with our proposed architecture, especially version 2, significantly outperform those using fine tuning. That may be because the model fine-tuned from the pretrained PointSetNet is overfitting and actually performs as a classifier such that, given 2D images, it predicts what model in the training set the object is and output that model. When testing samples that are not included in training set are considered, the fine-tuning method cannot really accommodate the multiple views to provide a good 3D point cloud. Instead, our proposed models can achieve this because our network can selectively update its prediction on 3D point clouds based on multiple images fed consecutively into the networks. In other words, thanks to the LSTM component included in our architechture, our model can truly leverage and aggregate the information come from all the 2D views for each 3D object. This is demostrated clearly in Figure 15. Compared to those incorrectly reconstructed huge rounded tails for Dewgong, Gengar and Snorlax in Figure 10, here in Figure 15, they appear to have their tails reconstructed correctly. For example, Dewgong now has a long curly tail, while Gengar and Snorlax have a small peaky tail and no tail at all respectively.
Furthermore, among the two architectures we proposed above, we can see that version 2 performs better than version 1. The reason is that, in the version 2 architecture, the hidden states of LSTM layer are also used for the predictor to reconstruct 3D point clouds. As the hidden states of LSTM are trained by taking multiple views into consideration, they are expected to capture the 3-dimensional common structure of the Pokemon underlying the given multiple 2D images. The outperformance of version 2 compared to version 1 demonstrates the importance to include hidden states of LSTM in predictor.
Potential Improvements
First, the results may be potentially improved by training the networks with different hyperparameter settings. Due to the time and computational resource constraints, we did not have a chance to exhaustively search over the parameter space.
Besides, based on our observations, one of the most challenging issues is due to the sparse nature of 3D point clouds, which makes backpropagation hard to track and perform. An idea we come out is to use some compact representations, rather than the raw point set, for the target output and ground truth 3D data. For example, we may use Octree to represent the data instead of point clouds and try OctNet [3] or O-CNN [4] to achieve better performance.
Finally, we also recognize another challenge as the ambiguity caused by different viewing angles, which aggravates the difficulty in estimating loss between reconstructed and ground truth 3D point clouds. Since the loss function that is adpoted in literature and our current models, i.e., Chamfer Distance (CD), does not have rotational invariance, it may not be able to accurately measure the difference between reconstruction and ground truth. For example, the CD metric between a 3D point set and its rotated copy may not be 0. We have come up with a rough idea regarding a framework to simultaneously train a network with synthetic data to learn the optimal rotation and translation invariant loss function and train another network to perform 3D reconstruction from multiview images based on the learned loss function. We expect that incorporating this framework could potentially enhance our model performance, due to the improvement on robustness and accurateness of loss metric.
Reference
[1] H. Fan, H. Su, and L. Guibas, A Point Set Generation Network for 3D Object Reconstruction from a Single Image
[2] C. B. Choy, D. Xu, J. Gwak, K. Chen, and S. Savarese, 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction
[3] G. Riegler, A. O. Ulusoy, A. Geiger, OctNet: Learning Deep 3D Representations at High Resolutions
[4] P.-S. Wang,Y. Liu, Y.-X. Guo, C.-Y. Sun, X. Tong, O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis